




1、shuffle 原理
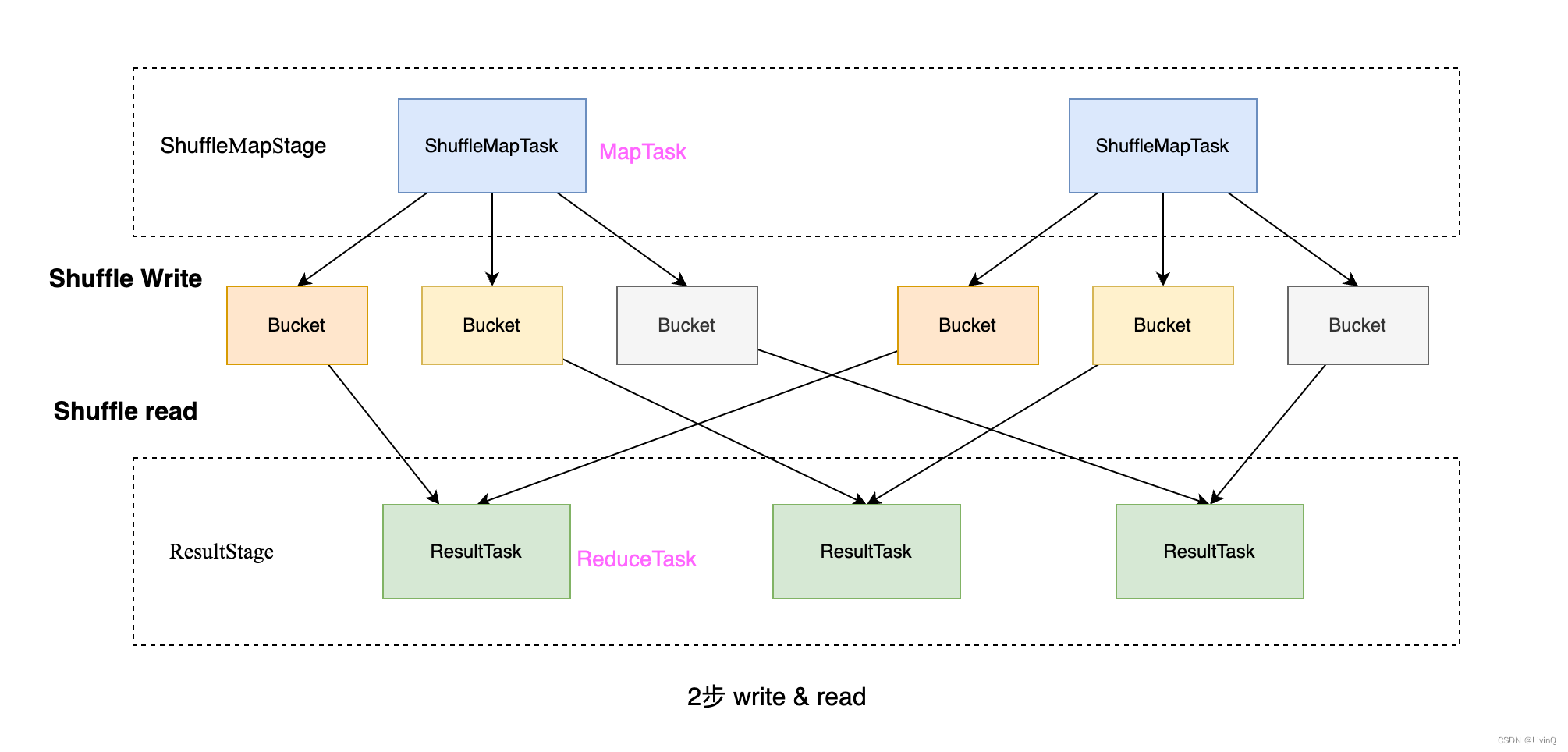
shuffle很昂贵
- 序列化 cpu
- 跨节点 网络IO
- 磁盘读写 文件IO
shuffle 操作
- repartition
- *ByKey()
- join & cogroup
2、shuffle介绍
Hash Shuffle V1
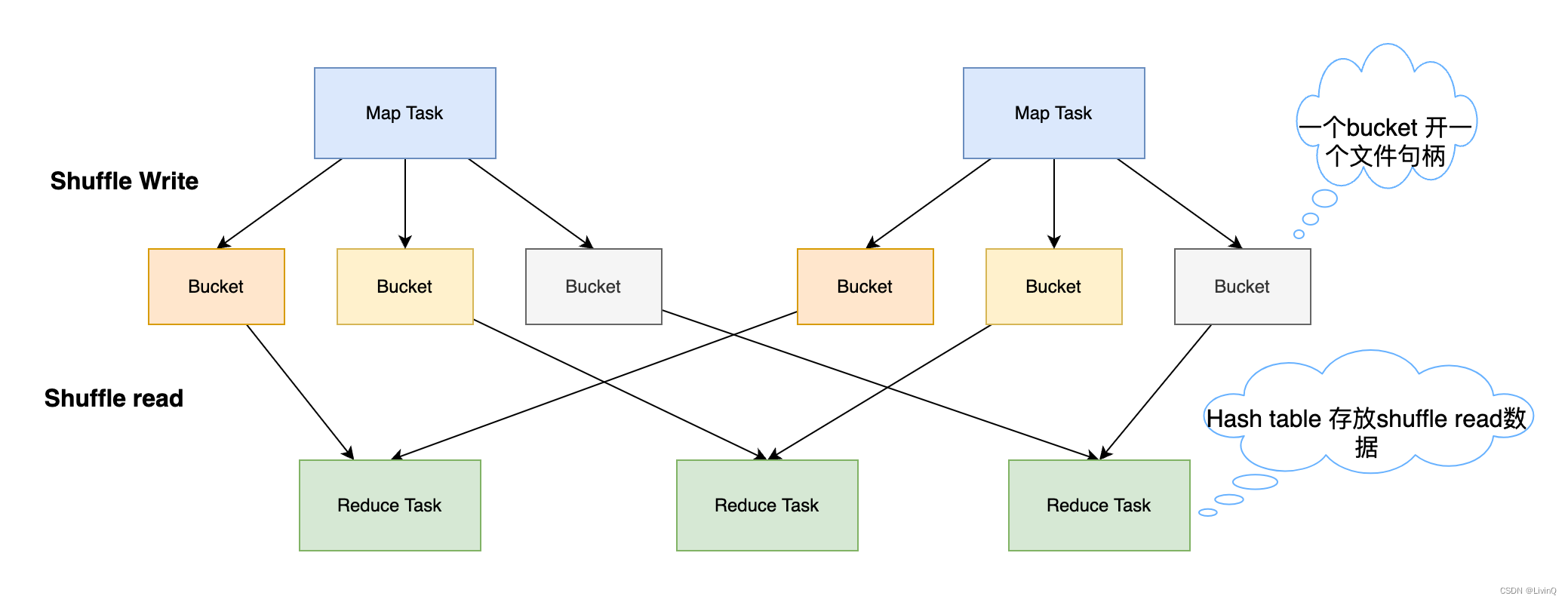
缺点:
- 一个MapTask对应 R 个bucket,会产生巨量文件(M * R)
- reduce端使用hashtable存放ShuffleRead的数据,容易OOM
Hash Shuffle V2
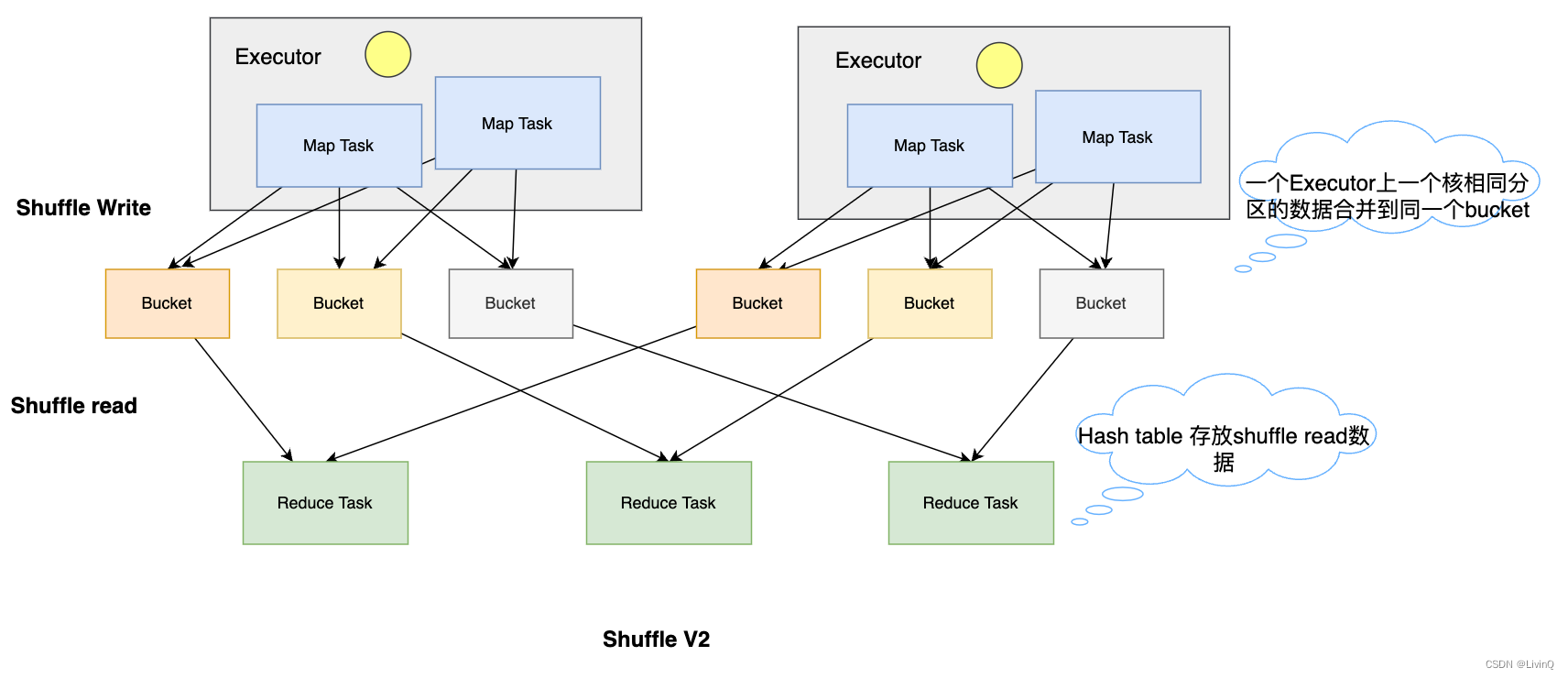
缺点:
- 一个 Executor 对应 R 个 bucket (E * R) (R很大时,治标不治本)
