






一、序
现有很多深度学习框架,caffe/mxnet/tf/torch等训练框架,ncnn/mace等inference框架,我等会用即可。但是会用不代表会写,别人的代码也只是设计的结果,看不到别人分析的过程,而恰恰这才是最重要的能力,所以要锻炼和提高自己写代码的能力,必要重新进行分析和设计,为此工作的意义。
二、搭建思路
此前做过网站搭建的过程:
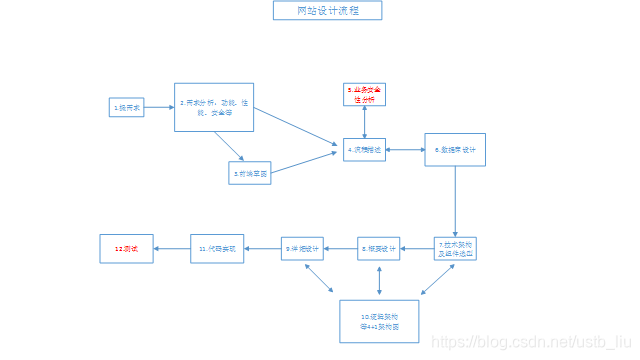
框架的搭建,与此有何不同,做完之后再分析。
那么,如何从头开始搭建一个深度学习框架呢?先凭感觉来分析一下。
首先,要确定一个问题:是训练框架还是推理框架?我想做一个训练框架。
那么,一个训练框架需要有怎样的功能?或者讲都要解决什么问题,或者讲流程是怎样的?
训练框架的目的是得到一个训练好的模型。要得到模型参数,需要先预定义一个模型,然后加载数据,进行训练,所以流程很简单,就是:预定义模型及加载--数据输入--训练---模型输出。这样就有了最初的四个模块了。
分类讨论:
0、预定义模型及加载:
这里有几个问题,模型在代码中体现,还是用文件体现?先二选一,参考caffe中在文件中定义模型的方式。
怎么加载到内存?肯定是对文件进行parse,然后对结构体/类设置参数。那么结构体都有哪些?都包含什么参数?
我们知道,caffe model文件一般会定义层及其参数,那么肯定要有layer类。参数的话,应有学习率,decay,卷积核大小,卷积核个数,卷积核参数初始化方法,输入图片大小,channel个数等;
这时,有了loadmodel 和 layer的概念。
1、数据输入:一般数据都会按照batch的形式进行训练,那么就有几个问题:从哪里加载,怎么加载,数据结构是什么。
1.1从哪里加载:初始选择有文件系统、数据库。
1.2怎么加载:
文件系统的话,都是压缩图片格式,还要在读取的时候进行解压缩操作,所以排除;
数据库读取也有两种方式,一种是全部读到内存里,一种是分步读取,明显分步读取会更好,但是要解决随机不重复读取的问题,暂时放在这里,以后具体解决。假设有了数据输入的模块叫做dataio,那么它读取到的数据是什么?一幅图片是二维的,如果是彩图,还有一个channel,那么一个batch的数据就会有四维,我们把它叫做tensor4好了,caffe里叫blob。
从而,有了dataio以及tensor4。
2、模型训练:
继续自顶向下的分析,模型的训练包含了前向计算和反向传播两个过程。
那怎么表示前向计算?从每个层来看,一旦确定它的输入,就可以直接计算出输出;而resnet带来了多个输入的问题,怎么办?
怎样将层与层之间的联系表达出来?我觉得应该用图,根据深度学习的特征,具体讲应该是有向无环图DAG,(结合反向传播的过程,正好可以用十字链表来表达×)把这个概念抽象出来,我觉得用model表示比较贴切,当然,caffe里用的叫Net。这样,Net.train(),Net.forward(),Net.backward()的语义也与人的想法符合,用起来比较自然。而loadmodel自然也应属于Net来做。
而layer的输入输出数据该怎么办表示?参考caffe,叫blob,应该在layer类中指向输入blob和输出blob。
3、模型输出:
先不管。
未完待续。水平有限,敬请指正。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









