






一.引言
1.什么是网络爬虫?
网络爬虫(又称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。如果把互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛,如果它遇到自己需要的食物(所需要的资源),那么它就会将其抓取下来。例如百度、google等搜索引擎本质上就是超级爬虫。搜索引擎爬虫每时每刻都会在海量的互联网信息中进行爬取,爬取优质信息并收录,当用户在搜索引擎上检索对应关键词时,搜索引擎将对关键词进行分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序并将结果展现给用户。
2.网络爬虫的作用?
爬虫主要作用是抓取某个网站或者某个应用的内容,批量提取有用的价值,比如把某一个壁纸网页的所有壁纸图片抓取到本地并保存,或者搜集众多机票网站的航班价格信息做价格对比,对各种论坛、股吧、微博、公众号的舆情收集等。将爬到的数据也可以用来做数据分析,先通过对爬取的数据的清洗,抽取,转换,将数据做成标准化的数据,然后进行数据分析和挖掘,得到数据的商业价值。
3.网络爬虫的合法性
据说互联网上50%以上的流量都是爬虫创造的,也就是很多热门数据内容都是爬虫所创造的,所以可以说没有爬虫就没有互联网的繁荣。综合国内目前的法律法规来说爬虫这种技术是不违法的,因为技术本身确实是没有对错的.但使用技术的人是有对错的,如果违反法律法规制作和使用相关的爬虫肯定是会受到法律的惩处。
制作和使用爬虫的时候也需要按照一定的规则来避免风险.
- 严格遵守网站设置的robots协议,Robots 协议就是告诉爬虫,哪些信息是可以爬取,哪些信息不能被爬取,严格按照 Robots 协议 爬取网站相关信息一般不会出现问题。例如淘宝的Robots 协议
- 在使用爬虫时,不能大规模使用爬虫导致对方服务器瘫痪,这等于网络攻击,避免干扰到网站的正常运营。
- 在使用爬虫时,应审查抓取到的信息内容,如有发现隐私或者商业秘密的或者是受国家法律保护的数据,应及时及时停止爬取。
4.为何选择Python来制作网络爬虫
爬虫程序通过编程语言编写程序请求网络地址,根据响应的内容进行解析采集数据,需要注意的是并不是只有Python能制作爬虫程序,例如JAVA,PHP等通用语言都可以制作Python程序。之所以python爬虫程序比较常见,是因为Python的语法比较简单,而且有很多第三方库为Python爬虫提供支持,可以用比较少的代码实现爬虫。
二.模拟请求获得网页数据
Python中的两个内置模块(urllib2和urllib),来实现HTTP请求功能,不过功能比较简单,除了不用额外添加依赖包以外的优点以外,并没有其他的优势。目前在Python中使用比较多的还是Requests实现HTTP请求的方式,也是在Python爬虫开发中最为常用的方式。Requests实现HTTP请求非常简单,操作更加人性化。
1.Requests安装
Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库。由于Python没有自带该库所以我们在使用之前需要先进行安装。
通过pip安装:
pip install requests
也可以通过下载源码安装。
2.Requests发送请求
常见的请求方法都支持 get、post、put、delete。
import requests
response = requests.get('http://www.baidu.com') # 使用get 请求
response = requests.post('http://www.baidu.com') # 使用post 请求
response = requests.put('http://www.baidu.com') # 使用put 请求
response = requests.delete('http://www.baidu.com') # 使用delete 请求
3.Requests使用get请求传递参数
- 使用?和&拼接。
import requests
response = requests.get("http://www.baidu.com?key1=value1&key2=value2")
- requests提供了params关键字参数来传递参数。
import requests
parameter = {
"key1":"value1",
"key2":"value2"
}
response = requests.get("http://www.baidu.com",params = parameter)
- 可以将一个列表作为值传入。
import requests
parameter = {
"key1":"value1",
"key2":["value2-1","value2-1"]
}
response3 = requests.get("http://www.baidu.com",params = parameter)
4.Requests使用Post请求传递参数
- 如果服务器要求发送的数据是表单数据,则可以指定关键字参数 data。这个data参数可以通过字典构造成,这样对于发送post请求就非常方便。
import requests
payload = {
"key1":"value1",
"key2":"value2"
}
response = requests.post("http://www.baidu.com",data = payload)
还可以为 data 参数传入一个元组列表:
import requests
payload = (("key1","value1"),("key1","value2"))
response = requests.post("http://www.baidu.com",data = payload)
- 如果要求传递 json 格式字符串参数,则可以使用 json 关键字参数,参数的值都可以字典的形式传过去。
