









总结
本场周赛太拉跨了!T1做完后,T2一直被卡住,还好后面暂时跳过了T2去做T3,T3做完后又回过头来继续调试T2。在最后10分钟调过了(虽然后来看运行时长达到了1400ms(差点就过不了))。
这周被T2搞了,差点就是一题选手。
T1是暴力模拟;T2是预处理+二分;T3是图的遍历;T4是动态规划+前缀和优化。
T4还是具有一些思维难度的。
2475. 数组中不等三元组的数目
给你一个下标从 0 开始的正整数数组 nums 。请你找出并统计满足下述条件的三元组 (i, j, k) 的数目:
0 <= i < j < k < nums.lengthnums[i]、nums[j]和nums[k]两两不同 。- 换句话说:
nums[i] != nums[j]、nums[i] != nums[k]且nums[j] != nums[k]
- 换句话说:
返回满足上述条件三元组的数目。
提示
3 <= nums.length <= 1001 <= nums[i] <= 1000
示例
输入:nums = [4,4,2,4,3]
输出:3
解释:下面列出的三元组均满足题目条件:
- (0, 2, 4) 因为 4 != 2 != 3
- (1, 2, 4) 因为 4 != 2 != 3
- (2, 3, 4) 因为 2 != 4 != 3
共计 3 个三元组,返回 3 。
注意 (2, 0, 4) 不是有效的三元组,因为 2 > 0 。
思路
模拟
// C++
class Solution {
public:
int unequalTriplets(vector<int>& nums) {
int ans = 0, n = nums.size();
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
for (int k = j + 1; k < n; k++) {
if (nums[i] != nums[j] && nums[i] != nums[k] && nums[j] != nums[k]) ans++;
}
}
}
return ans;
}
};
2476. 二叉搜索树最近节点查询
给你一个 二叉搜索树 的根节点 root ,和一个由正整数组成、长度为 n 的数组 queries 。
请你找出一个长度为 n 的 二维 答案数组 answer ,其中 answer[i] = [mini, maxi] :
mini是树中小于等于queries[i]的 最大值 。如果不存在这样的值,则使用-1代替。maxi是树中大于等于queries[i]的 最小值 。如果不存在这样的值,则使用-1代替。
返回数组 answer 。
提示:
- 树中节点的数目在范围
[2, 10^5]内 1 <= Node.val <= 10^6n == queries.length1 <= n <= 10^51 <= queries[i] <= 10^6
示例
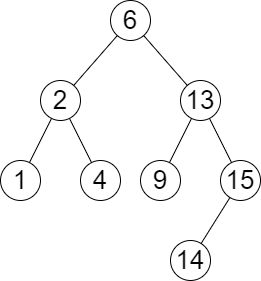
输入:root = [6,2,13,1,4,9,15,null,null,null,null,null,null,14], queries = [2,5,16]
输出:[[2,2],[4,6],[15,-1]]
解释:按下面的描述找出并返回查询的答案:
- 树中小于等于 2 的最大值是 2 ,且大于等于 2 的最小值也是 2 。所以第一个查询的答案是 [2,2] 。
- 树中小于等于 5 的最大值是 4 ,且大于等于 5 的最小值是 6 。所以第二个查询的答案是 [4,6] 。
- 树中小于等于 16 的最大值是 15 ,且大于等于 16 的最小值不存在。所以第三个查询的答案是 [15,-1] 。
思路
二分
先通过中序遍历,将二叉搜索树转变成从小到大排好序的数组,然后在数组上二分即可。
中序遍历
O
(
n
)
O(n)
O(n),m次询问,每次都是
O
(
l
o
g
n
)
O(logn)
O(logn),总复杂度是
O
(
n
+
m
l
o
g
n
)
O(n + mlogn)
O(n+mlogn)
// C++
class Solution {
public:
void dfs(TreeNode* x, vector<int>& v) {
if (x == nullptr) return ;
dfs(x->left, v);
v.push_back(x->val);
dfs(x->right, v);
}
vector<vector<int>> closestNodes(TreeNode* root, vector<int>& queries) {
vector<int> v;
dfs(root, v);
int n = queries.size();
vector<vector<int>> ans(n, vector<int>(2, -1));
for (int i = 0; i < n; i++) {
int x = queries[i];
int l = 0, r = v.size() - 1;
while (l < r) {
int mid = l + r + 1 >> 1;
if (v[mid] <= x) l = mid;
else r = mid - 1;
}
if (v[l] <= x) ans[i][0] = v[l];
l = 0, r = v.size() - 1;
while (l < r) {