- reduce端使用hashtable存放ShuffleRead的数据,容易OOM
Sort Shuffle
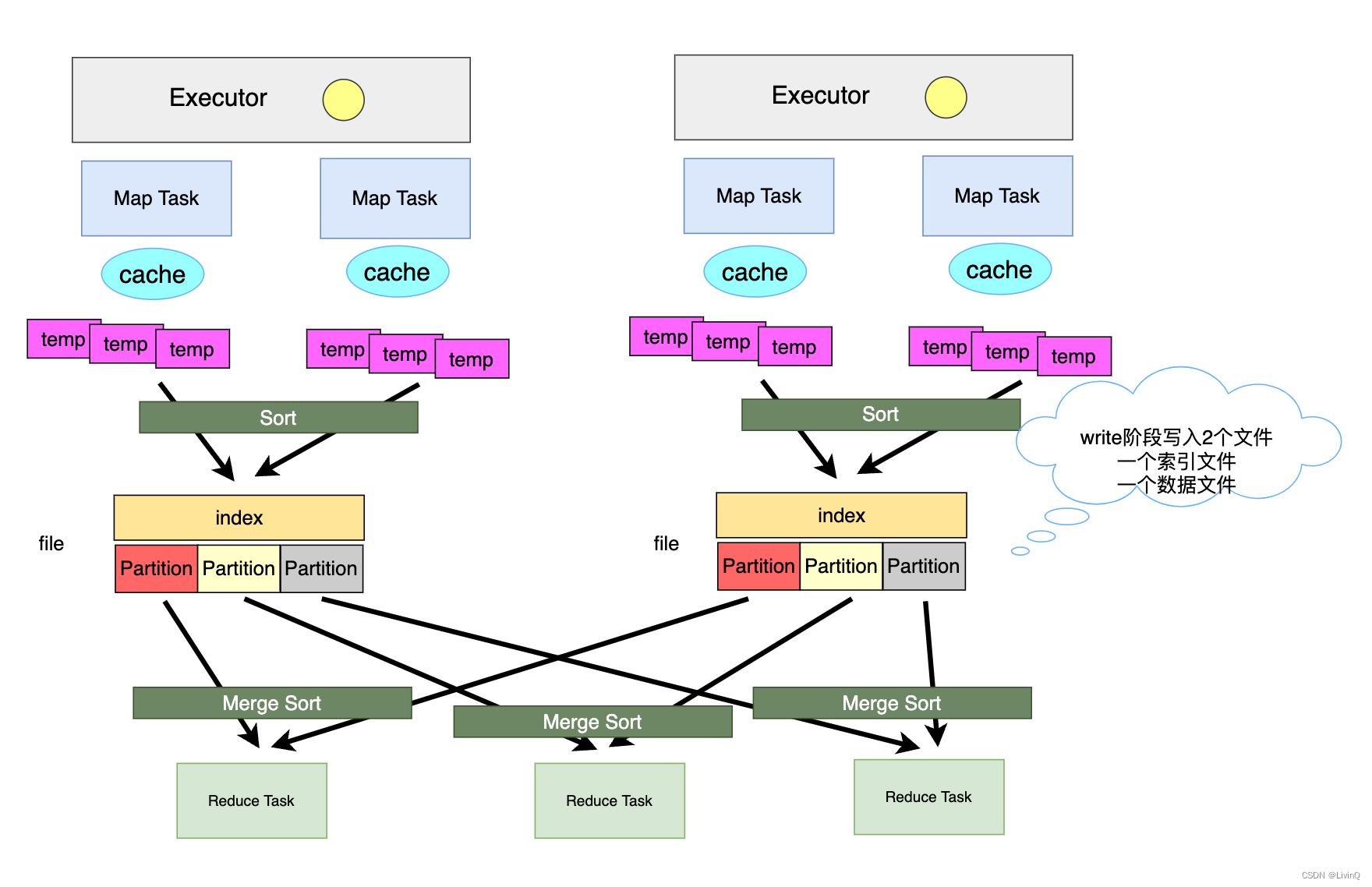
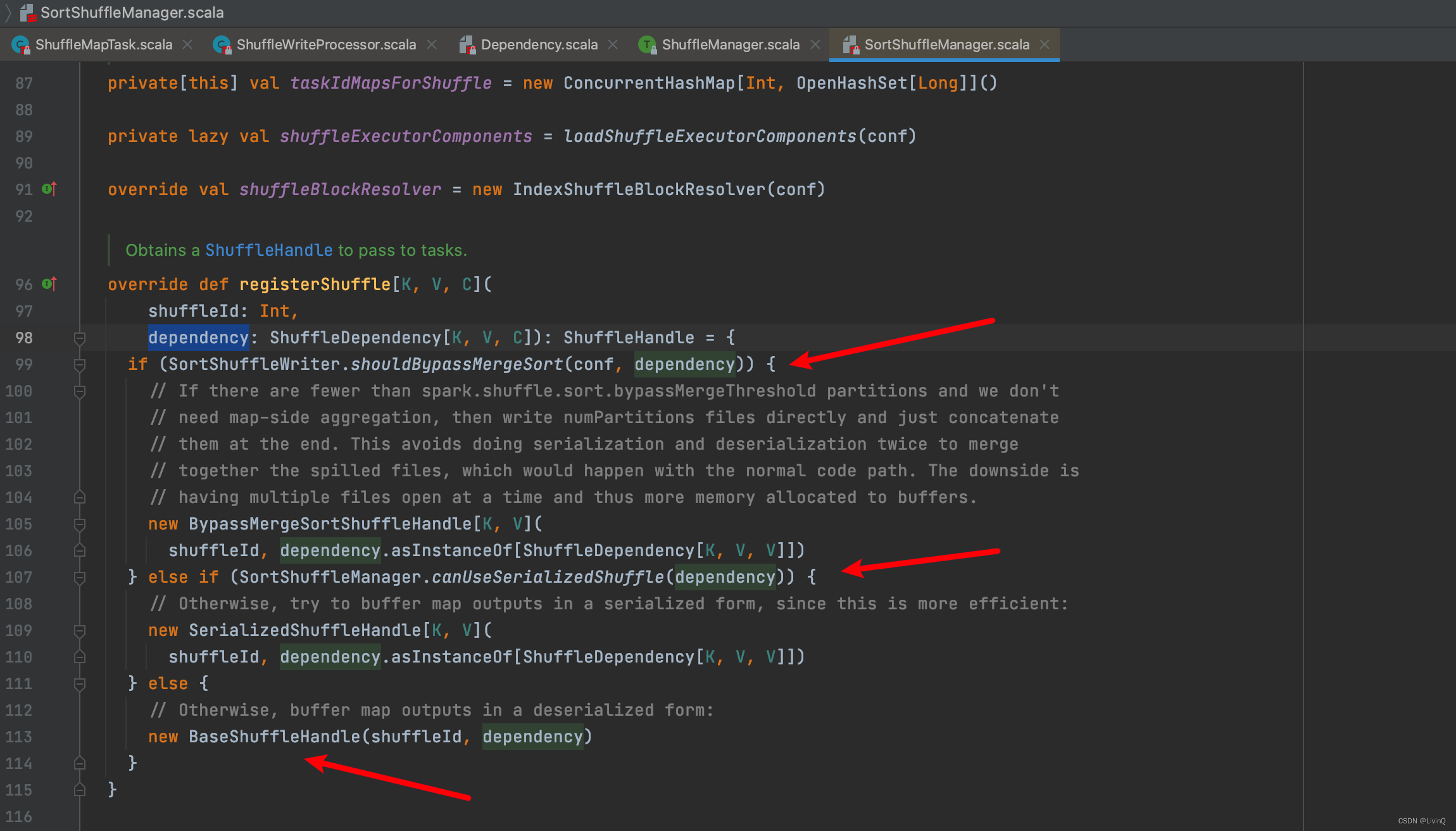
Bypass Shuffle
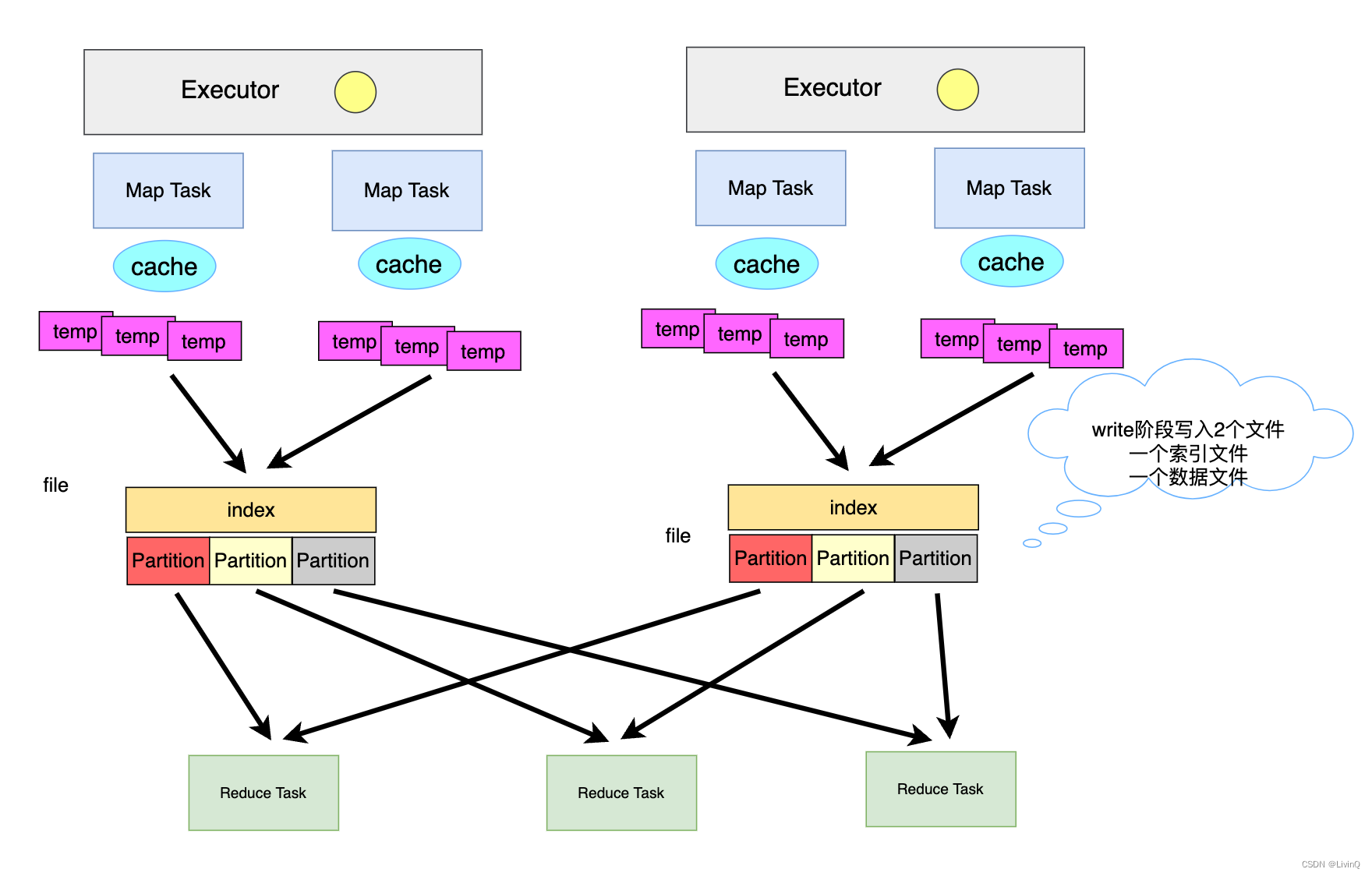
* bypass 和 普通 sort shuffle的区别在于:不会进行排序。省去了这部分的性能开销
触发bypass的条件:
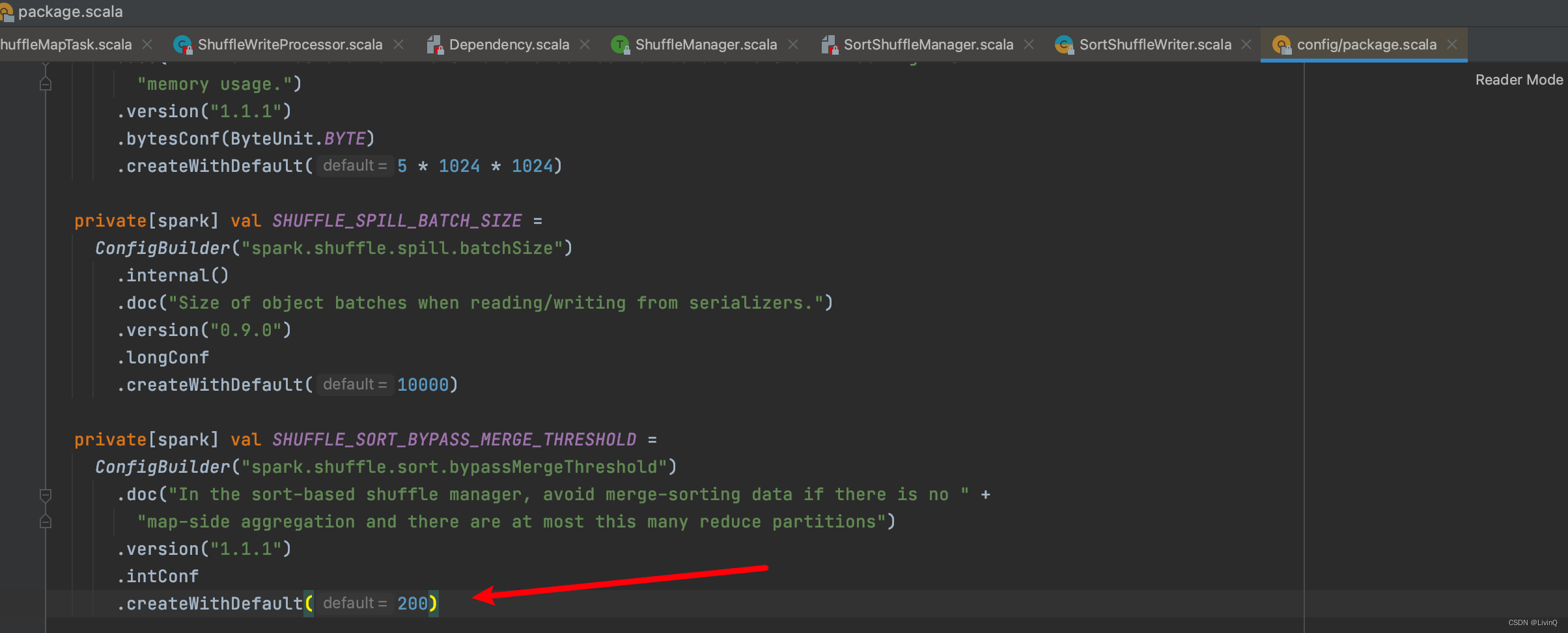
- shuffle reduce task < spark.shuffle.sort.bypassMergeThreshold (默认为200)。
