




 本文详细介绍如何启动Hadoop和Spark,使用Java和Scala实现WordCount示例,对比两种语言的代码量,展示Scala的简洁性。
本文详细介绍如何启动Hadoop和Spark,使用Java和Scala实现WordCount示例,对比两种语言的代码量,展示Scala的简洁性。
一:启动hadoop和spark
cd /usr/local/Cellar/hadoop/3.2.1/sbin
./start-all.sh
cd /usr/local/Cellar/spark-3.0.0-preview2/sbin
./start-all.sh
二:Java WordCount
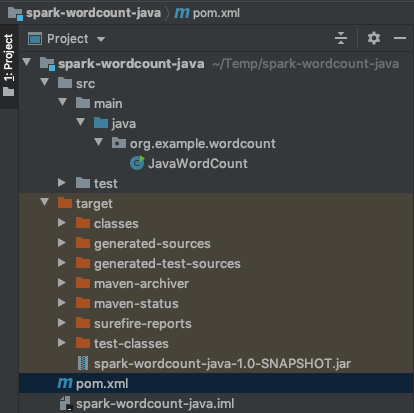
1. 引入依赖
依赖的版本号要与安装程序的版本号保持一致。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0-preview2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.6-jre</version>
</dependency>
2. word.txt
hello spark
spark sql
spark streaming
3. JavaWordCount.java
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class JavaWordCount {
public static void main(String[] args) {
// local模拟一个集群环境运行任务
// local[num],使用的线程数目去模拟一个集群
// local[*],使用本地所有有空闲的线程模拟集群,默认为2
SparkConf conf = new SparkConf().setAppName("JavaWordCount").setMaster("local");
