



 提出一种名为Read-Write Memory Network (RWMN)的新型内存网络模型,用于电影故事理解的问答任务,该模型在ICCV2017上发表。RWMN通过读写网络灵活地处理复杂的电影内容,实现对电影情节的深度理解和问答。模型在MovieQA数据集上取得优异成绩,展示了在大规模多模式电影故事理解方面的潜力。
提出一种名为Read-Write Memory Network (RWMN)的新型内存网络模型,用于电影故事理解的问答任务,该模型在ICCV2017上发表。RWMN通过读写网络灵活地处理复杂的电影内容,实现对电影情节的深度理解和问答。模型在MovieQA数据集上取得优异成绩,展示了在大规模多模式电影故事理解方面的潜力。
本文提出了一个名为Read-Write Memory Network(RWMN)的无线内存网络模型来执行问答任务,以了解大规模的多模式电影故事,发表于ICCV2017,在《MovieQA:Understanding Stories in Movies through Question-Answering》的基础上进一步对电影问答问题进行了更深入的研究。
文章链接:A Read-Write Memory Network for Movie Story Understanding
一、文章引入
MovieQA是一种具有挑战性的可视化QA数据集,其模型需要理解两个小时以上的电影,并解决与电影内容和情节有关的QA问题。 MovieQA基准测试根据用来解决QA问题信息来源的不同由六个任务组成,包括视频,字幕,DVS,脚本,情节摘要和开放性信息。了解电影是一项艰巨的任务。不仅需要了解单个视频帧的内容(例如角色的动作,事件的发生位置),而且还需要推断出更多抽象的高级知识,例如角色行为的原因以及他们之间的关系。比如说,在《哈利·波特》电影中,回答一个问题(问:哈利欺骗卢修斯做了什么?A.释放多比),模型需要意识到多比是卢修斯的家养小精灵,想逃离他,与哈利有着亲密的关系,所以哈利帮助了他。其中一些信息在电影中是视觉上或文本上可观察到的,但更多的关于角色之间的关系以及事件之间的相关性这样的信息需要被推导出来。
本文的新型内存网络Read-Write Memory Network(RWMN)的重点是将定义高容量和高灵活性的内存读/写操作,为此文中提出了由多个卷积层组成的读写网络。现有的神经内存网络模型将每个内存插槽视为一个独立的块。但是,相邻的存储块通常具有很强的相关性,可以代表顺序的故事。也就是说,当人们理解一个故事时,整个故事通常被认为是一系列紧密相连的抽象事件。因此,更好的存储网络需要以块的形式读取和写入顺序存储单元,这由读取和写入网络的多个卷积层实现。
二、文章精读

上图显示了RWMN的整体结构。训练RWMN可以将具有正确表示形式的电影内容存储在内存中,响应给定查询从存储单元中提取相关信息,并从五个选择中选择正确的答案。
根据MovieQA数据集的QA格式,模型的输入为(i)整个电影的一系列视频片段和字幕对Smovie = {(v1,s1),…,(vn,sn)};(ii)电影的问题q;以及(iii)五个候选答案a = {a1,…,a5}。例如,在MovieQA的视频+字幕任务中,每个si是一个人物的对话语句,而v~i ~= {vi1,…,vim}是一个视频子镜头(即一组帧),其采样率为6 fps,在时间上与si对齐。输出是五个候选答案的置信度得分向量。
2.1 Movie Embedding
将子镜头vi和文本句子si转换为特征表示, 对于每个帧vij∈vi,首先通过应用ImageNet 上预训练的ResNet-152 来获得其特征vij。 然后,将所有帧平均池化为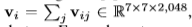 ,以表示子镜头vi。 对于每个句子si,我们首先将句子分成单词,应用预训练的Word2Vec,并使用位置编码(PE)平均池化为
,以表示子镜头vi。 对于每个句子si,我们首先将句子分成单词,应用预训练的Word2Vec,并使用位置编码(PE)平均池化为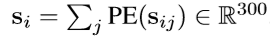 。 最后,为了获得vi和si的多峰空间嵌入,使用紧凑双线性池(CBP)得到
。 最后,为了获得vi和si的多峰空间嵌入,使用紧凑双线性池(CBP)得到
对所有n对子镜头和文本执行此过程,得到2D电影嵌入矩阵E∈Rn×4,096,作为写入网络的输入。
2.2 The Write Network
写入网络将电影嵌入矩阵E作为输入,并生成存储张量M作为输出。 写入网络的动机是,当人们理解电影时,不会将电影记做简单的语音和视觉内容序列,而是以事件或情节的形式将几个相邻的话语和场景联系在一起。 即每个存储单元需要关联相邻的电影嵌入,而不是分别存储n个电影嵌入中的每个。 为了实现将相邻嵌入项共同存储到每个插槽中的想法,文中通过改变卷积层的维度,深度和跨度,利用卷积神经网络(CNN)得出了写入网络。
对于电影嵌入矩阵了E∈Rn×4,096,首先应用参数为Wc∈R4,096×d,bc∈Rd的全连接层(FC)将每个E [i]投影到d维向量中。 全连接层减小E的维数,以使问题嵌入和答案嵌入的维数相等,这也有利于以后减少所需的卷积运算。 然后,我们使用一个由滤波器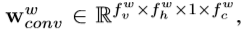 组成的卷积层:
组成的卷积层:
注意,写网络可以采用多个卷积层。 如果层数为vw,则通过递归获得M:

2.3 The Read Network
读取网络获取问题q,然后根据q和M之间的兼容性生成答案。
Question embedding首先按照2.1节的方法获得Word2Vec向量 q,然后按以下方式对其进行投影

接下来,读取网络将存储器M和嵌入u的查询作为输入,并生成置信度得分向量o∈Rd。
Query-dependent memory embedding首先将存储器M转换为依赖查询的。 它的直觉是,根据查询,必须从内存插槽中检索不同类型的信息。 例如,对于“哈利波特”电影,假设一个内存插槽包含有关哈利使用魔法的特定场景信息。,应该根据两个不同的问题来不同地读取此内存插槽。问题1:哈利穿着什么颜色? 和Q2:为什么Harry念咒语?
为了将内存M转换为与查询相关的内存Mq∈Rm×d×3,在M的每个内存单元和查询嵌入u之间应用CBP:

Convolutional memory read就像在写入网络中所做的一样,利用CNN来实现读网络。 为了正确回答电影理解的问题,重要的是将一系列场景作为一个整体进行连接和关联。 因此,文中使用CNN体系结构来访问顺序存储插槽的,通过应用滤波器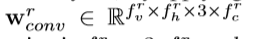 的卷积层获得构造的内存Mr。 最后,重建的内存为Mr∈Rc×d×3
的卷积层获得构造的内存Mr。 最后,重建的内存为Mr∈Rc×d×3

像在写入网络中一样,读网络也可以具有vr个卷积层堆栈。 除了分别用Mr,wrconv,br代替M,wwconv,bw之外,公式与等式(3)相同。
2.4.Answer Selection
接下来,通过将softmax应用于查询嵌入u与存储器的每个单元Mr之间的点积来计算注意力矩阵p∈Rc×3

最后,通过Mr的每个存储单元与注意力向量p之间的加权和获得输出向量o∈Rd:

接下来,获得五个答案候选句子{a}的嵌入,就像在等式(4)中对问题所做的那样,共享参数Wq和bq。 结果,计算出候选答案的嵌入g∈R5×d。
通过g与o和u的加权和之间的相似性来计算置信向量z∈R5

其中α∈[0,1]是可训练的参数。 最后,预测出置信度得分最高的答案y:y =argmaxi∈[1,5](zi)。
2.5 Training
为了训练我们的模型,作者最小化了预测z和groundtruth 独热编码zgt之间的softmax交叉熵。 所有训练参数都用Xavier方法初始化。 在实验上,选择Adagrad [5]优化器,其mini-batch大小为32,learning rate为0.001,初始累加器值为0.1。 尽管由于MovieQA数据集的规模较小,会使用尽早停止方法来避免过度拟合,但最多可以训练200个epochs。作者使用12种不同的随机初始化重复训练每个模型,然后选择成本最低的模型。
三、实验结果

MovieQA公共验证/测试数据集上的视频+字幕任务的性能比较。

MovieQA公共验证/测试数据集上所有任务的性能比较。
四、主要贡献
(1)提出了一种名为RWMN的新型内存网络,该网络使模型能够通过读写网络灵活地将更复杂和抽象的信息读写到内存插槽中。 这是将多层CNN用于存储器网络的读/写操作的首次尝试。
(2)RWMN在MovieQA基准测试的多项任务中显示出最佳的准确性。 截至ICCV2017提交截止日期(2017年3月27日23:59 GMT),RWMN在验证集中的五项任务中有四项在测试集中的六项任务中有四项达到了最佳性能。其定量和定性评估还确保读/写网络有效利用外部存储器中的高级信息,尤其是在视觉质量检查任务上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