- 不是聚合类的shuffle算子 (因为不排序,所以没有做预聚合的操作)
3、粗看源码
MapTask
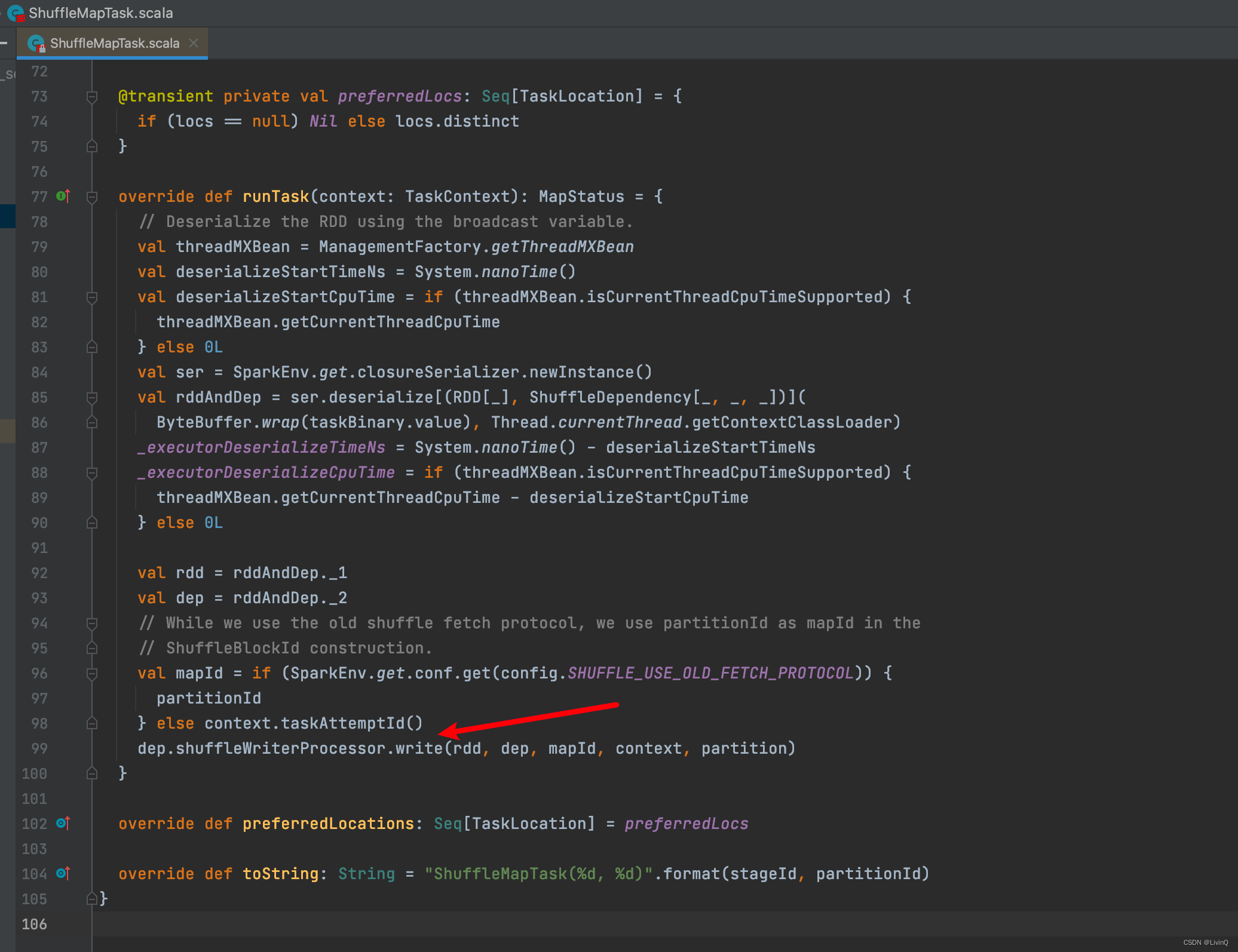
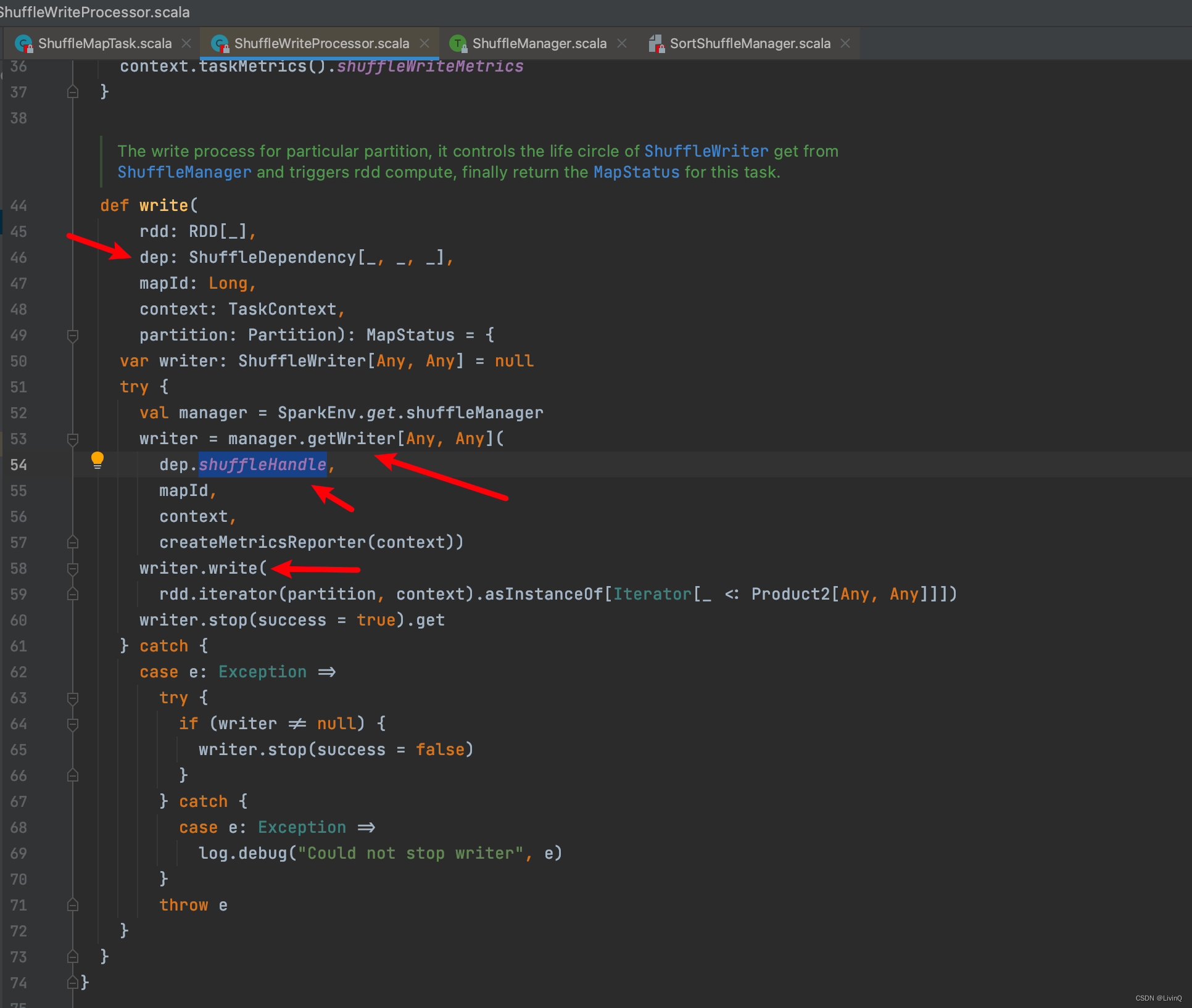
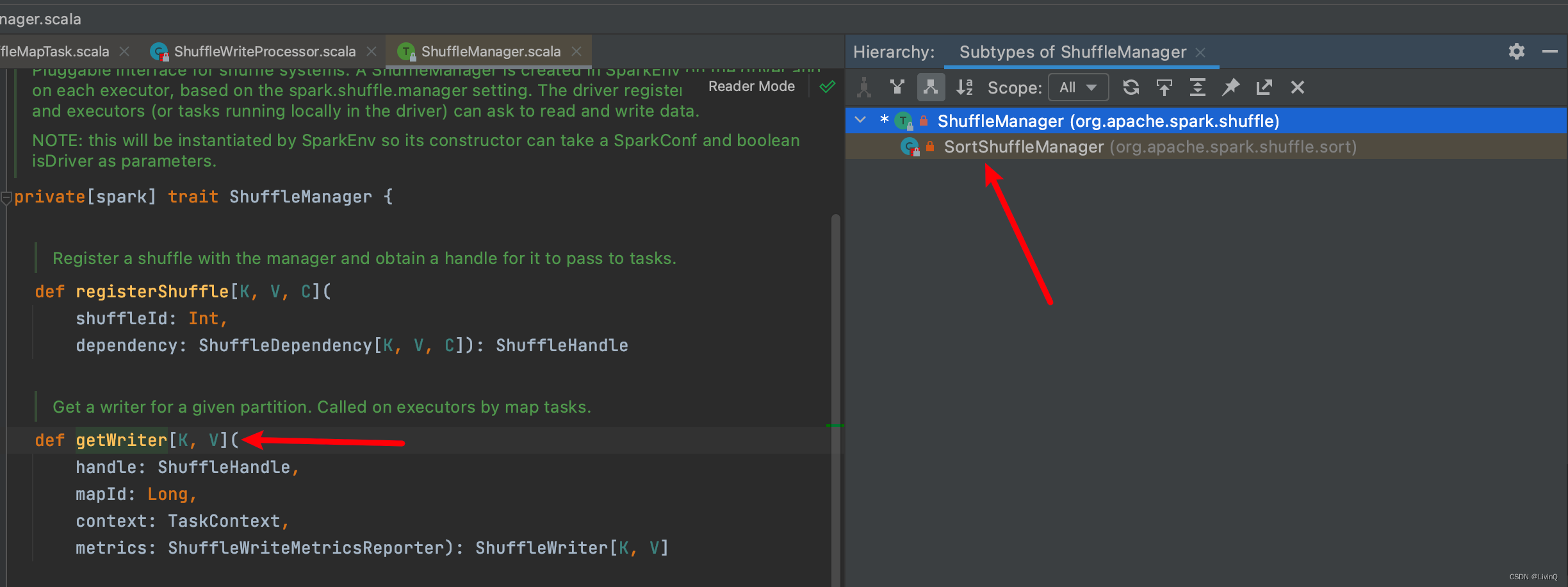
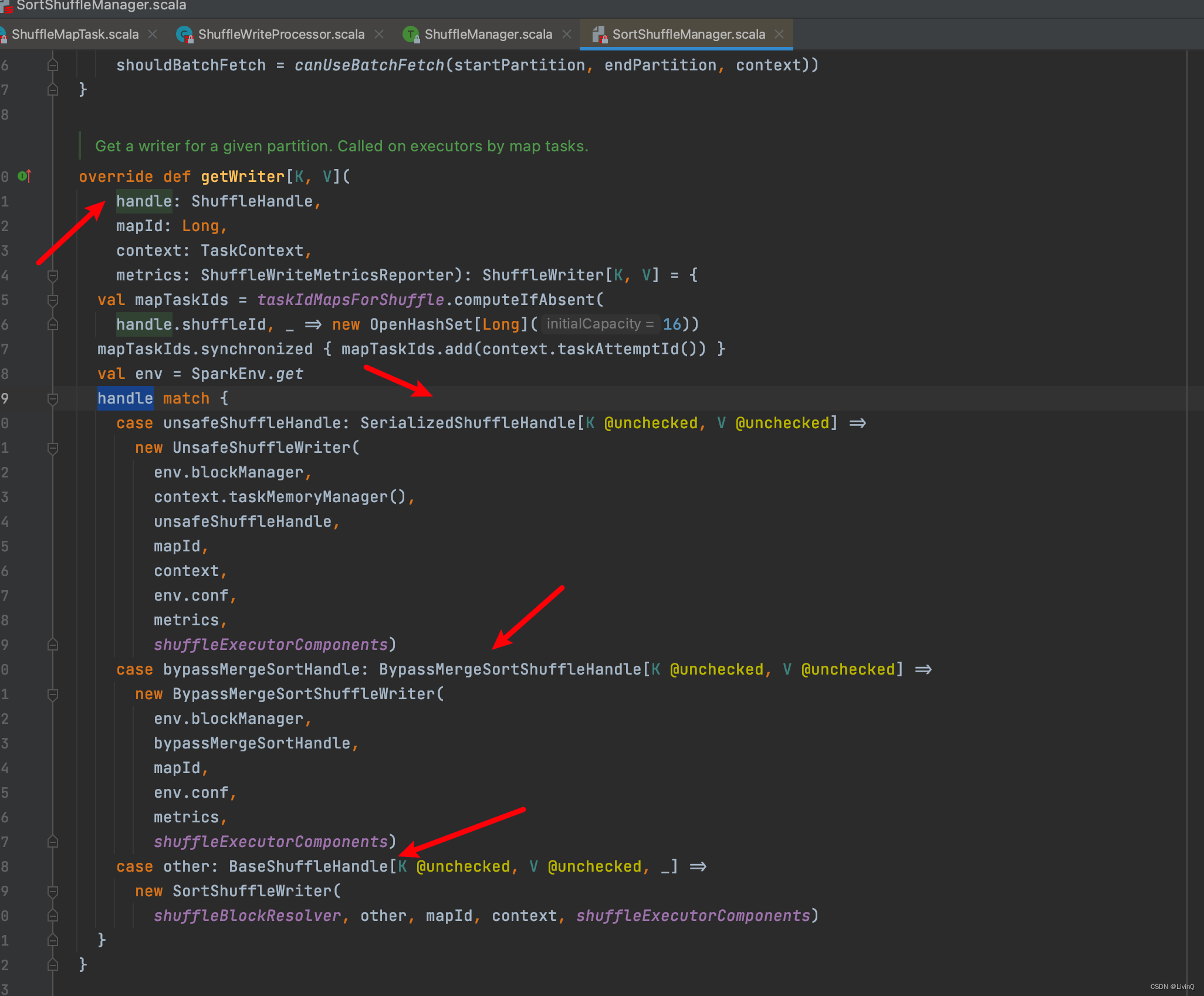
Handle
BypassMergeSortShuffleHandle 触发条件 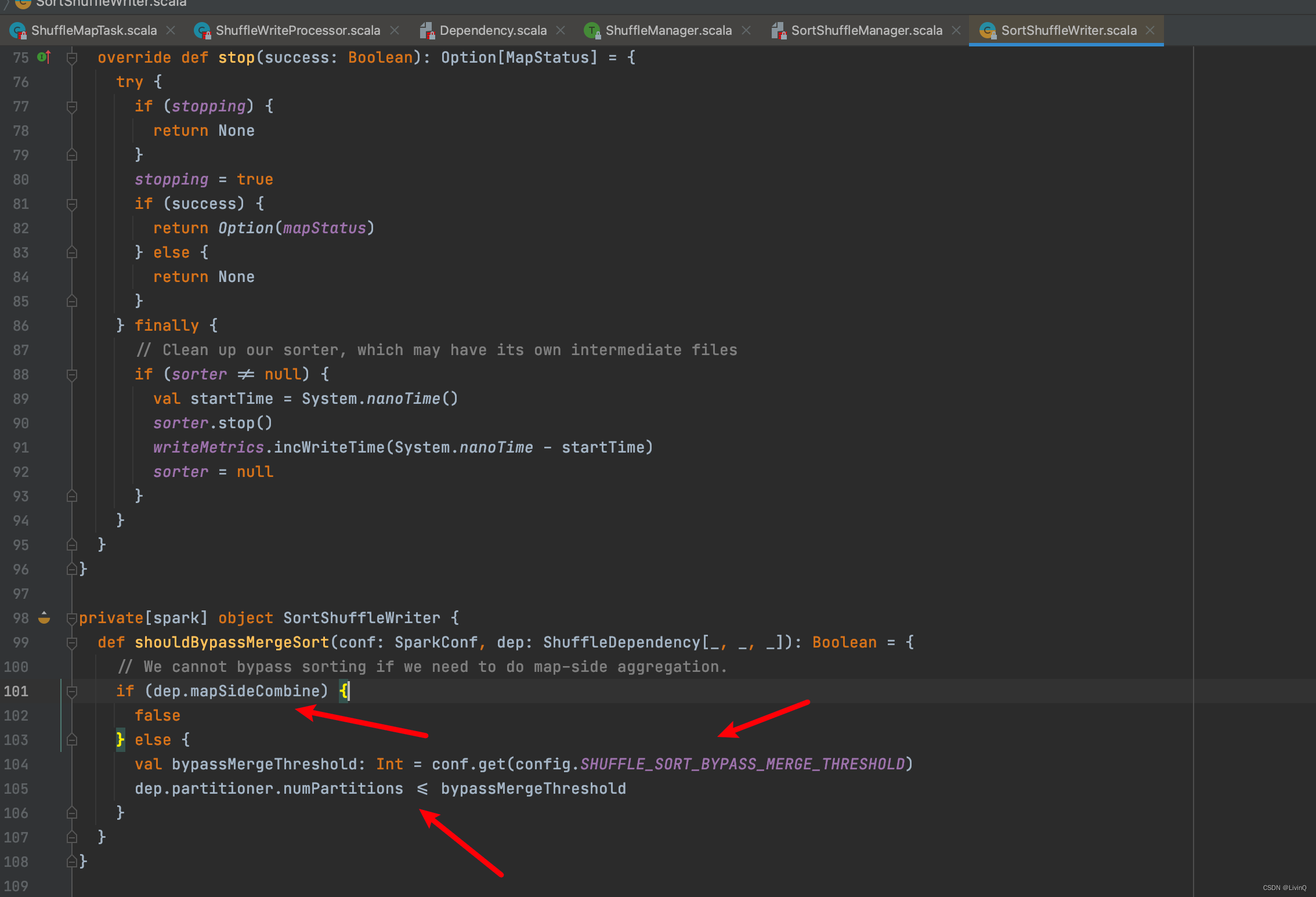
 SerializedShuffleHandle 触发条件
SerializedShuffleHandle 触发条件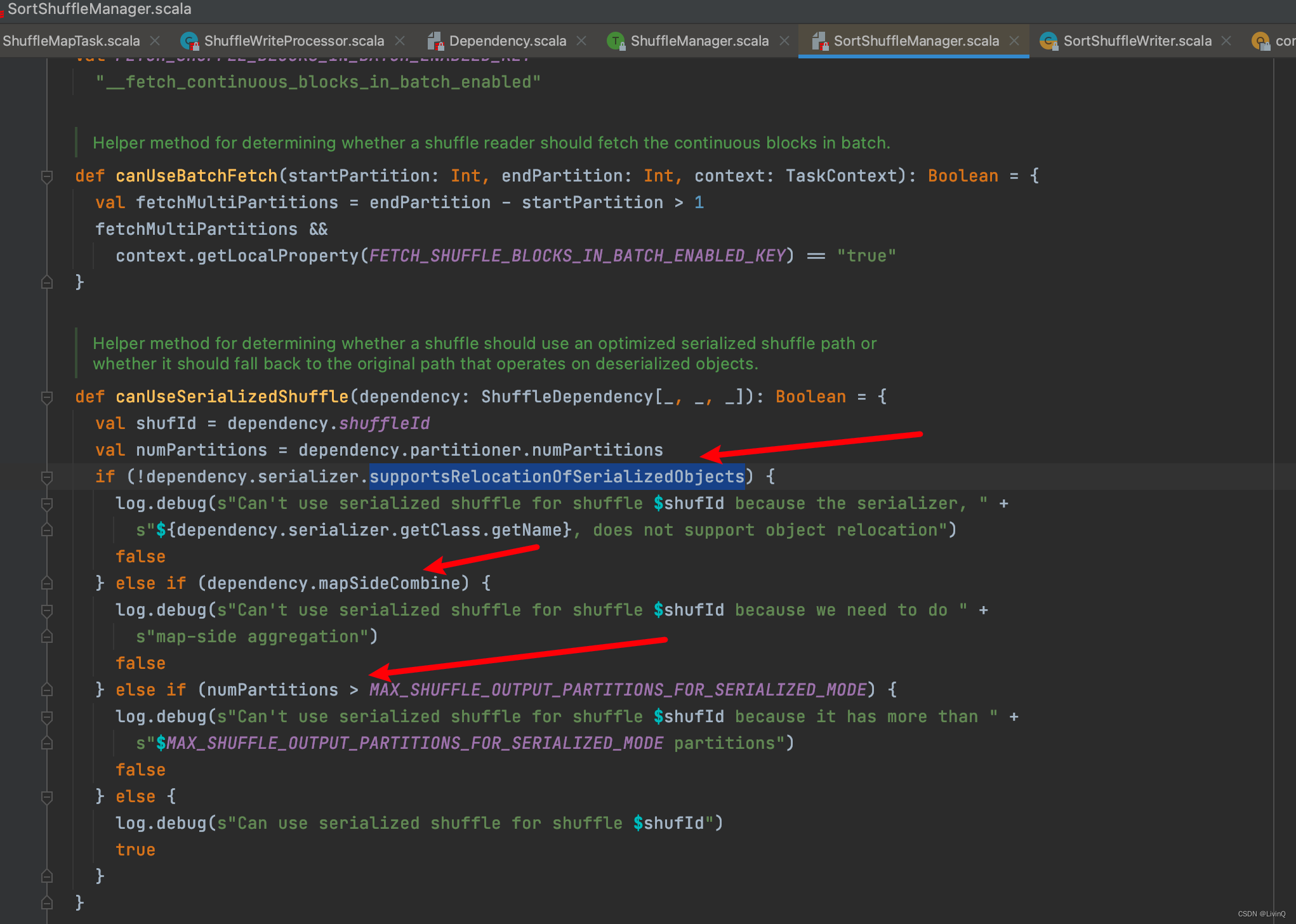