int mid = l + r >> 1;
if (v[mid] >= x) r = mid;
else l = mid + 1;
}
if (v[l] >= x) ans[i][1] = v[l];
}
return ans;
}
};
周赛当天,我一直没想到先转成数组再进行二分。我一直在树上进行查找😓
贴一个TLE的代码
// C++
class Solution {
public:
int findLower(TreeNode* root, int x) {
int ans = -1;
TreeNode* cur = root;
while (cur != nullptr) {
if (cur->val == x) return x;
if (cur->val > x) cur = cur->left;
else {
ans = cur->val;
cur = cur->right;
}
}
return ans;
}
int findUpper(TreeNode* root, int x) {
int ans = -1;
TreeNode* cur = root;
while (cur != nullptr) {
if (cur->val == x) return x;
if (cur->val < x) cur = cur->right;
else {
ans = cur->val;
cur = cur->left;
}
}
return ans;
}
vector<vector<int>> closestNodes(TreeNode* root, vector<int>& queries) {
int n = queries.size();
vector<vector<int>> ans(n, vector<int>(2, -1));
for (int i = 0; i < n; i++) {
int x = queries[i];
ans[i][0] = findLower(root, x);
if(ans[i][0] == x) ans[i][1] = x;
else ans[i][1] = findUpper(root, x);
}
return ans;
}
};
再贴一个周赛当天最后勉强AC的代码
// C++ 1460ms
class Solution {
public:
// 将两次查找合并为一次
void find(TreeNode* root, int x, int& l, int& r) {
int L = -1, R = -1;
TreeNode* cur = root;
while (cur != nullptr) {
if (cur->val == x) {
L = R = x;
break;
} else if (cur->val > x) {
R = cur->val;
cur = cur->left;
} else {
L = cur->val;
cur = cur->right;
}
}
l = L;
r = R;
}
vector<vector<int>> closestNodes(TreeNode* root, vector<int>& queries) {
int n = queries.size();
vector<vector<int>> ans(n, vector<int>(2, -1));
for (int i = 0; i < n; i++) {
int x = queries[i];
find(root, x, ans[i][0], ans[i][1]);
}
return ans;
}
};
然而今天(2022/11/23)再尝试提交上述代码,发现已经不能通过了 😓
2477. 到达首都的最少油耗
给你一棵 n 个节点的树(一个无向、连通、无环图),每个节点表示一个城市,编号从 0 到 n - 1 ,且恰好有 n - 1 条路。0 是首都。给你一个二维整数数组 roads ,其中 roads[i] = [ai, bi] ,表示城市 ai 和 bi 之间有一条 双向路 。
每个城市里有一个代表,他们都要去首都参加一个会议。
每座城市里有一辆车。给你一个整数 seats 表示每辆车里面座位的数目。
城市里的代表可以选择乘坐所在城市的车,或者乘坐其他城市的车。相邻城市之间一辆车的油耗是一升汽油。
请你返回到达首都最少需要多少升汽油。
提示:
1 <= n <= 10^5roads.length == n - 1roads[i].length == 20 <= ai, bi < nai != biroads表示一棵合法的树。1 <= seats <= 10^5
示例
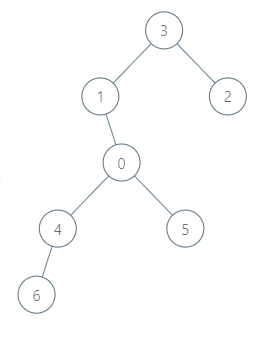
输入:roads = [[3,1],[3,2],[1,0],[0,4],[0,5],[4,6]], seats = 2
输出:7
解释:
- 代表 2 到达城市 3 ,消耗 1 升汽油。
- 代表 2 和代表 3 一起到达城市 1 ,消耗 1 升汽油。
- 代表 2 和代表 3 一起到达首都,消耗 1 升汽油。
- 代表 1 直接到达首都,消耗 1 升汽油。
- 代表 5 直接到达首都,消耗 1 升汽油。
- 代表 6 到达城市 4 ,消耗 1 升汽油。
- 代表 4 和代表 6 一起到达首都,消耗 1 升汽油。
最少消耗 7 升汽油。
思路
树的遍历+贪心
考虑每条边上至少需要多少辆车。
