







 本文深入探讨了InnoDB存储引擎的数据页结构,包括页的组成、单页数据存储方式,以及如何通过B+树实现高效的索引查询。详细介绍了B+树的构建过程,从页内数据的排序存储,到多页数据的双向链表结构,再到索引的二分查找和B+树的层次结构。此外,还简单提及了索引的分类,如聚簇索引和非聚簇索引的区别。
本文深入探讨了InnoDB存储引擎的数据页结构,包括页的组成、单页数据存储方式,以及如何通过B+树实现高效的索引查询。详细介绍了B+树的构建过程,从页内数据的排序存储,到多页数据的双向链表结构,再到索引的二分查找和B+树的层次结构。此外,还简单提及了索引的分类,如聚簇索引和非聚簇索引的区别。
目录
一、前言
mysql,一个作为java开发人员几乎无法避开的关系型数据库,把它搞懂无疑对我们的开发和面试都有着巨大的帮助。但是mysql很庞大,这次只讲mysql的索引构建(B+树),不做其他延伸。
其实在之前的工作中,也一直说想清晰地认识一下mysql的索引,也零零散散的看过一些文章,虽会使用,但其原理一直没有一个豁然开朗的那种感觉,无意间在网上找到一本书,买来一观,才对此有了一个比较清晰的认识,在此作出总结记录,留做后用。
二、innoDB的页
我们都知道,mysql默认的数据存储引擎是innoDB,而innoDB是以页作为磁盘与内存之间交互的基本单位,我们的数据也是存储在页上面的,所以要了解mysql的索引构建,首先要知道页的结构。
2.1 页的结构
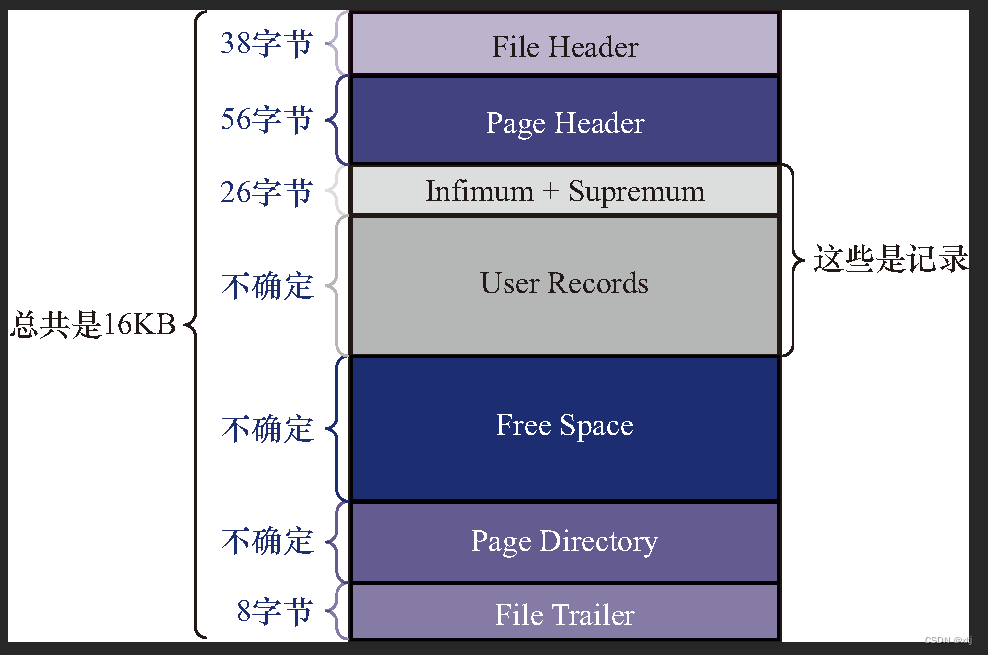
注:mysql的页默认为16k,可根据实际需要进行配置大小。
| 名称 | 中文名 | 描述 |
| File Header | 文件头部 | 文件的通用信息 |
| Page Header | 页面头部 | 数据页的专有信息 |
| Infimum+Supremum | 最小记录和最大记录 | 默认的两个虚拟记录 |
| User Records | 用户记录 | 就是我们存的数据 |
| Free Space | 空闲空间 | 还未使用的空间 |
| Page Directory | 页目录 | 后面会讲,小组的最大记录的相对位置(槽) |
| File Trailer | 文件尾部 | 校验页数据的完整性 |
以上是页的7个组成部分,列出来只是有个概念,本次不展开讲的话,只会涉及到以下几个部分。
1.File Header:存储文件的通用信息(包含一些重要属性,如:本页页号,上一页页号,下一页页号,页类型等等)。
2.Infimum+Supremum:这个是innoDB默认在每个页都会自动生成的虚拟记录(只需要知道创建了页,这两条记录也会自动创建就行,其他的后面讲)。
3.User Records:这一部分就是用来存储我们的用户数据。
4.Page Directory:innoDB会把用户数据分为n个组,每个组的最后一条为这个组的“小组长”,这个部分就是记录“小组长”的位置(下面会讲)。
2.2单页数据存储
首先,mysql页中的数据,其实是按照顺序进行存储的,也就是说,会根据某个字段的大小,从小到大对记录进行排序存储,所以mysql的设计者规定了,每页都会有一个最小记录和最大记录,这个是mysql自己默认的两条记录,也是上面我们提到的Infimum+Supremum两条虚拟记录。
那么,怎么去区分页内的这些数据呢?所以在每一行的记录中,mysql除了会存储我们用户实际的数据,还会记录一些额外的信息,如图。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