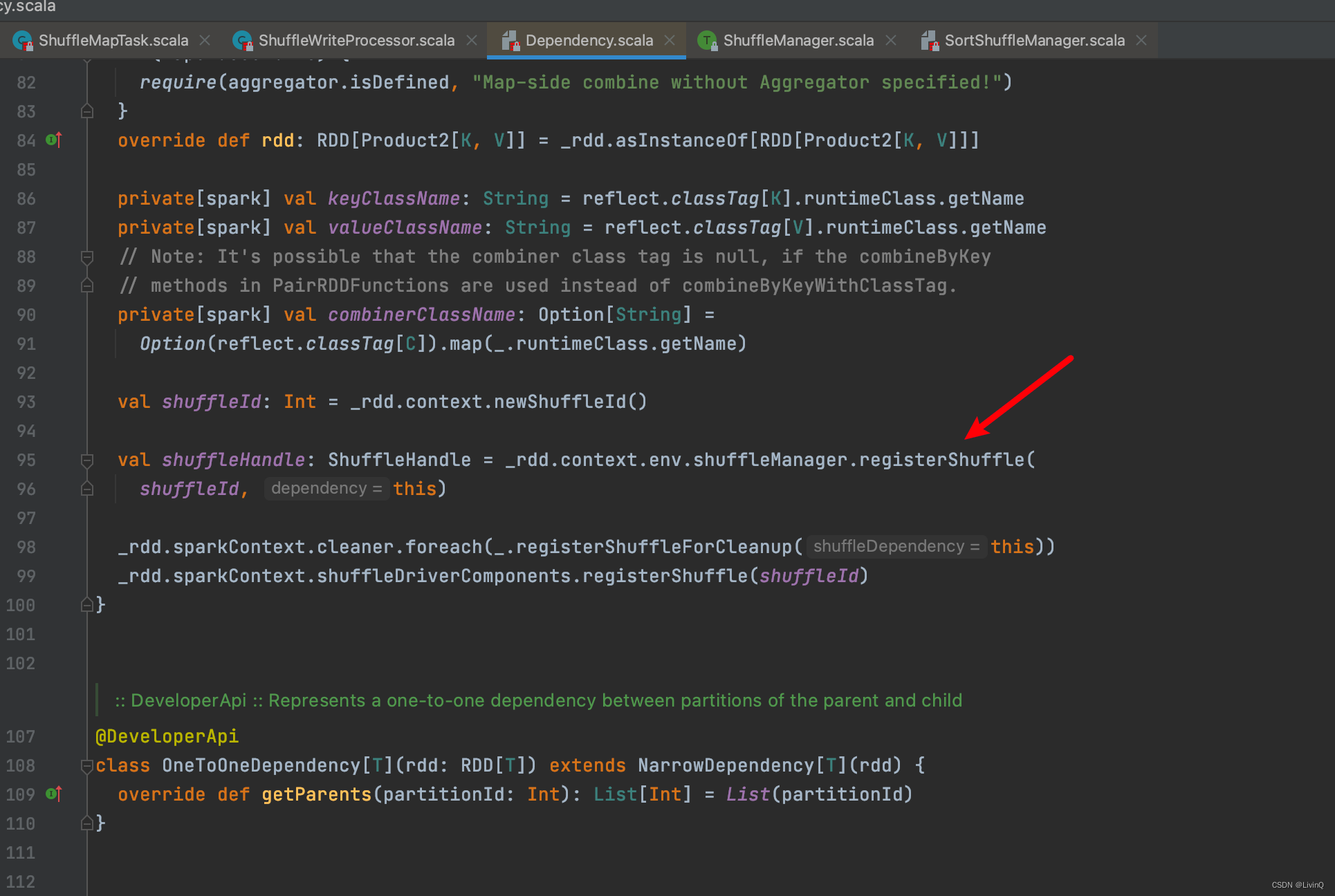
SortShuffleWriter 追踪
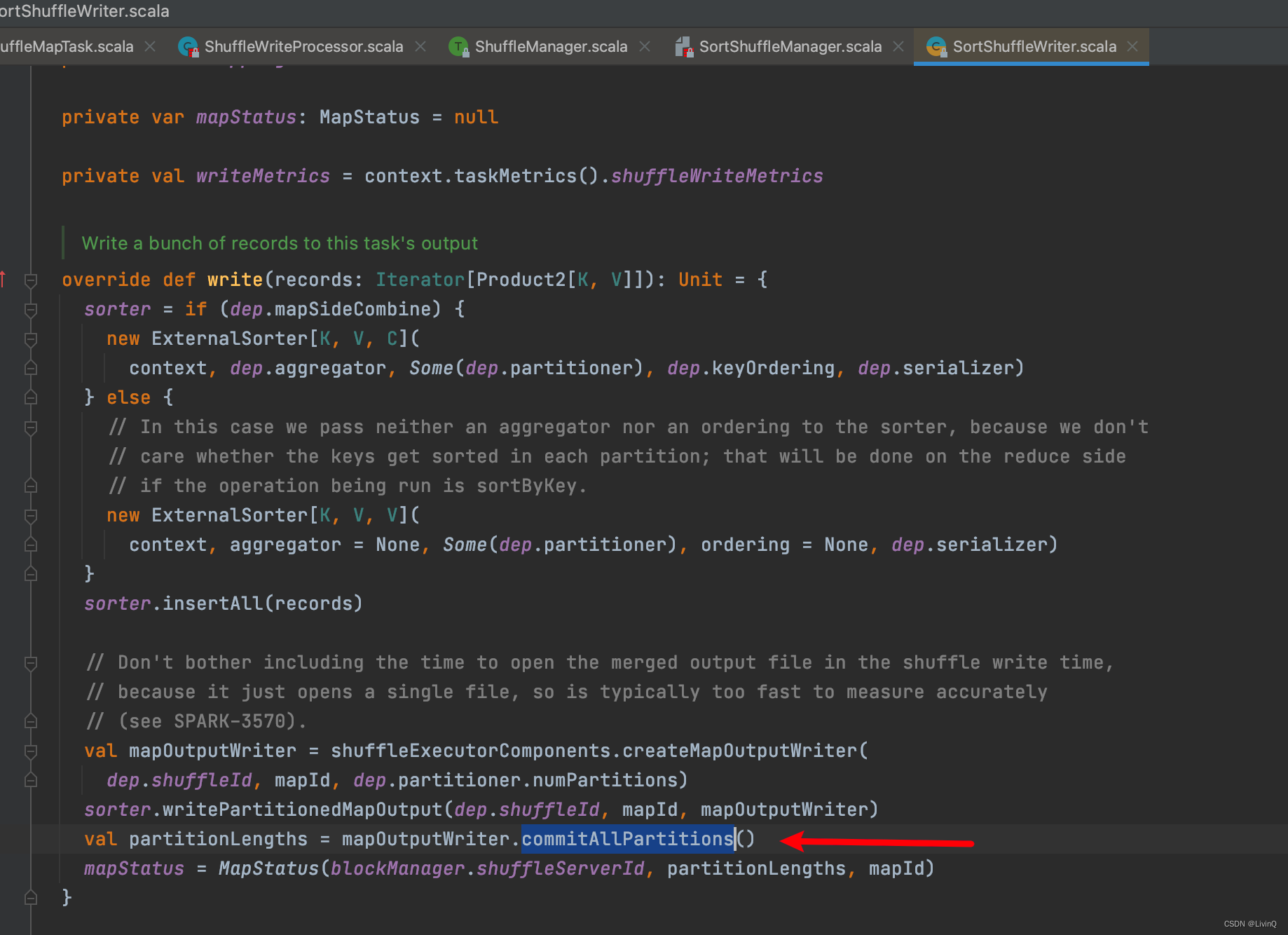
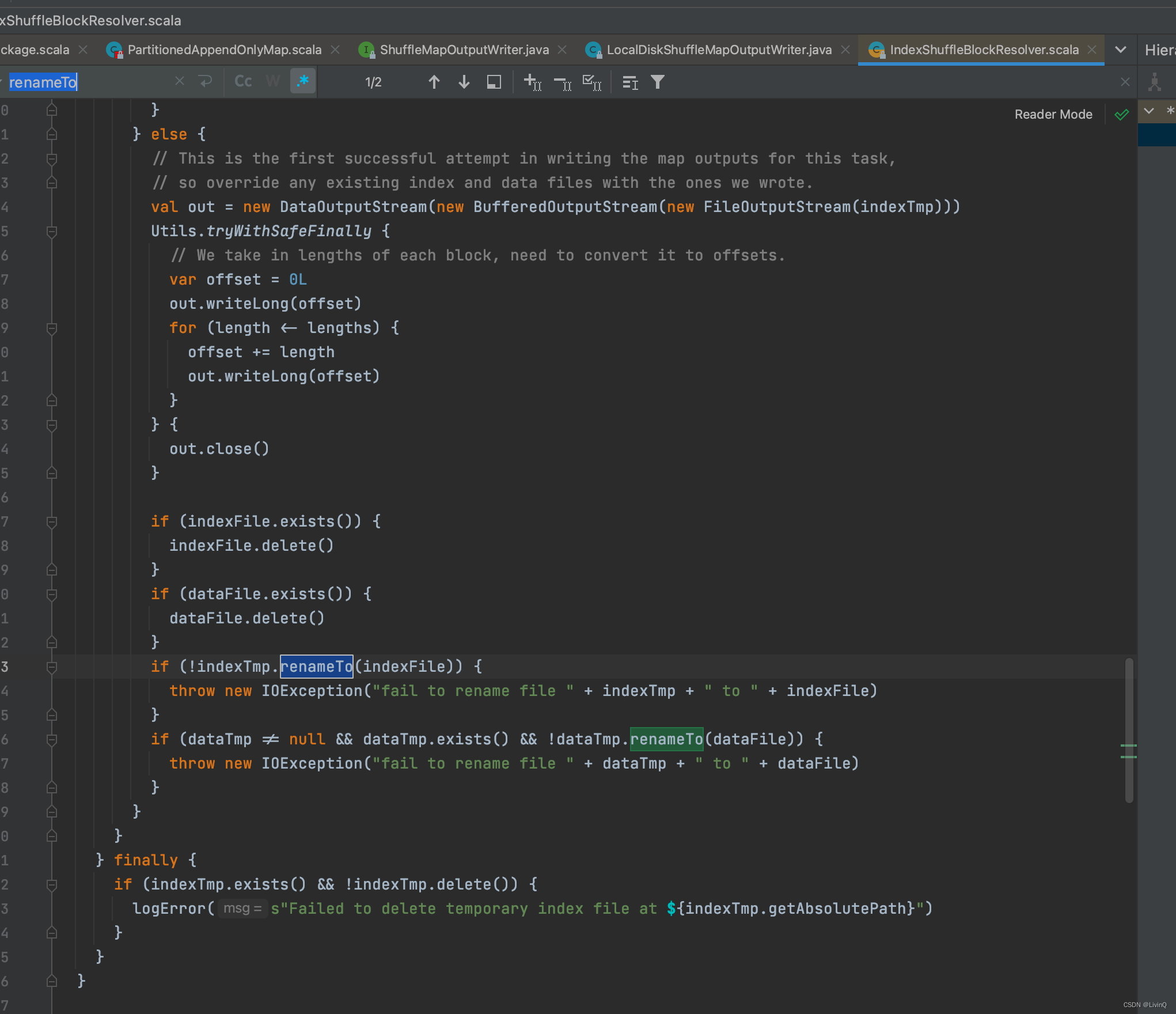
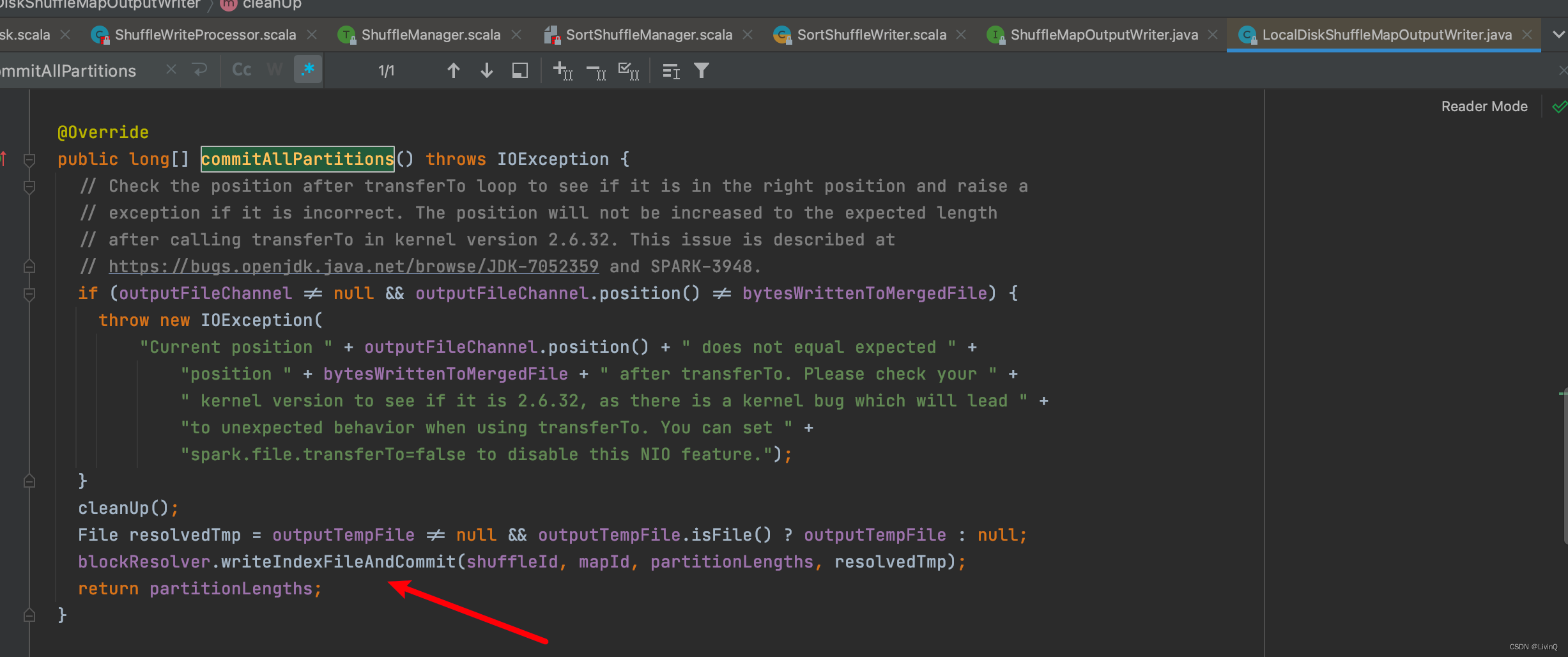 得到索引和数据文件
得到索引和数据文件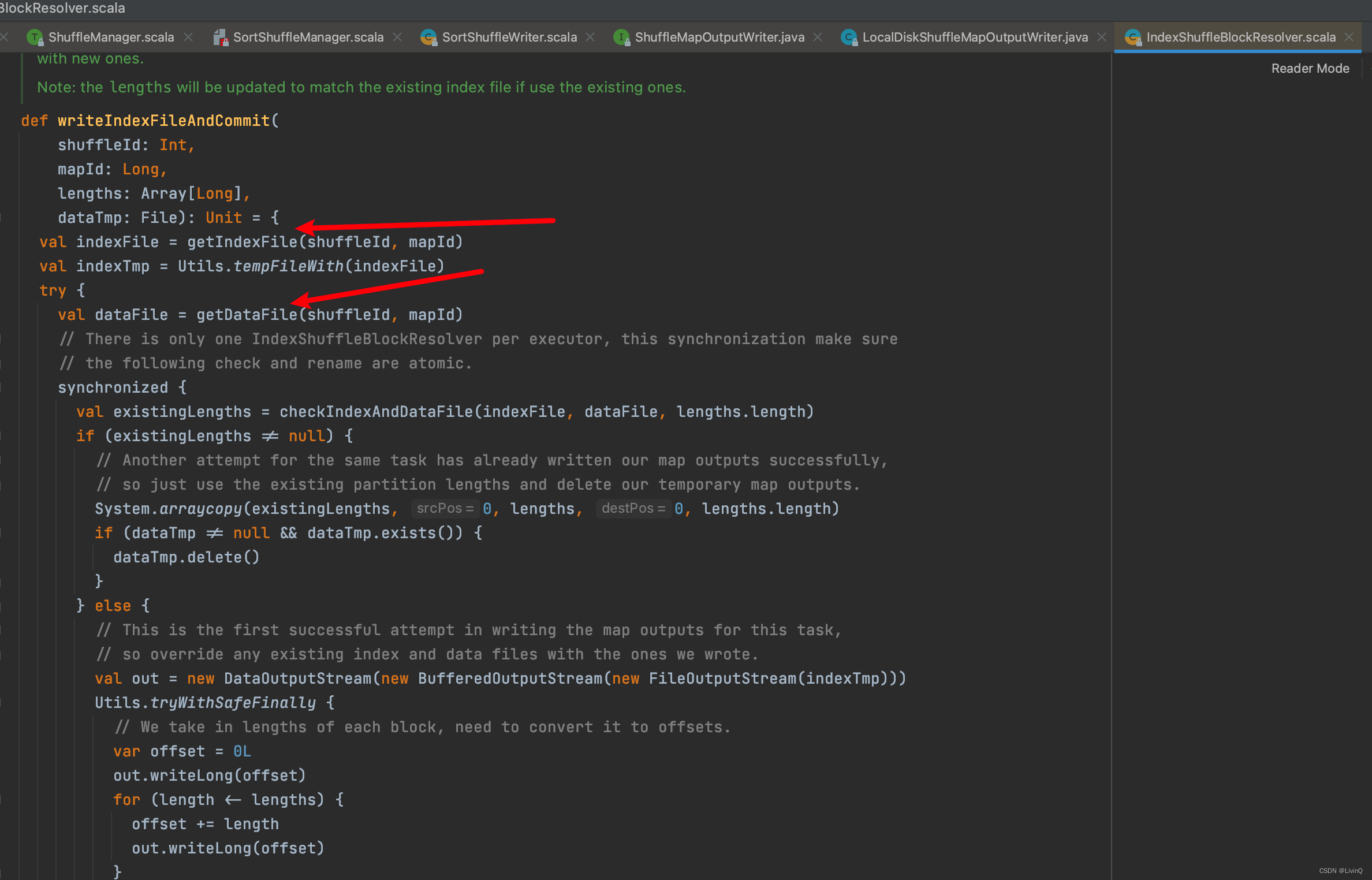
排序
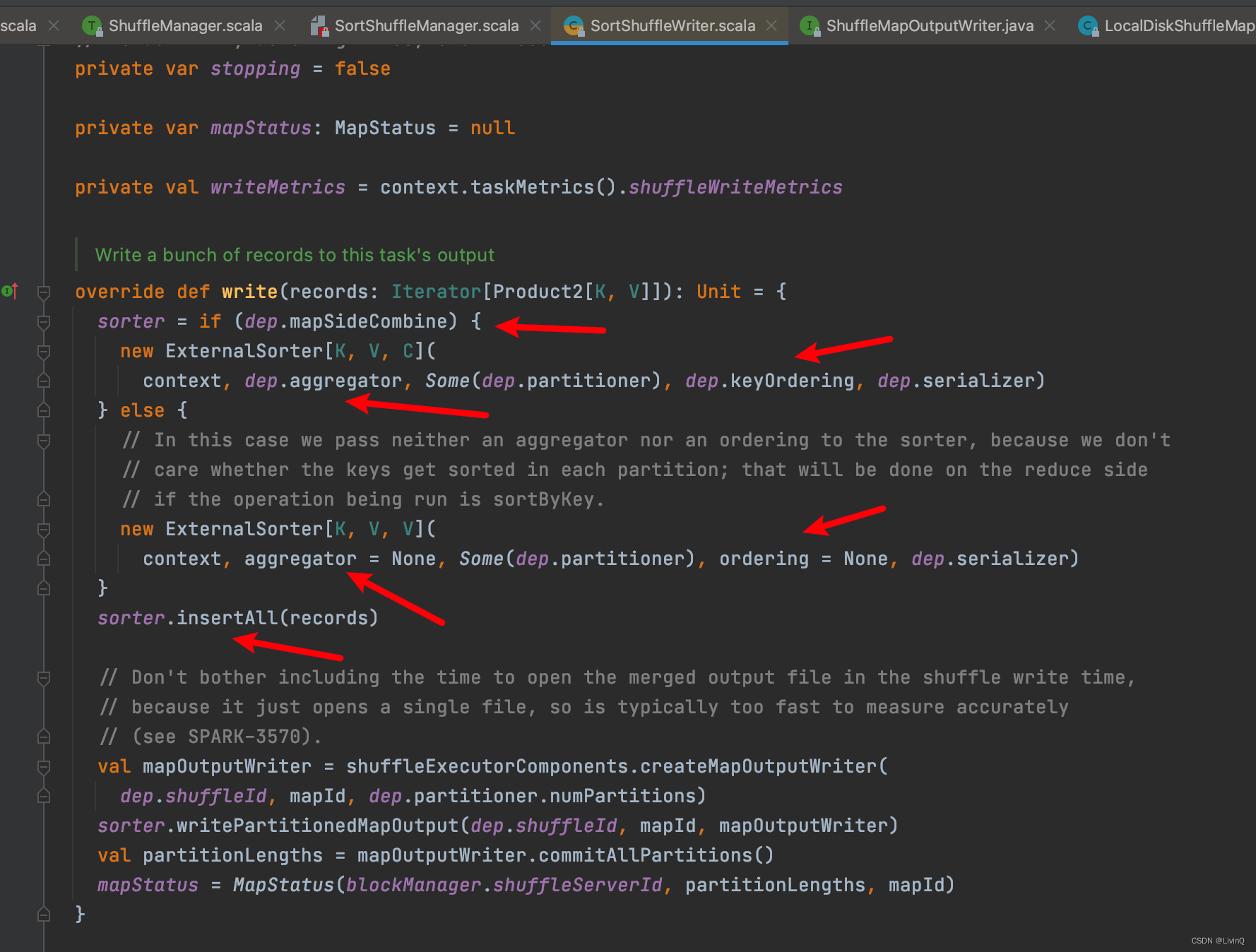
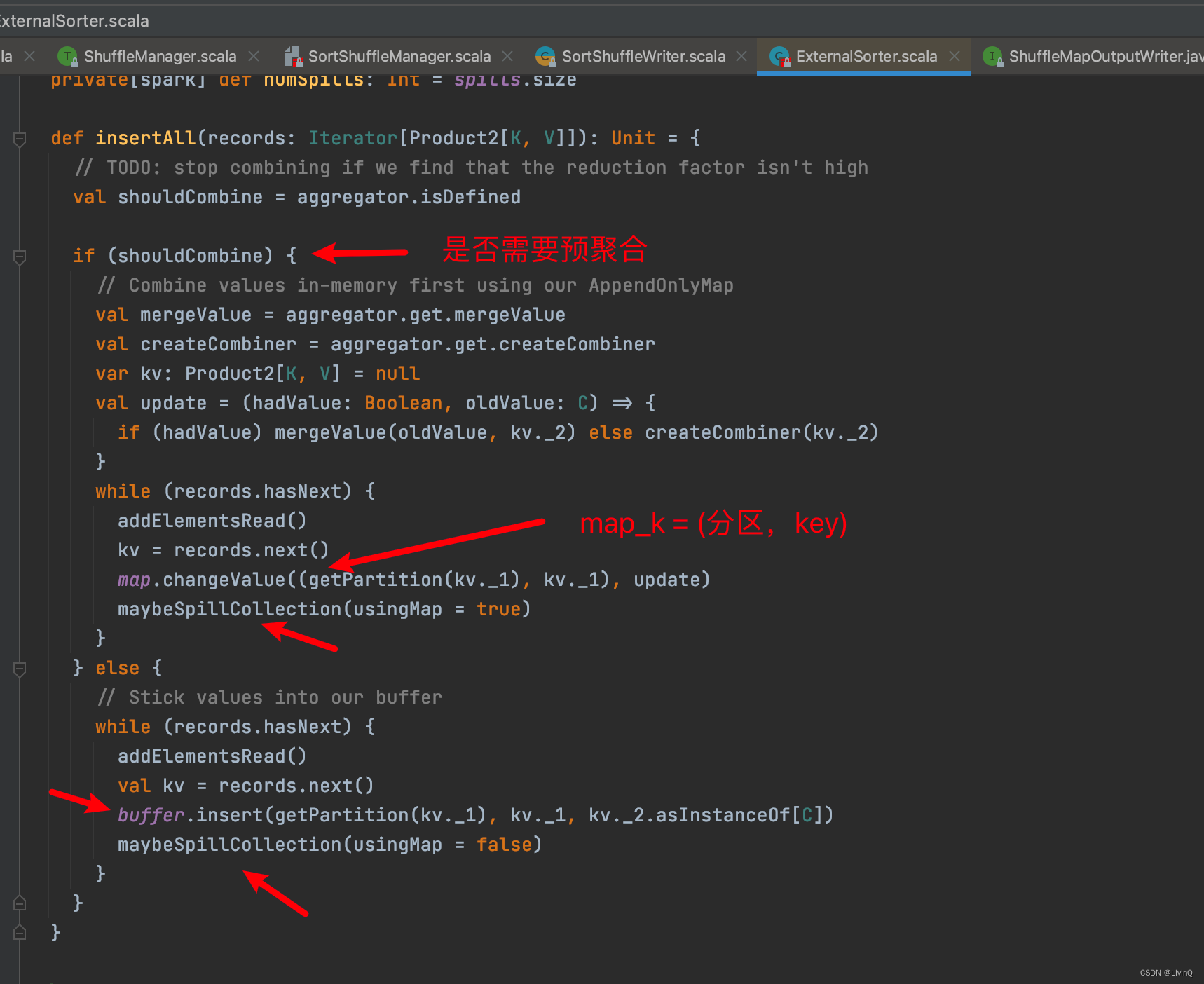
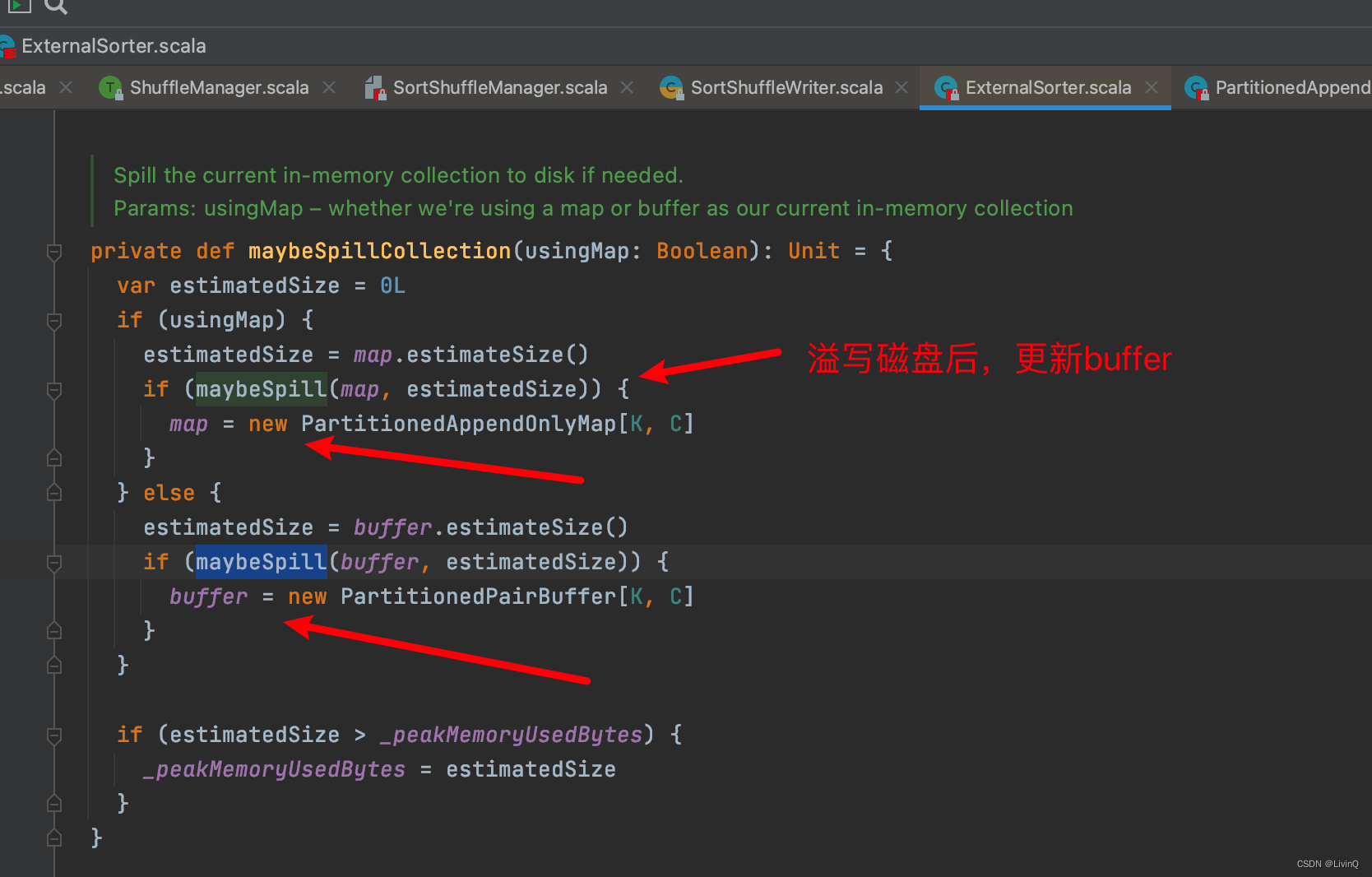
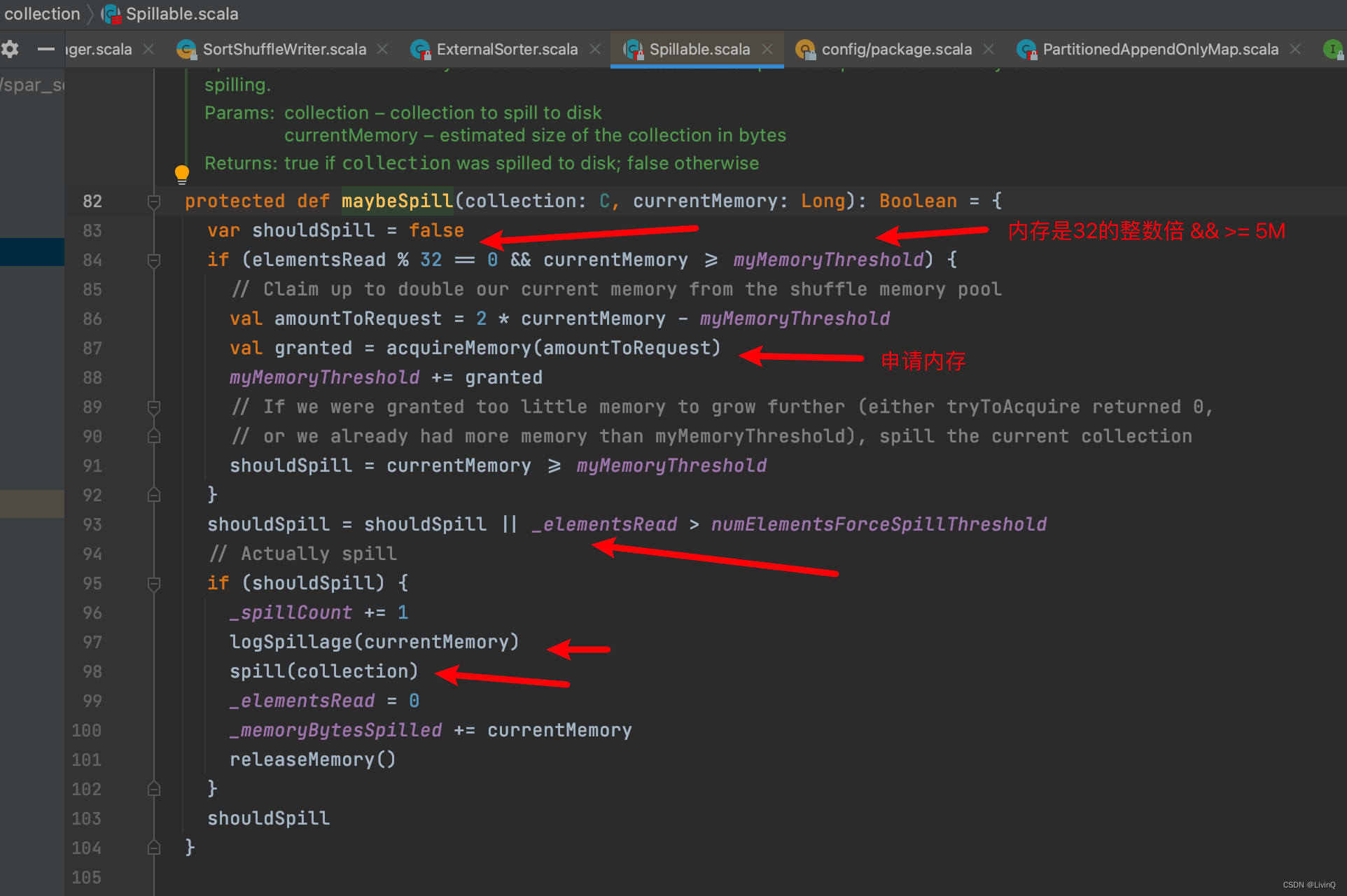