我们可以通过DFS求出以某个节点作为根节点的子树的全部节点数量,而该节点再往上走时,一共的人数就是子树的节点数,这样我们就能算出这个节点往上经过的那条边,需要通过的总人数,于是能算出通过这条边最少需要的车的数量。
// C++
const int N = 1e5 + 10, M = 2 * N;
class Solution {
public:
int h[N], e[M], ne[M], idx;
bool st[N];
long long ans = 0;
void add(int a, int b) {
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
int dfs(int x, int& seat) {
// 以x为根节点的子树的节点数量
int cnt = 1;
for (int i = h[x]; i != -1; i = ne[i]) {
int u = e[i];
if (st[u]) continue;
st[u] = true;
cnt += dfs(u, seat);
}
if (x != 0) {
int k = cnt / seat;
if (cnt % seat) k++;
// 这里其实就是向上取整, 可以用 k = (cnt + seat - 1) / seat
ans += k;
}
return cnt;
}
long long minimumFuelCost(vector<vector<int>>& roads, int seats) {
if (roads.empty()) return 0;
// 建图
memset(h, -1, sizeof h);
for (auto& r : roads) {
add(r[0], r[1]);
add(r[1], r[0]);
}
st[0] = true;
// 深搜
dfs(0, seats);
return ans;
}
};
注意:遍历树的时候,可以额外往dfs方法里传入一个father,就可以不用开visited数组来记录已经遍历的节点了!
2478. 完美分割的方案数
给你一个字符串 s ,每个字符是数字 '1' 到 '9' ,再给你两个整数 k 和 minLength 。
如果对 s 的分割满足以下条件,那么我们认为它是一个 完美 分割:
s被分成k段互不相交的子字符串。- 每个子字符串长度都 至少 为
minLength。 - 每个子字符串的第一个字符都是一个 质数 数字,最后一个字符都是一个 非质数 数字。质数数字为
'2','3','5'和'7',剩下的都是非质数数字。
请你返回 s 的 完美 分割数目。由于答案可能很大,请返回答案对 10^9 + 7 取余 后的结果。
一个 子字符串 是字符串中一段连续字符串序列。
提示
1 <= k, minLength <= s.length <= 1000s每个字符都为数字'1'到'9'之一。
示例
输入:s = "23542185131", k = 3, minLength = 2
输出:3
解释:存在 3 种完美分割方案:
"2354 | 218 | 5131"
"2354 | 21851 | 31"
"2354218 | 51 | 31"
思路
思路一:暴力
周赛当天已经没时间做T4了,事后做了下,先记录下自己思路:首先找到所有分割点,每个分割点的前面是一个非质数,后面是一个质数。要将原字符串分割成k段,那么需要切k - 1刀。假设分割点一共有n个。那么问题就是,在n个分割点中,选择k - 1个,使得每一段子串的长度都大于等于minLength。那么一个比较直观的思路是,先求出所有分割点,然后暴力枚举所有的分割方案,并进行统计计数。
// C++
const int MOD = 1e9 + 7;
class Solution {
public:
bool isPrime(int x) {
return x == 2 || x == 3 || x == 5 || x == 7;
}
int ans = 0;
void dfs(string& s, int begin, int k, int& minLength, vector<int>& cut, int i) {
if (i == cut.size() && k > 0) return ;
// 剩余的切割次数
if (k == 0) {
if (s.size() - begin >= minLength) ans = (ans + 1) % MOD;
return ;
}
for (int j = i; j < cut.size(); j++) {
if (cut[j] - begin + 1 < minLength) continue;
dfs(s, cut[j] + 1, k - 1, minLength, cut, j + 1);
}
}
int beautifulPartitions(string s, int k, int minLength) {
int n = s.size();
if (!isPrime(s[0] - '0') || isPrime(s[n - 1] - '0')) return 0;
vector<int> cut;
for (int i = 1; i < n - 1; i++) {
if (!isPrime(s[i] - '0') && isPrime(s[i + 1] - '0')) cut.push_back(i);
}
dfs(s, 0, k - 1, minLength, cut, 0);
