




 文章介绍了N-gram语言模型的理论基础,包括马尔可夫假设和词频计算。通过Python代码展示了如何构建语料库、计算N-gram词频、估计概率以及生成连续文本。这种方法虽然简单,但受限于长距离词汇关系的捕捉和语料库的丰富程度。
文章介绍了N-gram语言模型的理论基础,包括马尔可夫假设和词频计算。通过Python代码展示了如何构建语料库、计算N-gram词频、估计概率以及生成连续文本。这种方法虽然简单,但受限于长距离词汇关系的捕捉和语料库的丰富程度。
一. 理论基础
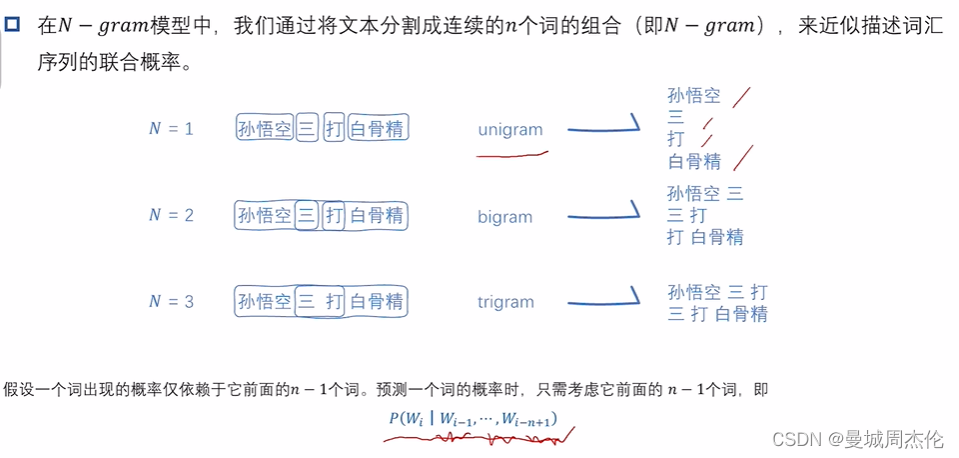
定义: 语言模型在wiki的定义是统计式的语言模型是一个几率分布,给定一个长度为 m 的字词所组成的字串 W1 , W2 ,··· ,Wn ,派几率的字符串P(S) = P(W1 , W2 ,··· ,Wn , )而其中由条件概率公式我们可以得到下图2的公式,然后我们再利用马尔可夫假设(每个词的出现的概率只与前面那个词有关) 得到下面的公式3

而N-gram的意思,就是每个词出现的概率只取决于前面n - 1个单词的,其中单词的概念可以是词组也可以是字,比如下图中的孙悟空这种单独拆开词无意义的可以看作一个单词。举个例子比如说是2-gram, 我们看到孙悟空这个词需要去预测下一个单词是三,我们看到三需要预测下一个单词是打。所以这种模型的输出完全取决于语料库的概念
优缺点:
- 优点
- 计算简单
- 缺点
- 无法捕捉长距离的词汇关系
- 完全取决于语料库的丰富程度
- 没有考虑词之间的相似度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 147
147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