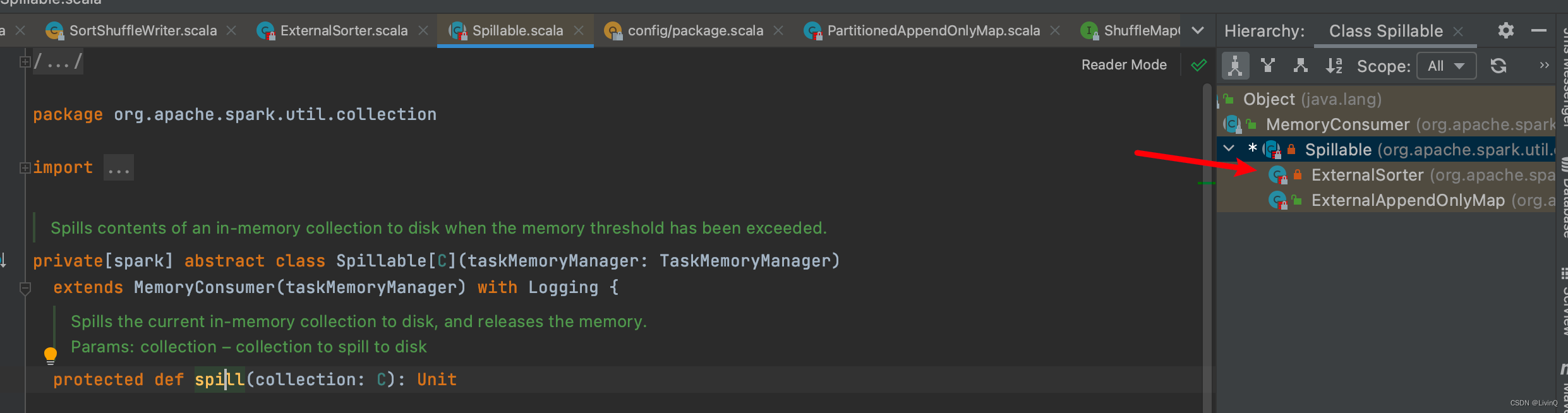

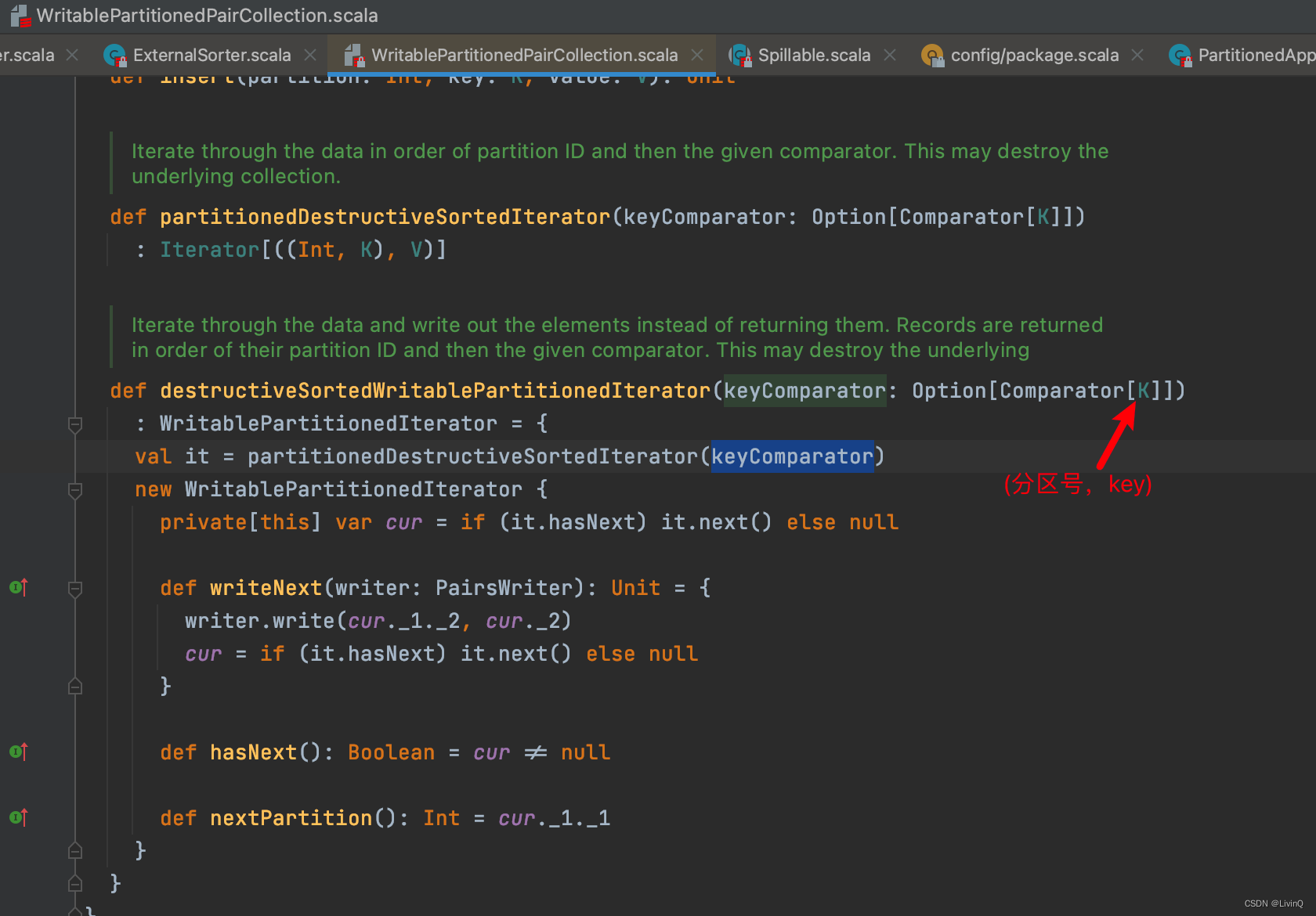
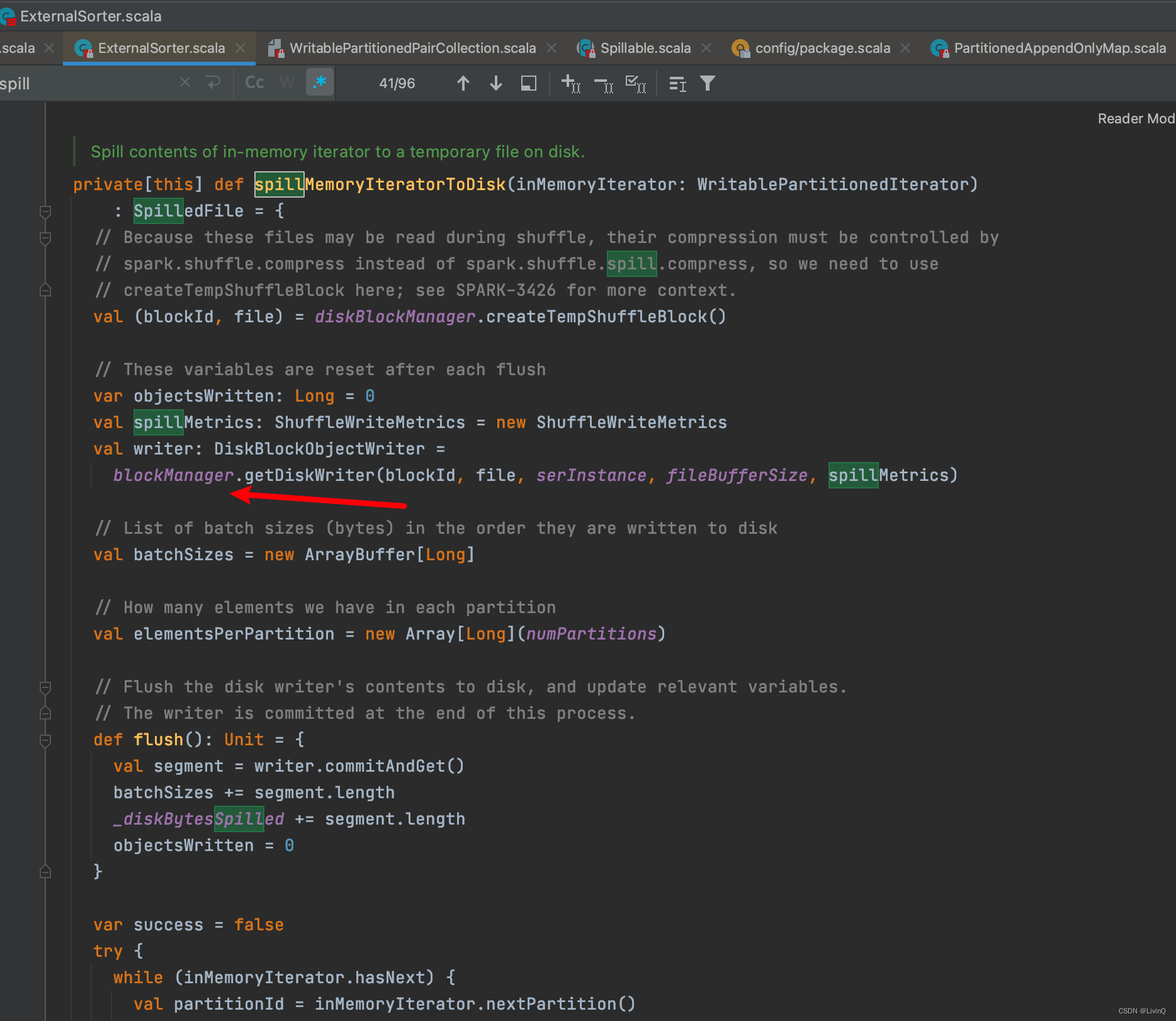
合并
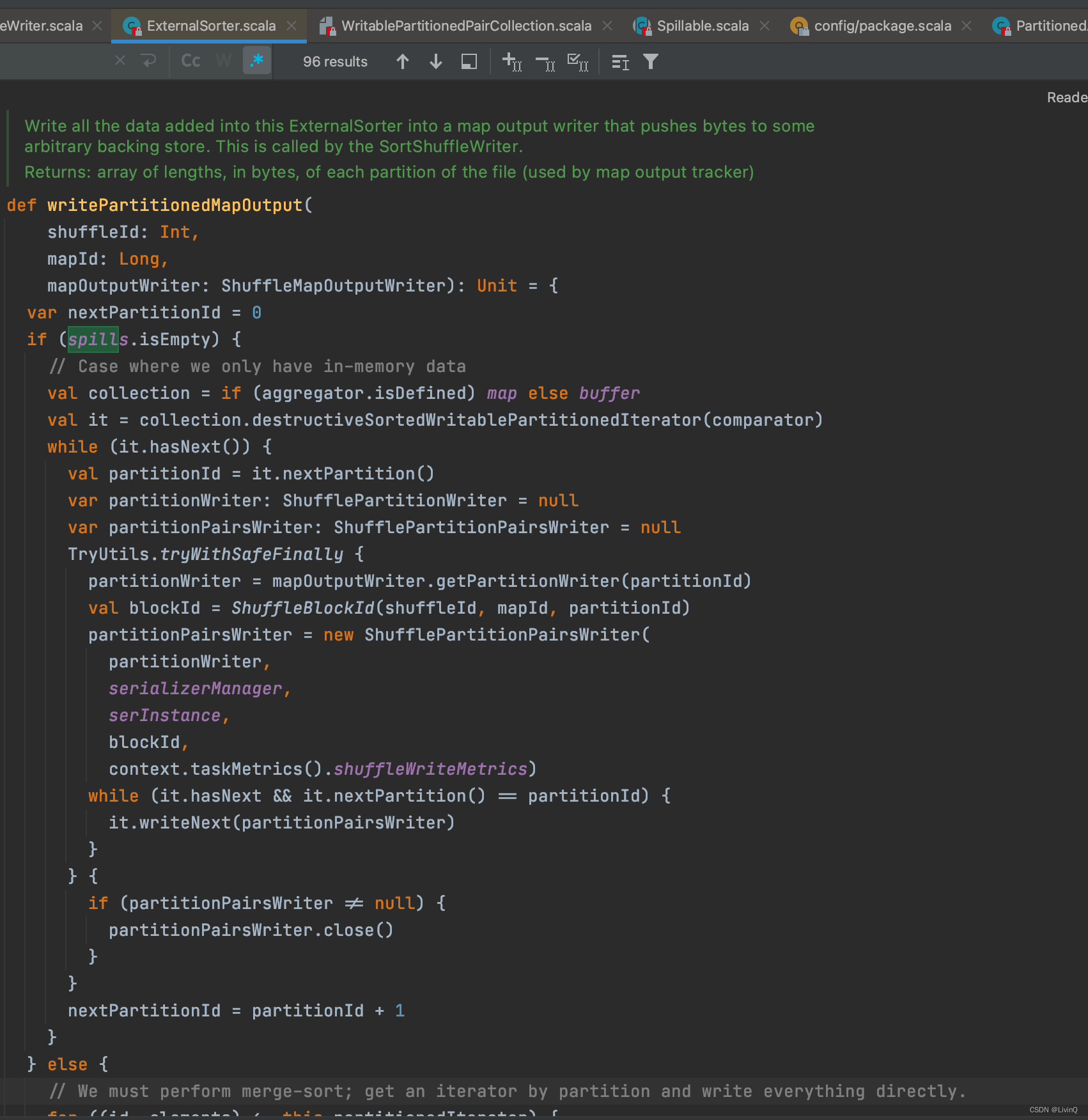
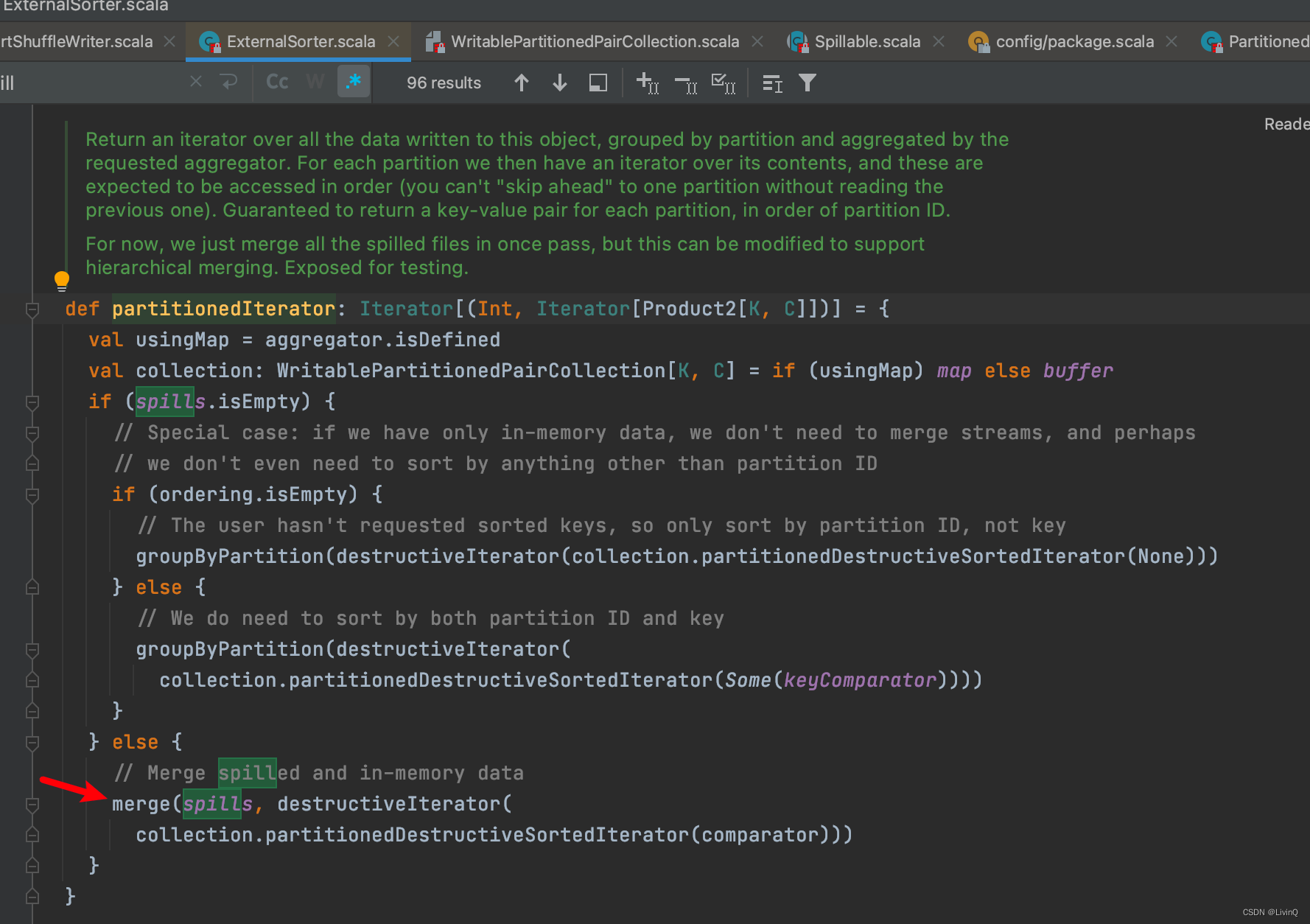
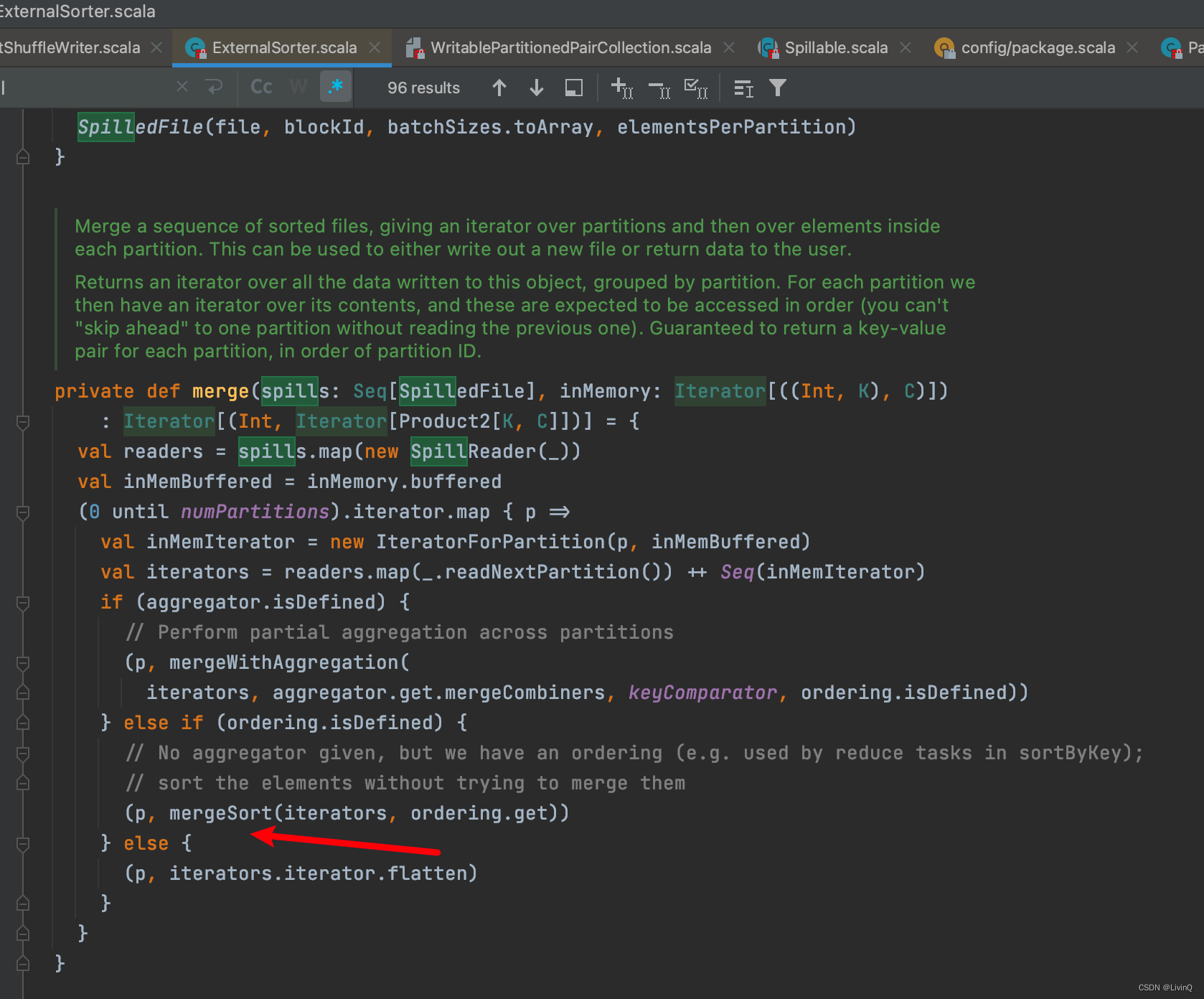
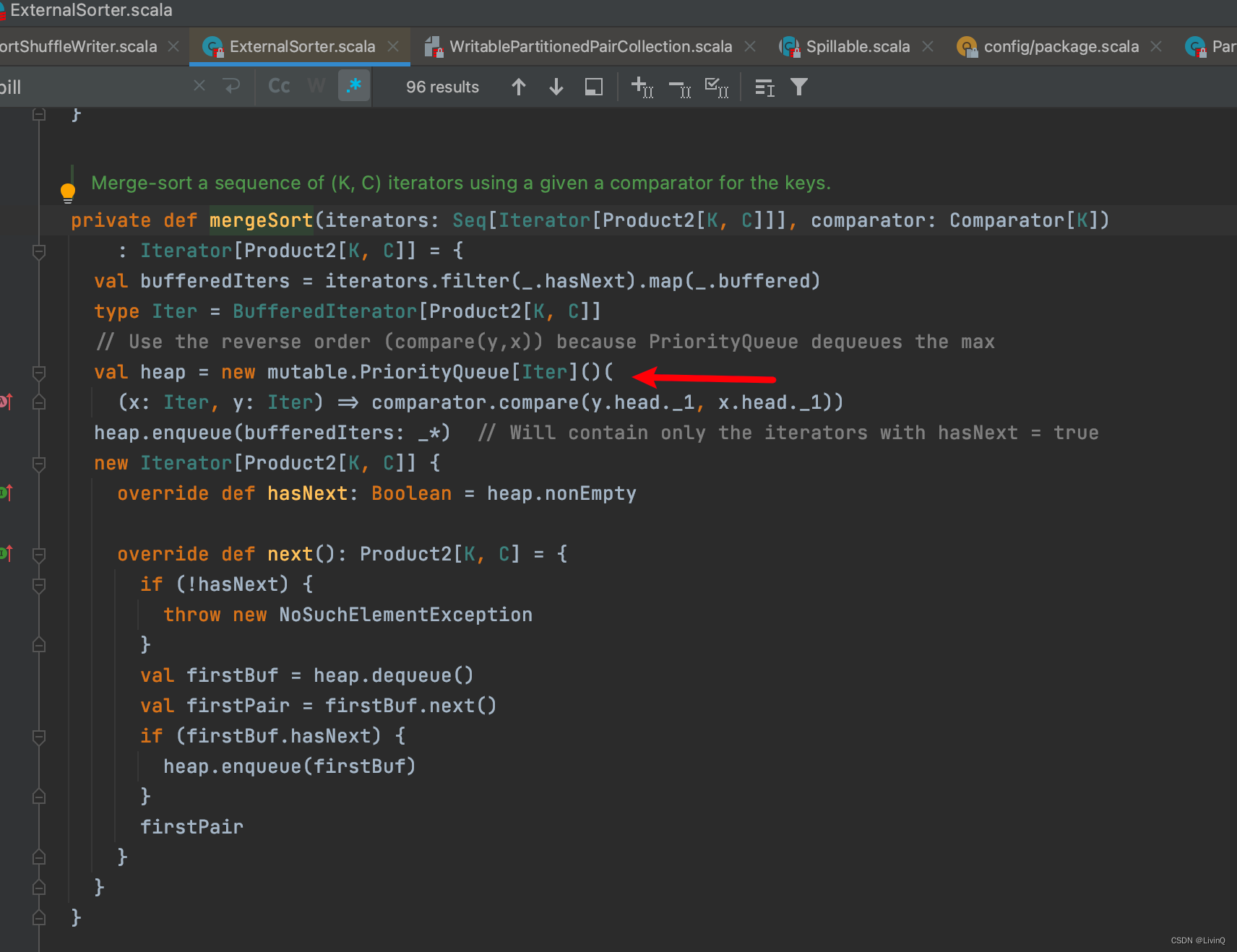
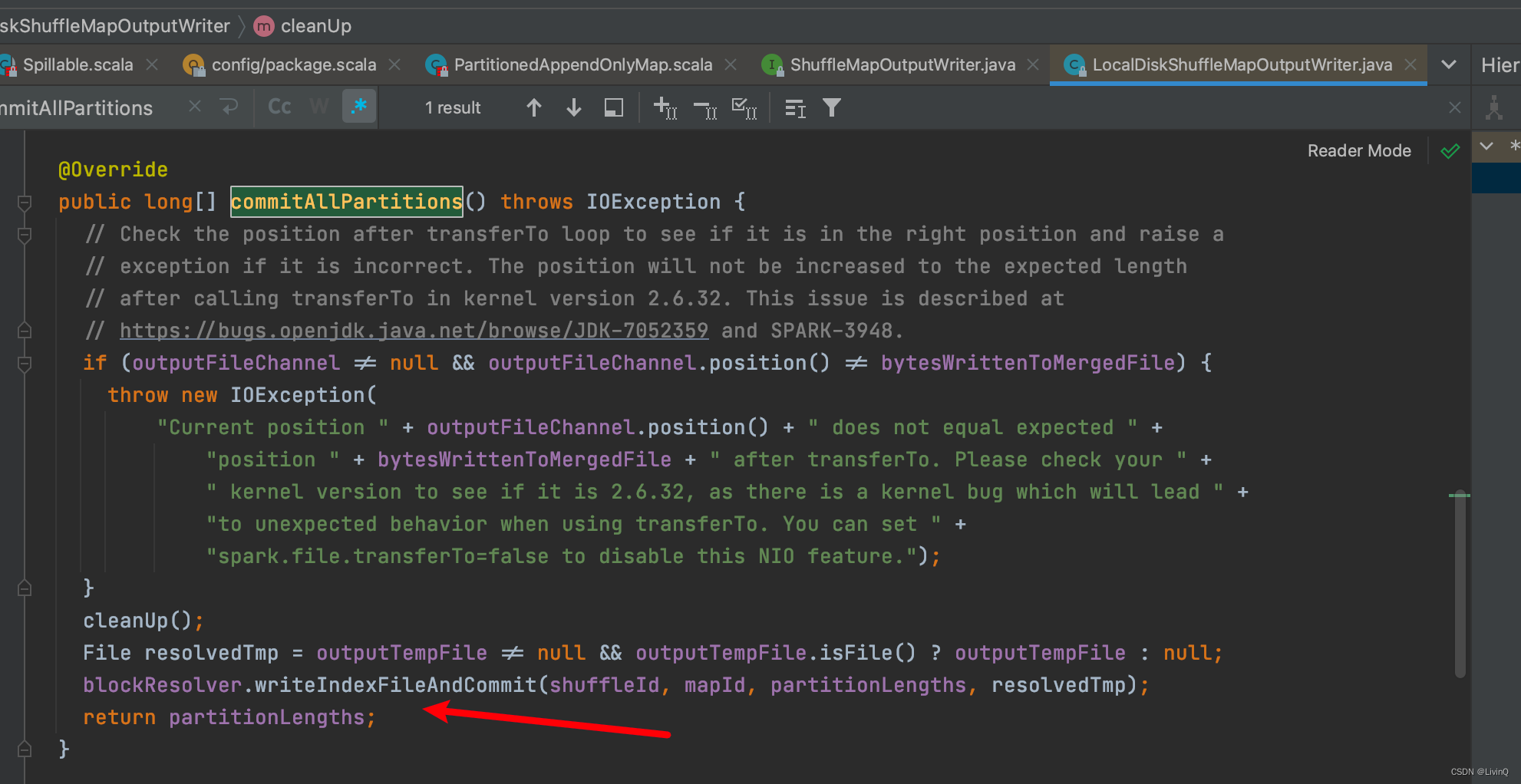
提交所有文件 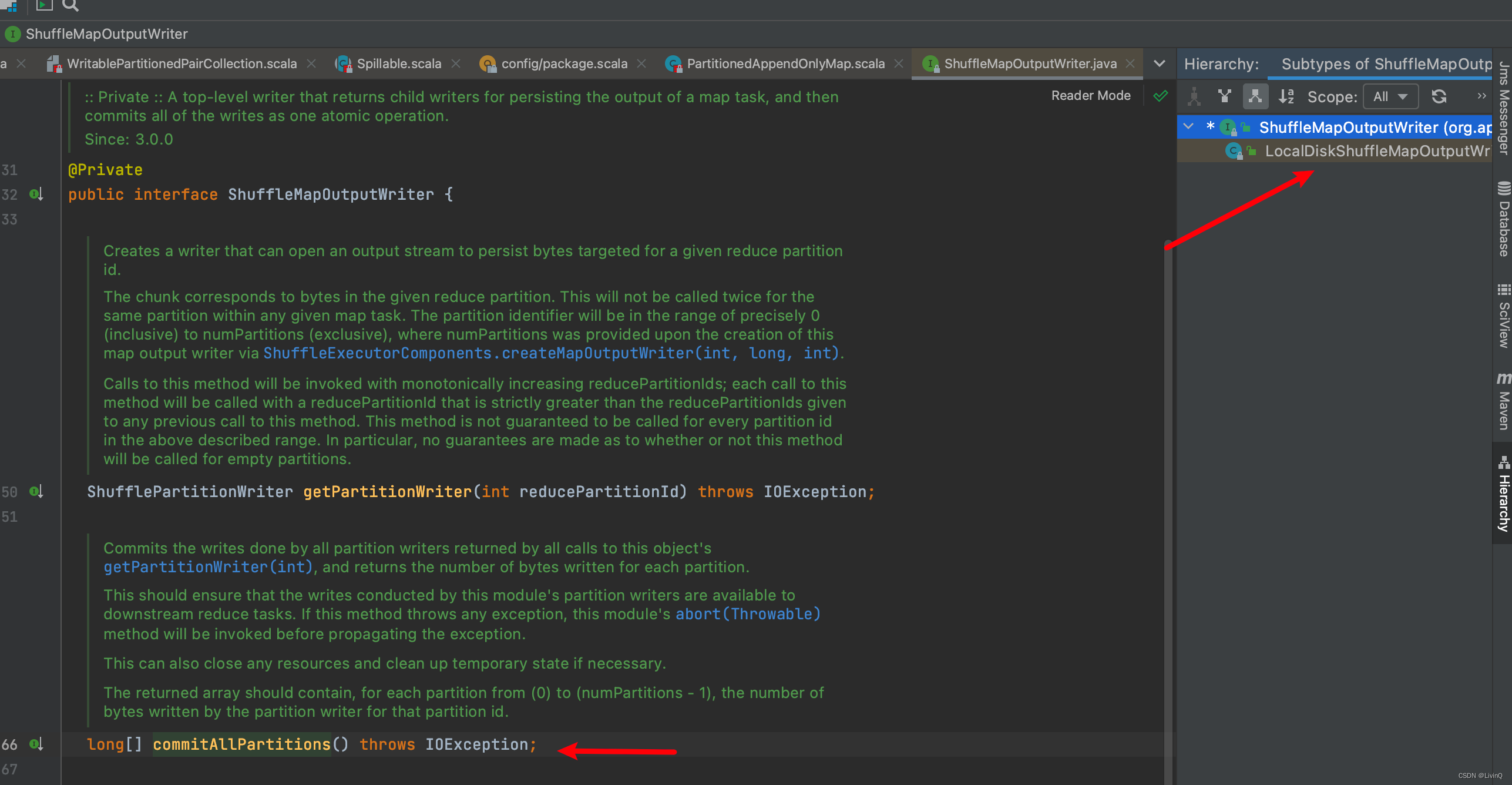