JavaSparkContext jsc = new JavaSparkContext(conf);
// 读取文本文件内容,每一行内容作为一个元素
// [hello spark, spark sql, spark streaming]
JavaRDD<String> rdd1 = jsc.textFile("/Users/mengday/Desktop/spark/word.txt");
// 将每行文本内容通过空格分隔转为独立的单词,每个单词作为一个元素
// [hello, spark, spark, sql, spark, streaming]
JavaRDD<String> rdd2 = rdd1.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
// 映射, 将列表中的每个单词转为元组类型,将单词作为元组的第一个元素,并给一个初始值1作为元组的第二个元素。 word -> (word, 1)
// [(hello,1), (spark,1), (spark,1), (sql,1), (spark,1), (streaming,1)]
JavaPairRDD<String,Integer> rdd3 = rdd2.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
// reduce归纳,将元组中的key相同的分组,对值求和
// [(spark,3), (hello,1), (streaming,1), (sql,1)]
JavaPairRDD<String,Integer> rdd4 = rdd3.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
// 打印最终结果
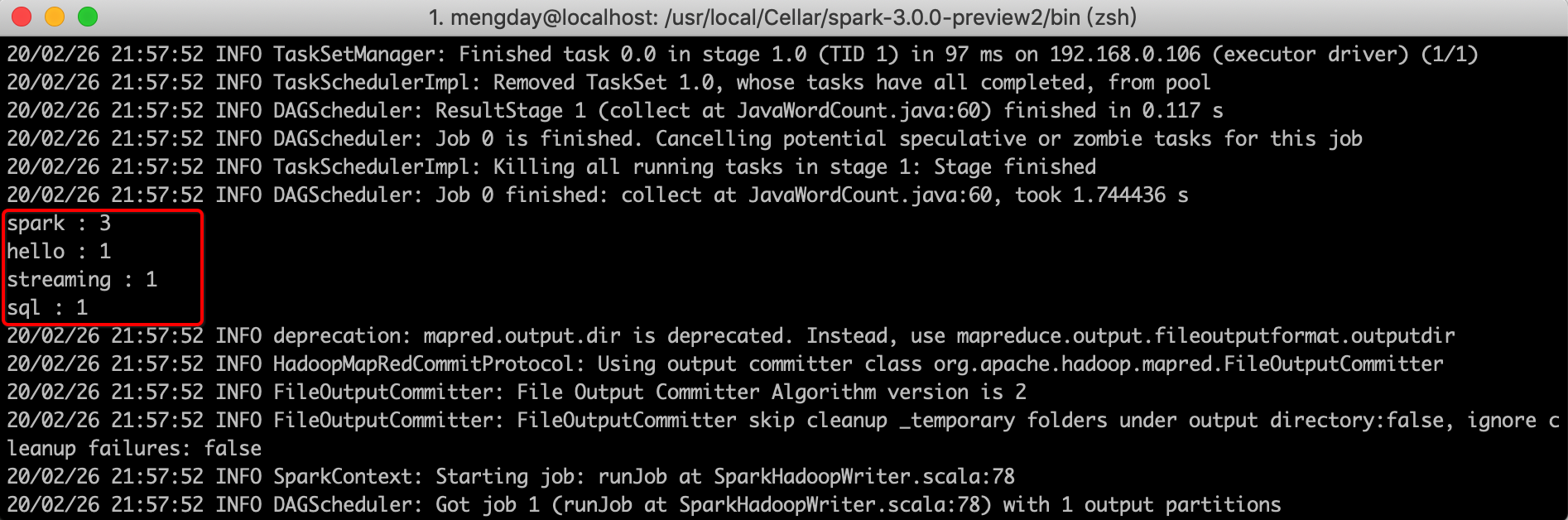
List<Tuple2<String,Integer>> list = rdd4.collect();