return ans;
}
};
这种解法,超时都超到河外星系去了。只通过了16/73个测试数据。
假设我们的分割点共有40个吧,需要从中挑选出20个,也就是我们要计算的组合数是 C 40 20 = 137846528820 C_{40}^{20} = 137846528820 C4020=137846528820,上面是通过枚举每一种切割方案,每找到一个合法方案就累加1。那么DFS要递归执行 1 0 12 10^{12} 1012次。超时超太多了。而且题目里说了,答案可能很大,请对 1 0 9 + 7 10^9 + 7 109+7 取模。也就是说答案肯定是会大于 1 0 9 10^9 109的,那么用暴力枚举每种方案的时间复杂度一定会超过 1 0 9 10^9 109。
这个问题看上去可以被拆分成更小的子问题,所以接下来我的想法就是动态规划。
思路二:动态规划
我们用状态f[i][j]表示,将字符串s在[0, i]内的部分,分割为j段满足条件的子字符串,分割的方案数目。
设字符串s的长度为n,那么最终的答案就是f[n - 1][k]。
接下来考虑下状态转移,对于某个状态f[i][j],我们考虑其分割后,末尾最后一段子串。
假设最后一段子串的长度为p,那么f[i][j]的值需要加上一个f[i - p][j - 1]。
即需要加上,去除最后一段子串,前面部分,切割成j - 1段的方案数。
我们只需要枚举,所有满足条件的最后一段子串,并把方案数全部累加起来,就能得到f[i][j]。
由于我们可以预处理得到所有的分割点。那么对于f[i][j],我们可以从位置i开始往前找,找到第一个分割点x,满足该分割点的位置到i的距离大于等于minLength(即,从分割点x进行分割,最后一段子串的长度是>= minLength的),那么对于x之前的所有分割点,都是满足条件的分割点,需要将方案数进行累加。
// C++
const int MOD = 1e9 + 7;
class Solution {
public:
unordered_set<char> primes{'2', '3', '5', '7'};
// 找到与 end 距离大于等于 minLength 的 第一个分割点
int find(vector<int>& cuts, int end, int minLength) {
int l = 0, r = cuts.size() - 1;
while (l < r) {
int mid = l + r + 1 >> 1;
if (cuts[mid] <= end - minLength + 1) l = mid;
else r = mid - 1;
}
if (cuts[l] <= end - minLength + 1) return l;
return -1;
}
int beautifulPartitions(string s, int k, int minLength) {
int n = s.size();
if (!primes.count(s[0]) || primes.count(s[n - 1])) return 0;
// 存能分割的点的起始位置, 若s[i - 1]为非质数, s[i]为质数, 则存i
vector<int> cuts; // 下标从1开始
cuts.push_back(1); // 首先第一个位置是一个分割点
for (int i = 2; i <= n; i++) {
if (!primes.count(s[i - 2]) && primes.count(s[i - 1])) cuts.push_back(i);
}
// f[i][j] 将[1, i]的部分字符串分成j段不相交的子字符串的方案数
vector<vector<int>> f(n + 1, vector<int>(k + 1));
// 分割点x为1时, k = 1, 需要加上 f[x - 1][k - 1] = f[0][0]
// 应当初始化为1
f[0][0] = 1;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= k; j++) {
// 找到第一个满足最后一段子串长度>=minLength的分割点, 并遍历其之前的所有分割点
for (int p = find(cuts, i, minLength); p >= 0; p--) {
f[i][j] += f[cuts[p] - 1][j - 1]; // 方案累加
f[i][j] %= MOD;
}
}
}
return f[n][k];
}
};
上面这份代码也是超时,但是只超到了太阳系,不像第一种暴力做法那么离谱,一共通过了55/73个测试数据。
计算一下时间复杂度,字符串s的长度n最大为1000,k最大有1000,那么总共有
1
0
6
10^6
106 个状态。假设分割点的个数为c,那么每个状态的转移,需要c的计算量,我看了一组超时的数据,其分割点数量在250左右,那么此时总的时间复杂度就已经达到了
1
0
8
10^8
108 。
思路三:动态规划+前缀和
其实观察一下上面的状态转移:会发现,先是找一个最近的分割点,然后需要将该分割点前面所有分割点的状态进行一下累加。
这就很容易和前缀和联系起来,我们用前缀和可以把这个状态的累加,优化为 O ( 1 ) O(1) O(1) ,这样总的时间复杂度就能控制在 1 0 6 10^6 106 ,就不会超时啦。
不过这个前缀和到底要怎样表示,我还是想了半天。