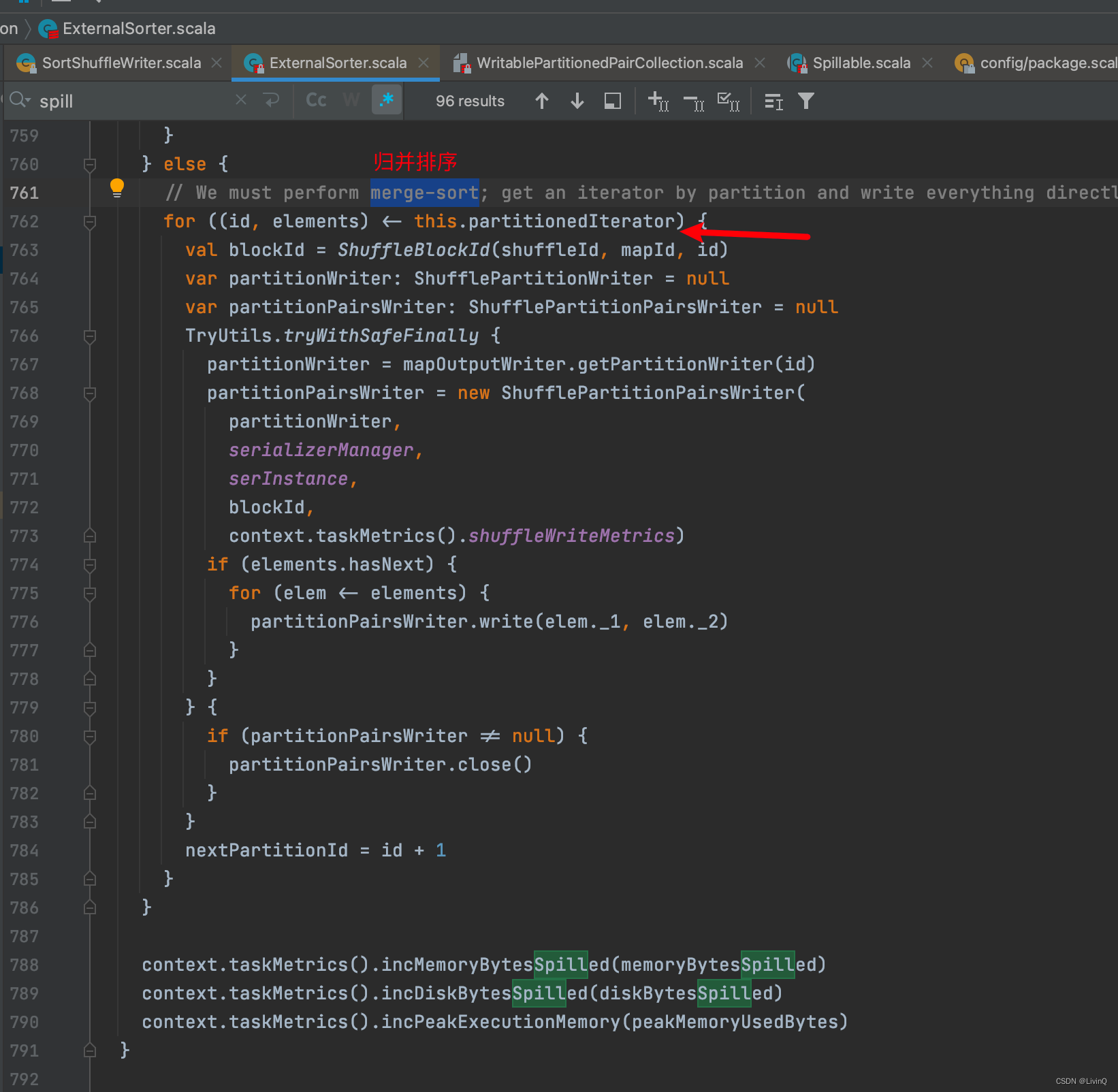
BypassMergeSortShuffleWriter 追踪
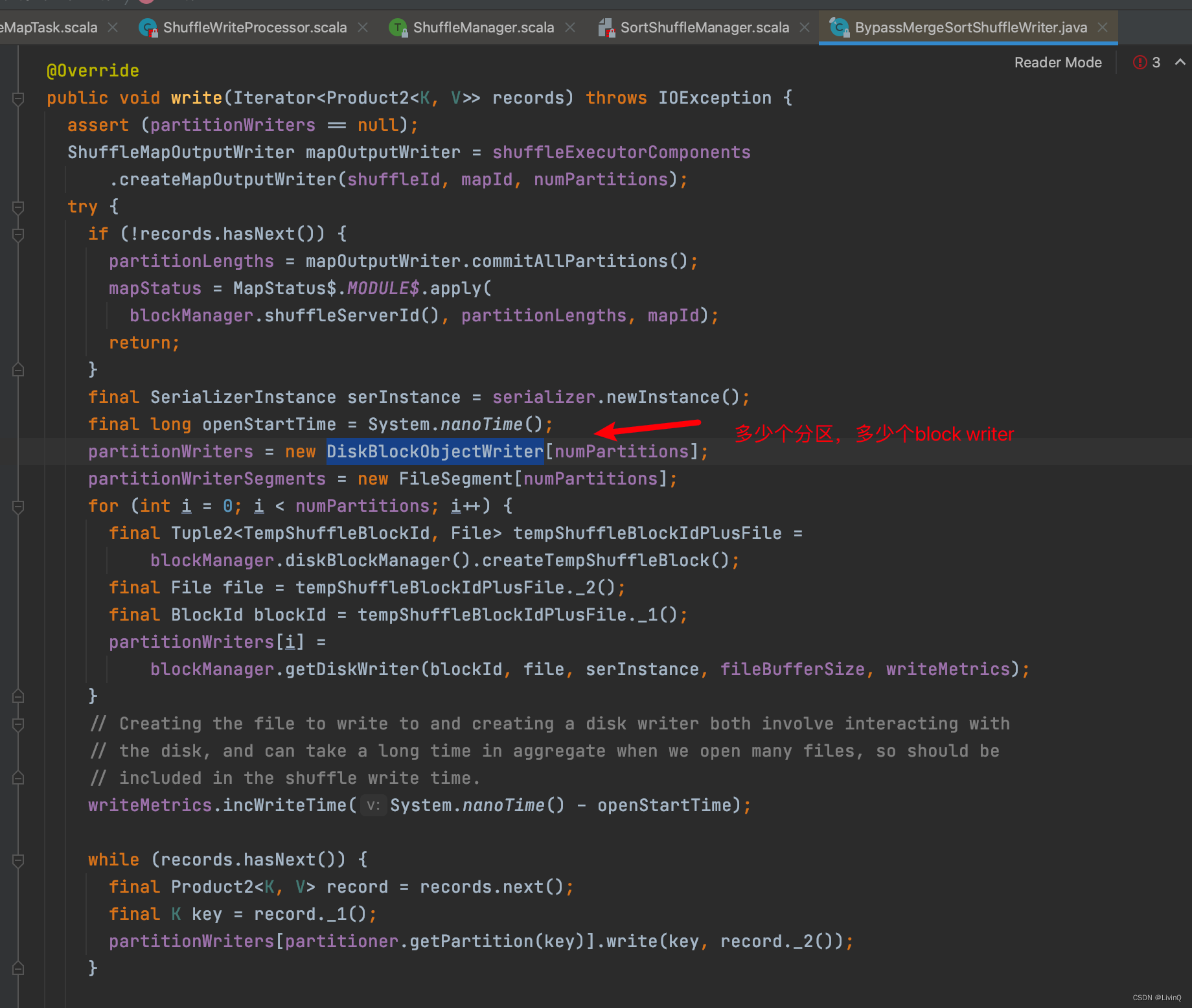
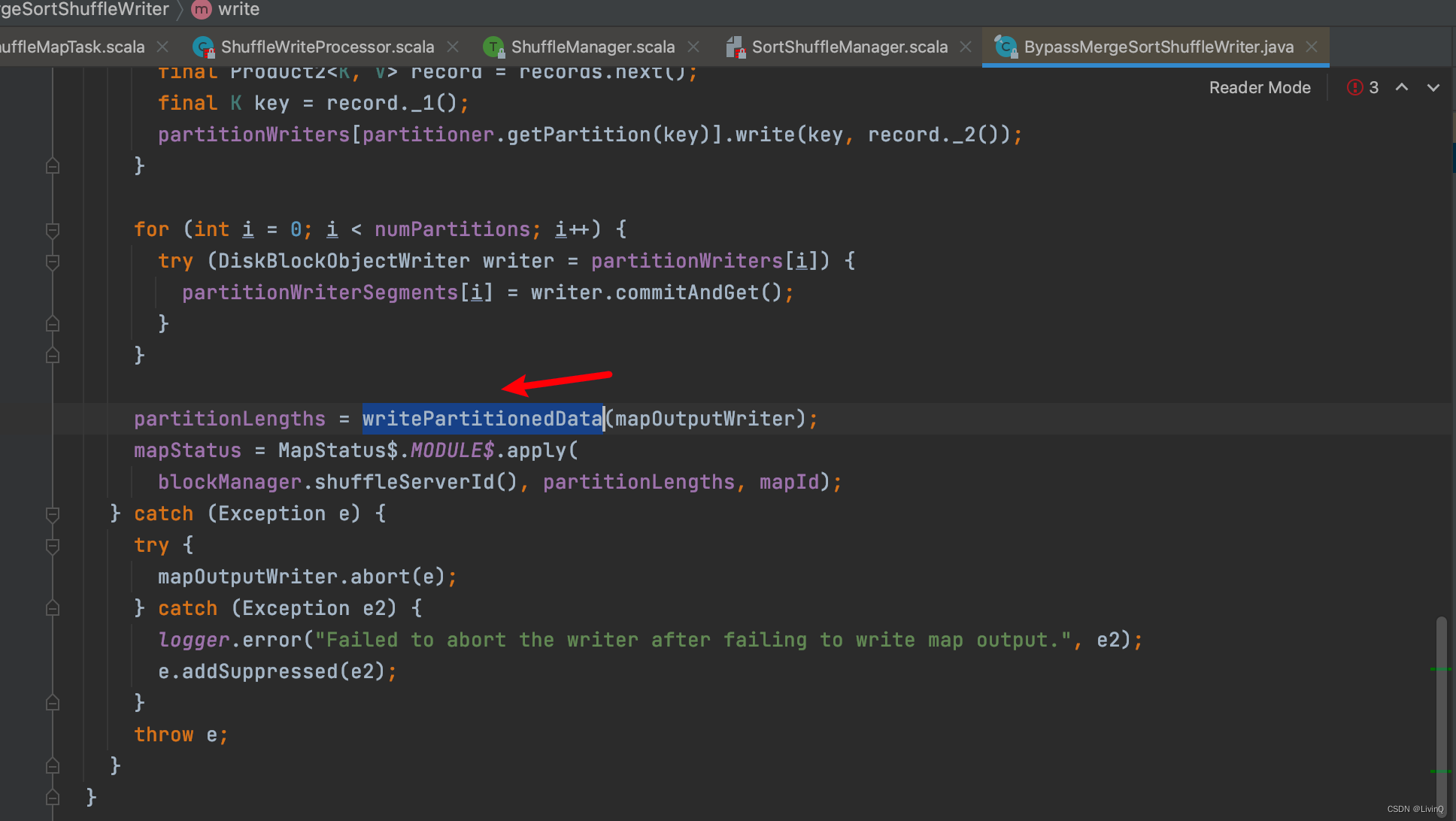
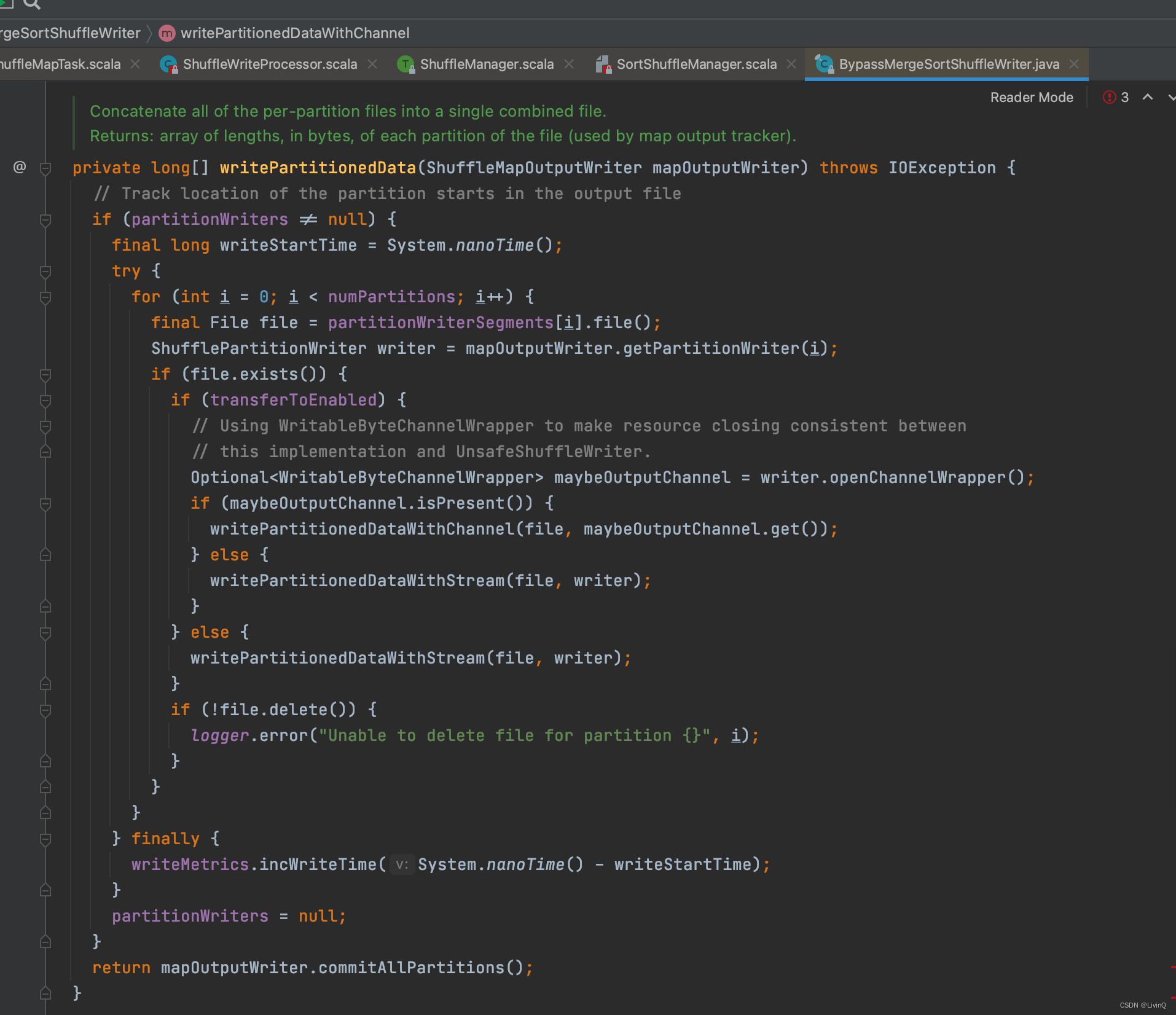
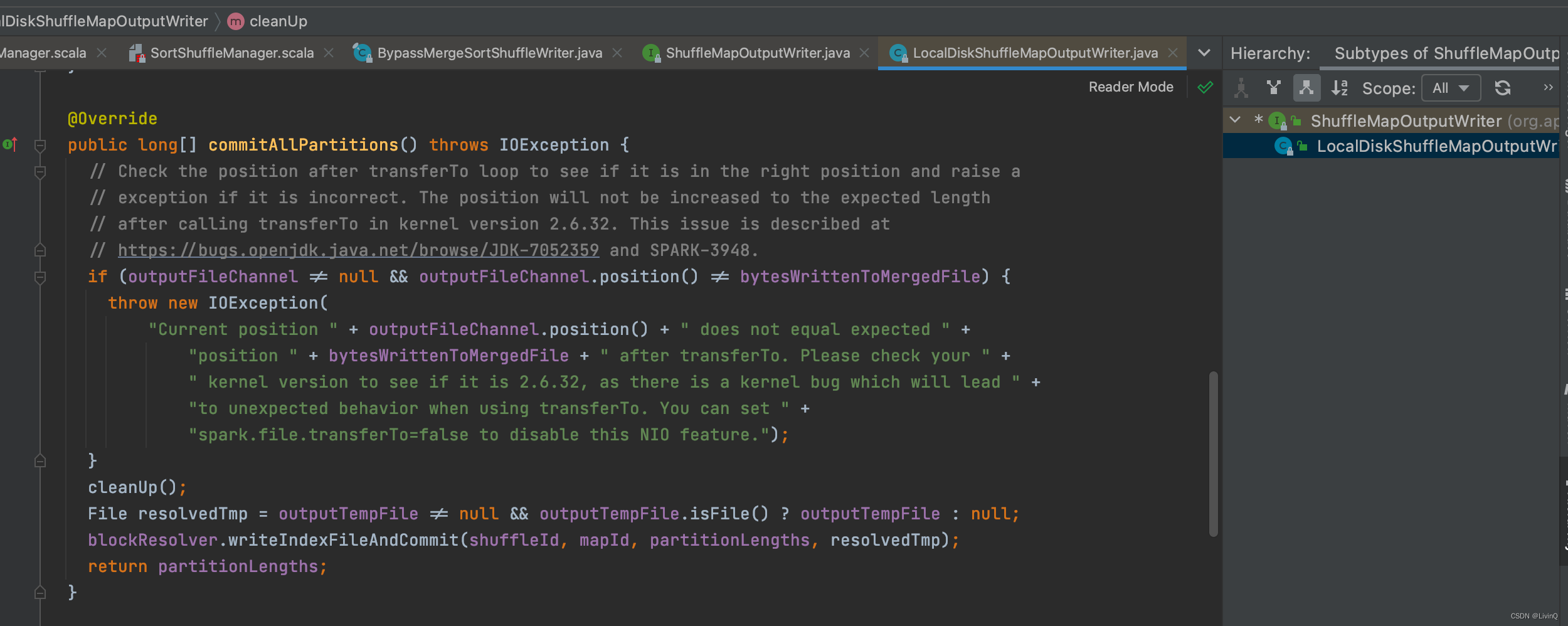
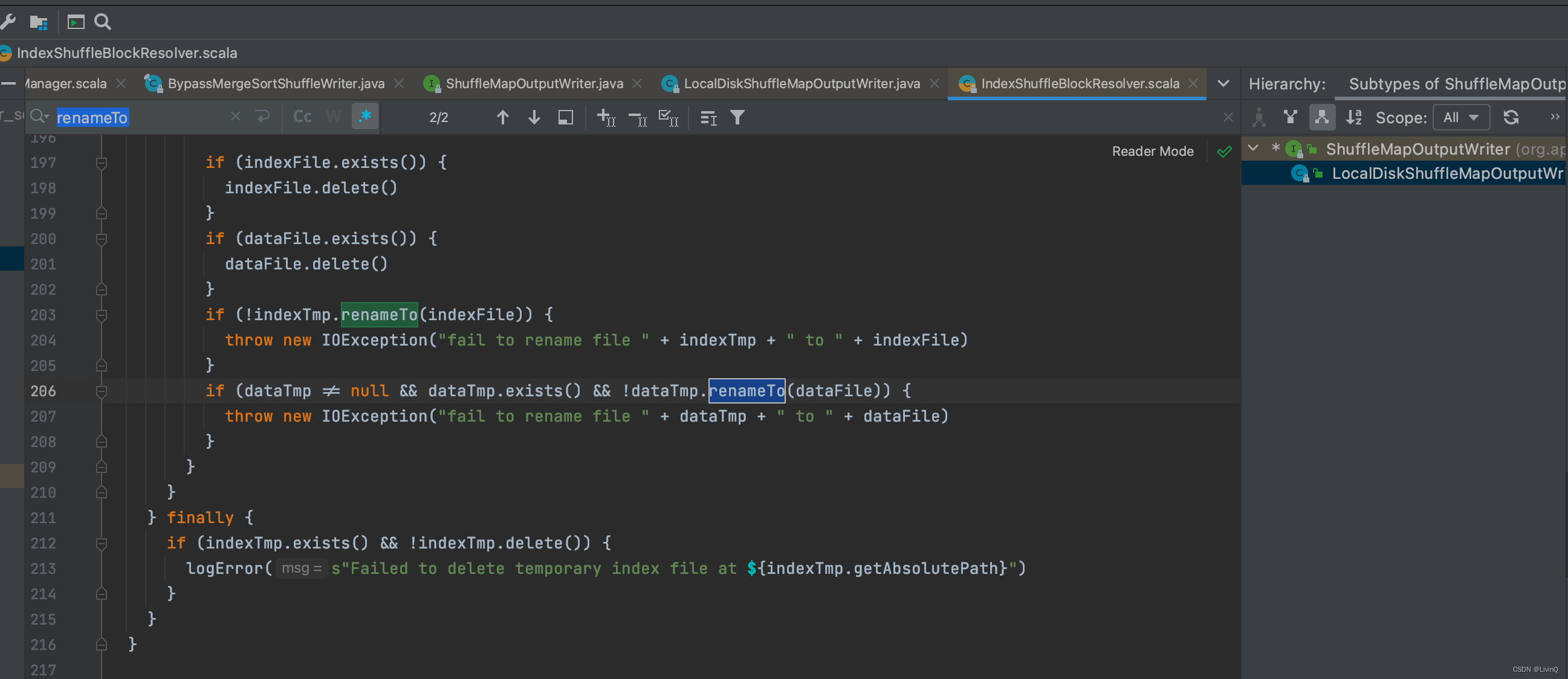 从这里可以看出,bypass和hash v2 很像,也是多少个分区,多少个文件,但是bypass最终做了合并
从这里可以看出,bypass和hash v2 很像,也是多少个分区,多少个文件,但是bypass最终做了合并
