






在本文中,为了回答有关电影的问题,提出了一个分层存储网络(LMN),该网络分别通过静态字存储模块和动态字幕存储模块来表示帧级和剪辑级电影内容。发表于AAAI2018
文章链接:Movie Question Answering: Remembering the Textual Cues for Layered Visual Contents
一、文章引入
桥接视觉理解和人机交互是人工智能的一项艰巨任务。尽管视觉捕捉在将视觉内容与自然联系起来方面很有希望,但它通常叙述视觉内容的粗略语义,并且缺乏对视觉提示之间的不同关联进行建模的能力。视觉问答(VQA)依赖于整体场景理解来为不同层次的视觉理解找到正确的答案。针对VQA的流行方法旨在学习从图像和问题中提取的特征的特定组合的共现,为了准确地将特定的语言元素与特定的视觉内容相关联,人们提出了注意力或动态记忆机制来提高VQA的性能。
由于可以将视频视为图像的时空扩展,因此视频理解需要更好的表示形式,以便对每个帧的视觉内容和连续的视频帧之间的时间依赖性进行编码。与其他视频不同,大多数电影都有特定的背景以及拍摄风格。因此,仅通过视觉内容来理解电影的故事确实是一项艰巨的任务。另一方面,电影始终包含由演员之间的软对话构成的标准字幕,这为更好地理解电影的故事提供了可能,从而促进了自动电影问答的应用。
本文探索了如何利用电影剪辑和字幕来回答电影问题。文中建议通过分层存储网络(LMN)的静态单词存储模块和动态字幕存储模块分别对电影内容(即帧级和剪辑级层)进行分层表示。静态单词存储器包含MovieQA数据集的所有文字信息,而动态字幕存储器则包含所有字幕信息。
二、文章精读

本文提出的方法的框架如上图所示。 LMN的输入是一系列逐帧特征图{I1,I2,…,IT}和问题u, 输出是LMN预测的正确答案。
2.1 Represent Movie Frames with Static Word Memory Module
该模块的主要目的是通过静态单词存储器获得电影帧中特定区域的语义表示。该框架如下图所示。假设有一个静态单词记忆We∈R |V|×d,它可以看作是词汇量为| V |的词嵌入矩阵,将单词映射到d维的连续向量中。静态单词记忆可以通过跳跃语法模型学习。有一系列逐帧特征图{I1,I2,…,IT},它们从CNN的卷积层中提取,每个都有C×H×W的形状,其中C,H,W分别表示特征图的通道,高度以及宽度。因此,我们可以获得H×W的区域特征{lij∈RC}和i∈{1,2,…,T},j∈{1,2,…,H×W}。与直接将区域特征映射到公共空间的联合嵌入方法不同,本文使用静态单词存储器表示区域特征。首先通过vij = Wllij将区域特征映射到具有投影Wl∈Rd×C的词空间中,其中vij可以看作是第i个电影帧的第j个投影区域特征。然后,利用内积计算预计的区域特征和静态单词存储器的单词之间的相似度。公式定义为:

其中wk表示静态单词存储器We的第k行向量。 vij和wk都首先缩放为具有单位范数,因此αijk等效于余弦相似度。 然后,可以将区域特征vij替换为存储器所有单词的加权和:

其中| V |表示静态单词存储器的大小。 :=代表“更新”操作。 因此,可以通过以下方式计算帧级表示:

因为每个区域特征都是整个单词向量的加权和,所以vi可以看作是i帧的语义表示。此过程类似于图像区域上的注意力机制。 但是,LMN模型要注意每个区域特征的单词记忆。

所提出的静态单词存储器具有两个特性:
(1)静态单词存储器可以被当作一个单词嵌入矩阵,可以利用内存将单词映射到一个连续的向量中。
(2)静态单词存储器可以用来表示电影帧的区域特征。
2.2 Represent Movie Clips with Dynamic Subtitle Memory Module
该模块的主要目的是通过动态字幕存储获得影片剪辑中特定帧的语义表示。由于电影不仅包含视觉内容,还包含字幕,因此提出了动态字幕存储模块来用电影字幕(subtitle)表示影片剪辑(clips)。 假设电影帧已经作为公式(3)的输出被表示为帧级表示vi,。然后,对字幕{s1,s2,…,sN}进行类似于第一步静态单词存储器的处理:

其中,βni表示与第i帧相对应的第n个字幕的相似度,以及公式(5)表示第i帧表示被所有字幕的加权求和所代替。 剪辑级表示v可以通过对帧级表示{vi}求和而获得。 对于以视频作为唯一输入的电影问题回答的任务,公式(6)中的帧级表示{vi}是公式(3)的输出。 结果是,剪辑级别表示从单词空间转换为句子空间,因此可以获得大量的语义信息。 然后使用 (Tapaswi et al. 2016) 中的方法回答电影中的开放式答案问题,如下所示:

其中u表示问题向量,g = {g1,g2,…,g5},gh表示第h个答案。问题和答案都由静态字存储器We嵌入。注意,表示电影帧和字幕区域特征的静态单词存储器是共享的。但是,每部电影的字幕存储器都不同,因为不同的电影具有不同的字幕,因此单词存储器是静态的,而字幕存储器是动态的。并且,以上讨论的静态字存储器模型和动态字幕存储器模型都只有一个存储层。
总之,分层存储网络具有以下优点:
(1)无需学习联合嵌入矩阵,直接用静态单词存储器和动态字幕存储器分别代替了区域特征和帧级特征。分层的帧级和剪辑级表示形式包含更丰富的语义信息,并且在电影问答方面取得了良好的性能。
(2)通过利用准确的单词和字幕来代表每个区域和帧级别的特征,本文提出的方法在回答问题时获得了支持准确推理的良好特性。
(3)具有良好扩展能力的基本框架。
三、扩展框架
3.1 Multiple Hops in Static Word Memory.
如上所述,仅使用单个静态单词存储器,这意味着区域表示只能通过一个映射过程获得。在这种情况下,区域表示可能包含很多不相关的信息并且缺少一些关键内容来回答问题。 因此,根据内存网络中的多跳机制,考虑在静态单词存储器中使用多跳以获得更好的帧级语义表示。 与将第k层的输出ok和输入的uk的和作为下一层的输入的存储网络不同,本文仅使用区域的语义表示作为第t个静态单词存储器的输出, 第(t +1)个静态单词存储器的输入。 公式 (1)-(2)可以替换为:

区域表示vtij是第t个静态单词存储器的输出。 w^t +1^k是第(t +1)个静态单词存储器的第k行。 α^t+ 1~ijk~表示vt~ij~与wt +1~k~之间的余弦相似度。这里用于执行多跳的静态单词存储器是相同的,wt +1^k = wtk。 静态单词存储器由所有电影字幕中的单词组成。 因此,“静态”在这里有两个含义:(1)MovieQA数据集中的所有电影都共享单词记忆We。(2)静态单词记忆中的多次跳转期间,单词记忆We保持不变。
3.2 Update Mechanism of Dynamic Subtitle Memory
字幕包含电影中的完整对话,但是电影剪辑仅包含整个电影的某些片段,因此即使利用原始字幕的加权和来形成剪辑级别的表示形式,剪辑级别表示中仍然会包含很多不相关的信息。 为了解决这个问题,作者进行了两项改进:(1)在动态字幕存储器中使用多跳机制(来增强模块的推理能力)。
(2)更新了动态字幕存储器以删除无关信息。
从公式(6)中,可以通过动态字幕存储器获得剪辑级语义表示v,然后使用v更新动态字幕存储器。 该框架如下图所示。更新过程的计算如下:

vt是通过对第t个动态字幕存储器的输出vi求和而获得的剪辑级别表示。 并且stn是第t个动态字幕存储器的第n个句子。 γtn表示vt和stn之间的关系。 使用ReLU激活函数来忘记无关的内存并更新相对内存。更新帧级和剪辑级表示的过程可以计算如下:

此处的“动态”具有两个含义:
(1)如基本LMN中所述,每部电影的字幕存储器都不同。
(2)在具有更新机制的动态字幕存储器模块中,字幕存储器将通过片段级别的表示进行更新。

3.3 The Question-Guided Model
要使用动态字幕存储模块的输出剪辑级别的表示形式来回答问题,但是问题信息没有在动态字幕存储器中使用,因此将包含一些可以代表剪辑级电影内容但与问题无关的信息。本文提出了一种问题指导模型来参加字幕。 首先利用问题来更新字幕。然后,以问题为导向的字幕代表影片剪辑。 问题引导字幕的计算方法如下:

其中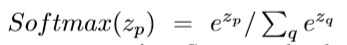 ,而u表示问题表示形式。 假设字幕和问题都由静态单词记忆库We嵌入,然后对句子的所有单词进行平均池化以得到最终的表示形式。这样,就可以根据每个字幕和问题表示的相似性获得对问题敏感的字幕。除了上述三个扩展框架之外,本文还将更新机制和问题指导模型结合在一起。最终得到的动态字幕存储器,由公式(11)更新,使用问题指导模型再次对其进行更新。所有扩展框架都不会增加任何学习参数,因此是有效的。
,而u表示问题表示形式。 假设字幕和问题都由静态单词记忆库We嵌入,然后对句子的所有单词进行平均池化以得到最终的表示形式。这样,就可以根据每个字幕和问题表示的相似性获得对问题敏感的字幕。除了上述三个扩展框架之外,本文还将更新机制和问题指导模型结合在一起。最终得到的动态字幕存储器,由公式(11)更新,使用问题指导模型再次对其进行更新。所有扩展框架都不会增加任何学习参数,因此是有效的。
四、实验结果

MovieQA数据集上扩展框架的准确性。 “ V”和“ G”分别表示VGG-16和GoogLeNet,SWM代表静态字存储器,UM表示动态字幕存储器的更新机制,QG代表问题指导模型,上标表示SWM或UM的数量。

MovieQA在线评估服务器测试集上的准确性比较。“ MN”表示内存网络。
五、主要贡献
(1)提出了一种可以利用视觉和文本信息的分层存储网络,该模型可以在帧级和剪辑级上表示具有更多语义信息的电影内容。
(2)提出了基于LMN的三个扩展框架,这些框架可以从大量外部文本中删除不相关的信息,并可以提高LMN模型的推理能力。
(3)LMN方法在MovieQA数据集上显示了电影问答的良好性能。在“视频+字幕”在线评估任务上获得了有关电影问题解答的最新技术。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









