









 本文介绍了SpringData JPA中count方法的使用,包括默认的count()方法,可解析的方法名计数,以及如何处理需要distinct的复杂统计需求。当JPA的默认方法无法满足需求时,可以通过自定义SQL来实现特定的计数操作。
本文介绍了SpringData JPA中count方法的使用,包括默认的count()方法,可解析的方法名计数,以及如何处理需要distinct的复杂统计需求。当JPA的默认方法无法满足需求时,可以通过自定义SQL来实现特定的计数操作。
通常,我们会有统计数量的需求,Jpa对一些简单统计数量的需求通过方法名就可以解析。然而对于稍微复杂的需求则无法通过方法名解析。
对于这种需求,还是需要写sql实现。
1、默认提供的count()
当我的Repository接口继承JpaRepository时,默认会继承它的一个count()方法
@Repository
public interface StudentRepository extends JpaRepository<Student, String> {
}


CrudRepository接口中有count()方法。它被解析后的sql为:
select
count(*) as col_0_0_
from
student student0_
2、根据方法名可以解析的count
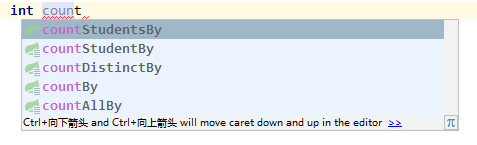
在StudentRepository中写下count会有对应提示,表示这些方法名可以被Jpa解析。那么,他们有什么区别呢?
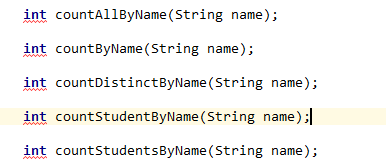
除了countDistinctByName其他4个方法对应的sql均为:
select
count(student0_.id) as col_0_0_
from
student student0_
where
student0_.name=?
countDistinctByName对应的sql为:
select
distinct count(distinct student0_.id) as col_0_0_
from
student student0_
where
student0_.name=?
也就是无论By后面的是哪个字段,count的对象都是id。所以某些需求就无法通过方法名解析实现,例如,获取唯一的名字个数
select distinct name from student;
3、“distinct 普通字段” 类需求使用sql实现

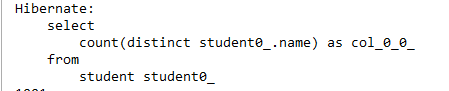
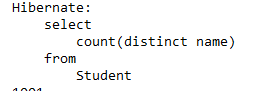
或者用原生sql


















 3582
3582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