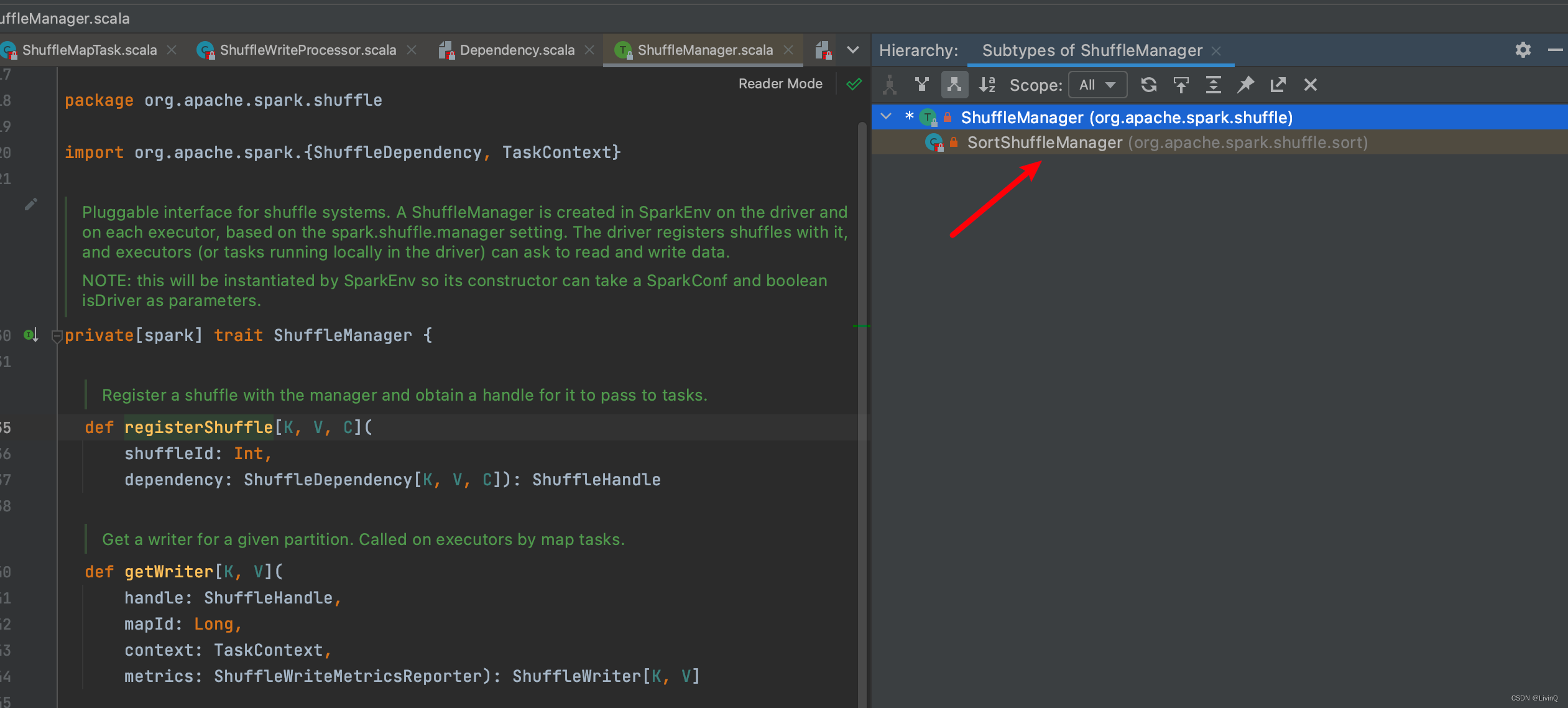
各个handle触发条件

4、优化
优化数据结构
尽可能使用原生类型(Int,Long,Double等)
尽可能使用对象数据一起原生类型数组以代替Java或者Scala集合类
尽可能避免采用嵌套数据结构来保存小对象
主动shuffle - repartition
如果分区数较少,可增大分区,将任务细分
参数调优
spark.shuffle.file.buffer buffer wirte 缓冲大小(默认是32K)改 64k
spark.reducer.maxSizeInFlight shuffle read task的buffer缓冲大小(默认48M) 改 96M
spark.shuffle.io.maxRetries shuffle失败重试次数(默认3次)
spark.shuffle.io.retryWait 每次重试拉取数据的等待间隔(默认5秒)
spark.shuffle.memoryFraction shuffle内存占比使用预聚合算子
reducebykey 代替 groupbykey
5、小总结
4种shuffle
- hash shuffle v1
- 小文件多 M * R
- hash shuffle v2
- 优化小文件数 E * R
- sort shuffle
- 排序(分区号,key) + 合并 E
- bypass shuffle
- 合并 E
- 触发条件
- shuffle map task 数 < spark.shuffle.sort.bypassMergeThreshold (默认 200)
- 无预聚合操作

















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









