






没想到真的有人看哈哈,那就多说两句,本小白是在准备考研复试,文章仅作总结,笔记使用,出现一定的错误和误区纯属正常现象。
本文可能存在一定错误与误区,期待各位读者指正。
本文章中的部分例子仅用于生动解释相关概念,切勿结合实际过度解读。
语雀链接:《机器学习与深度学习》
部分内容来源:B站:李哥考研
1.6机器学习基础知识
复试包括面试注重基础知识点,而不是你代码写了什么,代码这段是干什么的。
深度学习在不断变化,以后回过头来有差异很正常
大纲
0.机器学习与深度学习介绍
1.多层神经网络,多层感知机
2.python基本操作,环境搭建,pytorch介绍
3.深度学习解决回归任务。回归代码实战:新冠人预测。(目标是看懂一个深度学习项目,模型保存,预测,训练集和验证集划分,测试集评估)
4.图片分类任务,卷积神网络介绍。经典卷积神经网络
5.图片分类任务实战,食物分类任务。(迁移学习,图片增广,目标是学会写一个项目)
6.深度学习和特征的关系,为后面做铺垫的课
7.nlp任务介绍,(RNN,LSTM简单介绍)。主要介绍self-attention机制与bert模型代码的讲解。(无监督和自监督在这一章介绍)。
8.BERT实战,文本感情分类任务。
9.初识生成任务,认识生成任务项目代码。
10.Vit模型与多模态任务,大模型简介。
零:
人工智能——很早就运用了,
早期 一套规则,输入,然后按规则输出(象棋人工智能),
后来(数据量太大了,无法穷尽) 深度学习,围棋人工智能。通过答案和数据自己推理规则,而不是产生答案。
狭义机器学习,上述图片的
基于数学或者统计学方法,具有很强的可解释性(说得通,令人信服)。(几个经典的传统机器学习算法,KNN,决策树,朴素贝叶斯)
KNN:K最近邻居(K-Nearest Neighbors)
一种监督算法,用于分类和回归问题,基本思想是通过测量不同数据点之间的距离来进行预测
Knn工作原理可以概括为以下几个步骤
- 距离度量,knn使用距离度量(通常是欧式距离(现实世界的三维距离))来衡量数据点之间的相似性。
- 确定邻居数量k
- 投票机制
决策树——根据以往的数据画出一个决策树来判断新的数据——不善于处理没见过的特征,添加其他特征
朴素贝叶斯算法(朴素贝叶斯的后验)就是学姐已经到终点了,然后看学姐是通过哪个途径来的,计算其概率。

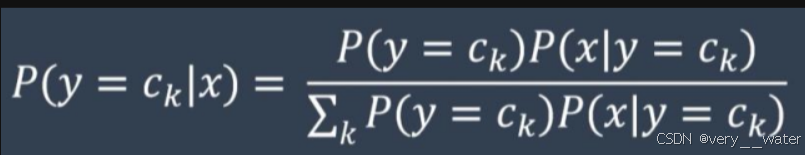
0.067
*推荐一个b站up讲机器学习算法的 风中摇曳的小萝卜
关于深度学习,是机器学习的一个子集,利用多层神经网络从大量数据中进行学习——设计一个很深的网络架构让机器自己学。(是个黑匣子,没有可解释性,是一个实践为主的科目)
记住一句话,所谓深度学习就是在找一个函数f。通过x输入能得到正确的输出就是成功!
今天有点懒,就更一点,明天一定补个长的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