其实,上面的状态表示数组的第一维,我们可以不用枚举[1, n],因为字符串的有些位置是无效的。我们只需要枚举那些切割点的位置。比如字符串长度为10,其中切割点有:1,3,8。其实我们不需要枚举切割点以外的位置。为什么呢?因为在某个状态进行转移时,它肯定是从某个切割点转移过来的。那么我们只要枚举切割点的那些位置就行了。
所以,我们修改一下状态表示,将状态表示的第一维,设定为切割点的下标。
假设切割点的数组为cut,其中保存了所有切割点的下标,总共有p个切割点。
假设第i个切割点,对应的字符串s中的位置为x,即cut[i] = x;
那么我们用f[i][k]表示,字符串s的[0, x - 1]范围内,切割出k个子串的方案数。
由于我们打算用前缀和进行优化,所以实际的f[i][k],等于f[0][k] + f[1][k] + ... + f[i][k]
但我们需要额外添加一个切割点为n,指向字符串s最后一个位置(n - 1)之后的位置。
这样,若切割点个数设为p,则f[p - 1][k]就表示切割点cut[p - 1] = n之前的部分,切割成k个子串的方案数,也就是字符串s的[0, n - 1]的部分,切割成k个子串的方案数。
对了,由于我们存的是前缀和,所以我们实际的答案应该是f[p - 1][k] - f[p - 2][k],需要将前缀和还原一下。
// C++ 744ms
const int MOD = 1e9 + 7;
typedef long long LL;
class Solution {
public:
unordered_set<char> primes{'2', '3', '5', '7'};
// r是分割点数组的下标
// 找到curs[r]左侧的第一个分割点, 使得最后一段子串的长度>= minLength
int find(vector<int>& cuts, int r, int minLength) {
for (int i = r; i >= 0; i--) {
if (cuts[r] - cuts[i] >= minLength) return i;
}
return -1; // 未找到
}
int beautifulPartitions(string s, int k, int minLength) {
int n = s.size();
if (!primes.count(s[0]) || primes.count(s[n - 1])) return 0;
// 分割点仍然存质数的位置, 比如s[i - 1]是非质数, s[i]是质数, 则分割点存i
vector<int> cuts;
cuts.push_back(0); // 第一个位置肯定是一个分割点
for (int i = 1; i < n; i++) {
if (!primes.count(s[i - 1]) && primes.count(s[i])) cuts.push_back(i);
}
// 分割点额外存一个n, 指向字符串最后一个位置的下一个位置
cuts.push_back(n);
// 获取一下分割点的总数量
n = cuts.size();
// 开状态数组
vector<vector<int>> f(n, vector<int>(k + 1));
// cut[0] = 0, 第一个分割点前面(空串,分割成0个, 方案为1)
f[0][0] = 1;
// 外层循环分割的组数
for (int j = 0; j <= k; j++) {
// 内层循环分割点, 方便计算前缀和
for (int i = 1; i < n; i++) {
f[i][j] = f[i - 1][j];
int p = find(cuts, i, minLength);
if (p == -1 || j == 0) continue;
f[i][j] = (f[i][j] + f[p][j - 1]) % MOD;
}
}
// + MOD 后再 % MOD , 处理负数的情况
return (f[n - 1][k] - f[n - 2][k] + MOD) % MOD;
}
};
其他大神的代码:(比起上面我自己的代码优雅太多 (ㄒoㄒ))
const int N = 1010, MOD = 1e9 + 7;
class Solution {
public:
int f[N][N];
int beautifulPartitions(string s, int k, int len) {
int n = s.size();
s = ' ' + s;
unordered_set<char> s1{'2', '3', '5', '7'};
f[0][0] = 1;
for (int i = 1; i <= k; i ++ ) {
int sum = 0;
for (int j = 1; j <= n; j ++ ) {
// 累加计算前缀和
if (j >= len && s1.count(s[j - len + 1]))
sum = (sum + f[i - 1][j - len]) % MOD;
// 当结尾是非质数时, 记录答案
if (!s1.count(s[j])) f[i][j] = sum;
}
}
return f[k][n];
}
};

















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