for(Tuple2<String, Integer> t : list){
System.out.println(t._1() + " : " + t._2());
}
// 将最终结果写到文件中
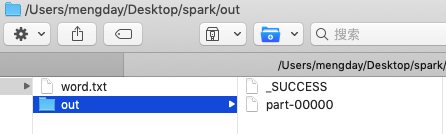
rdd4.saveAsTextFile("/Users/mengday/Desktop/spark/out");
// 将最终结果写到HDFS中
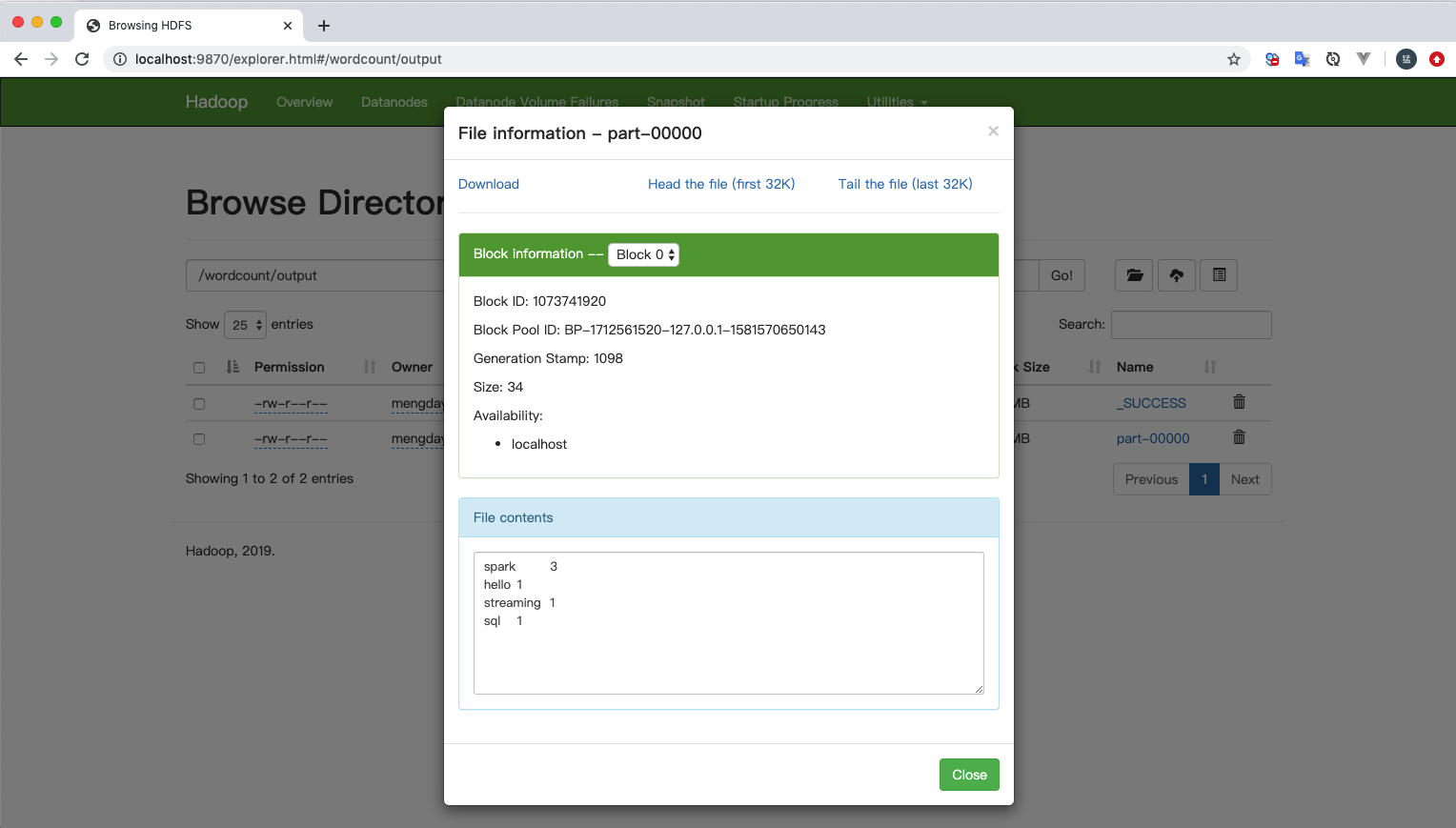
rdd4.saveAsHadoopFile("hdfs://localhost:8020/wordcount/output", String.class, Integer.class, TextOutputFormat.class);
jsc.stop();
}
}
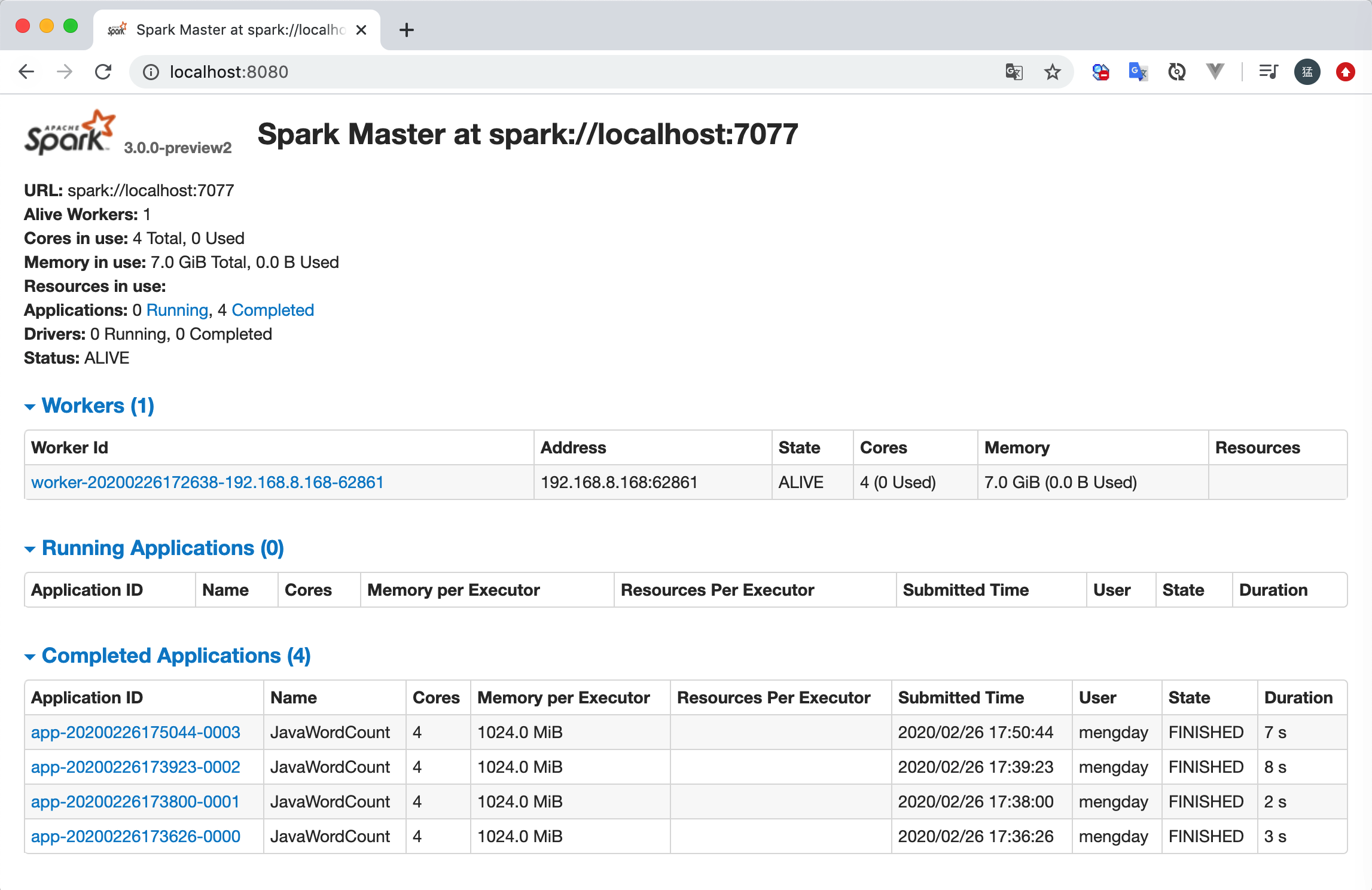
4. 运行
方式一:直接运行main方法
方式二:通过spark-submit命令执行
cd /usr/local/Cellar/spark-3.0.0-preview2/bin
./spark-submit --class org.example.wordcount.JavaWordCount ~/Temp/spark-wordcount-java/target/spark-wordcount-java-1.0-SNAPSHOT.jar
三:Scala WordCount
1. 安装或者更新Scala插件
2. 创建maven项目(scala-archetype-simple)
3. 设置Setup Scala SDK
4. 修改pom.xml中scala.version和-target:jvm-1.8
<properties>
<scala.version>2.12.10</scala.version>
</properties>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.8</arg>
</args>
</configuration>
</plugin>
</plugins>
</build>
5. 删除App类
6. 添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0-preview2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.6-jre</version>
</dependency>
7. ScalaWordCount
import org.apache.hadoop.mapred.TextOutputFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object ScalaWordCount {
def main(args:Array[String]): Unit = {
val sparkConf:SparkConf = new SparkConf().setAppName("ScalaWordCount").setMaster("local")
val sc:SparkContext = new SparkContext(sparkConf)
val file:RDD[String] = sc.textFile("/Users/mengday/Desktop/spark/word.txt")
// val result:RDD[(String,Int)] = file.flatMap(_.split(" ")).map(x => (x, 1)).reduceByKey(_ + _)
val words:RDD[String] = file.flatMap(_.split(" "))
val wordAndCount:RDD[(String, Int)] = words.map(x=>(x, 1))
val result:RDD[(String, Int)] = wordAndCount.reduceByKey(_ + _)
// 打印结果
result.collect().foreach(println)
// 将结果写到文件中
result.saveAsTextFile("/Users/mengday/Desktop/spark/out")
// 将结果写到HDFS中
result.saveAsHadoopFile("hdfs://localhost:8020/wordcount/output", classOf[String], classOf[Integer], classOf[TextOutputFormat[String, Integer]])
sc.stop()
}
}
8. 运行ScalaWordCount#main
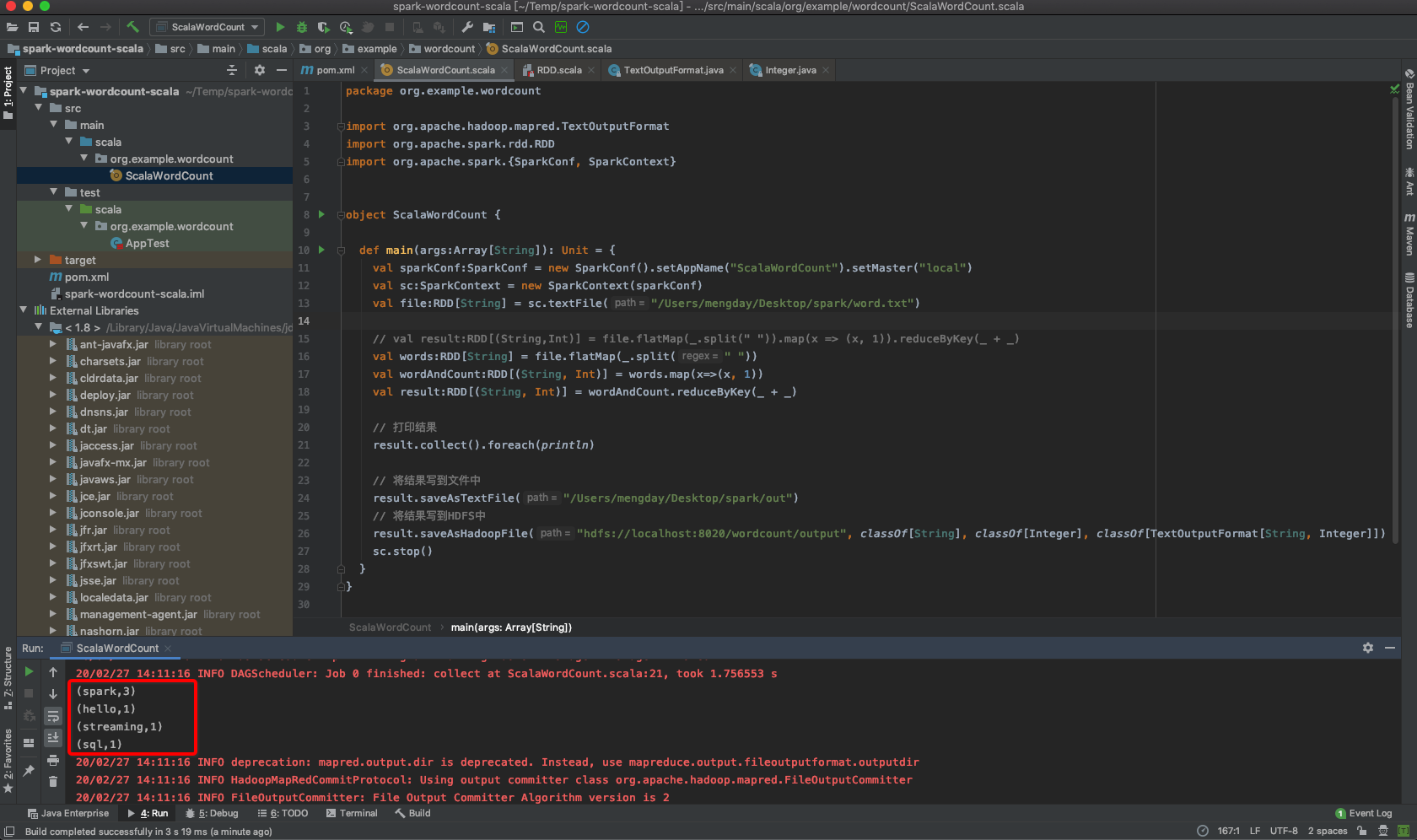
9. 命令行运行
cd /usr/local/Cellar/spark-3.0.0-preview2/bin
./spark-submit --class org.example.wordcount.ScalaWordCount ~/Temp/spark-wordcount-scala/target/spark-wordcount-scala-1.0-SNAPSHOT.jar
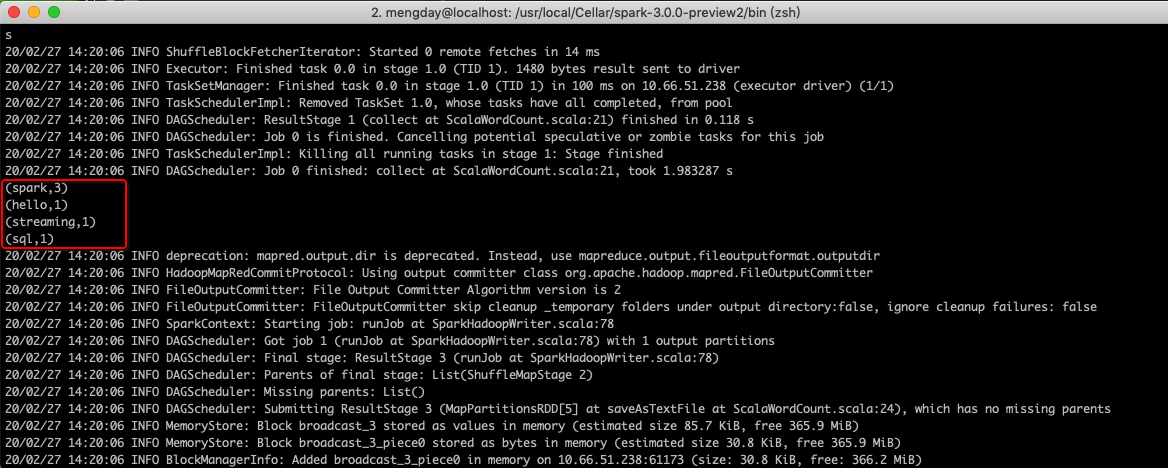
Spark提供多种语言对应的API,Scala运行在Java虚拟机上,可以与Java互操作。Spark是用Scala语言编写的,通过对比WordCount示例,Scala比Java代码量少很多。


















 7025
7025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