import requests
payload = {
"key1": "key1"
}
response = requests.post('http://www.baidu.com', json=payload)
5.Requests使用定制请求头
请求添加 HTTP 头部 Headers,只要传递一个 字典 给 headers 关键字参数就可以了。
import requests
new_headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"
}
response = requests.get("http://www.baidu.com",headers = new_headers)
6.Requests使用添加代理
如果同一个ip在短时间频繁访问一个网站,很容易被服务器发现将其拉入黑名单,因此需要添加代理。
mport requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://www.baidu.com", proxies=proxies)
7.Requests使用获取响应数据
Requests请求以后会返回 Response 对象,Response 对象是对服务端返回给浏览器的响应数据的封装,响应数据中主要元素包括:状态码、原因短语、响应首部、响应 URL、响应 encoding、响应体等等。
import requests
response = requests.get('http://www.baidu.com')
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) # 以文本形式打印网页源码
print(response.content) # 以字节流形式打印
三.通过抓包分析网页结构
通过上文我们了解到通过Requests可以模拟网络请求拿到网页数据。接下来我们就需要对网页数据进行分析它的结构和规律以便对网页数据进行解析。我们可以这么理解浏览器打开网页的过程就是爬虫获取数据的过程,对于静态网页而言两者获取到的结果是一样的。对于动态网页而言,由于很多动态网页都采取了 异步加载技术 (Ajax),会导致很多时候抓取到的源代码和网站显示的源代码不一致(这个下文会说到)。通过浏览器自带元素审查可以帮助分析页面,浏览器可以通过F12调出抓包功能。
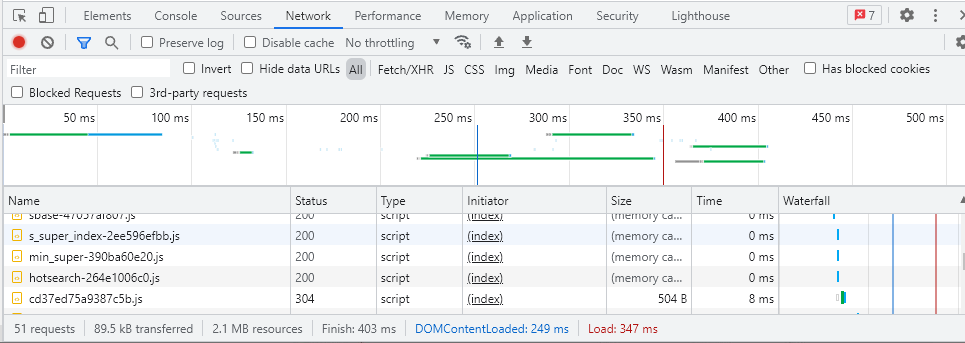
- 左上角箭头 用来点击查看网页的元素如果打开我们将鼠标移动到网页元素上面就会自动展开对应的html元素代码。
- 第二个手机、平板图标是用来模拟移动端显示网页
- Elements 查看渲染后的网页标签元素(包括异步加载的图片、数据等)的完整网页的html,不一定是最初获得的html文件。
- Console 查看JavaScript的console log信息
- Sources 显示网页源码、CSS、JavaScript代码
- Network 查看所有加载的请求
当然除了浏览器自带的抓包功能我们还可以使用如Fidder(Windows建议) 和 Charles(Mac建议)等第三方抓包工具。
四.解析网页数据
上说说到我们通过抓包工具分析了我们请求到的网页。下面就需要对网页进行解析,对于 HTML 类型的页面来说,常用的解析方法其实无非那么几种,正则、XPath、CSS Selector,BeautifulSoup库,对于某些接口返回的数据,常见的可能就是 JSON、XML 类型,使用对应的库进行处理即可。
| \ | 正则regex | xpath | beautifulsoup |
|---|---|---|---|
| 学习难度 | 难 | 中 | 简单 |
| 代码量 | 小 | 较少 | 较多 |
| 解析速度 | 快 | 较快 | 较快 |
| 场景 | 广泛 | 专一 | 专一 |
1. 使用Re(正则表达式)解析网页
正则表达式又称规则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
2. 使用Xpath方式解析网页
XPath全称为XML Path Language 一种小型的查询语言 最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。完全可以使用 XPath 做相应的信息抽取。
它所具备的优点:
- 可在XML中查找信息
- 支持HTML的查找
- 通过元素和属性进行导航
python自带的Xpath方式->lxml库,它底层由C语言实现,支持XML和HTML的解析,使用 XPath表达式 定位结点,解析效率非常高。
(1)Xpath简单使用
- 实例化一个etree对象,把将要解析的页面源码加载到该对象中
- 使用该对象中的xpath方法结合xpath表达式进行标签的定位和数据提取
from lxml import etree
selector=etree.HTML(源码) #将源码转化为能被XPath匹配的格式
selector.xpath(表达式) #返回为一列表
(2)Xpath的语法
- 选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
|表达式|描述|
|-|-|
|nodename |选取此节点的所有子节点。|
|/ |从根节点选取(取子节点)。|
|// |从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。|
|. |选取当前节点。|
|… |选取当前节点的父节点。|
|@ |选取属性。|
菜鸟学院XPath 教程
当然我们也可以借助Chorme的F12控制调试台或者Chorme插件来方便的获取到元素的Xpath路径,将其复制到我们的爬虫脚本中。
3. 使用BeautifulSoup库解析网页
BeautifulSoup就是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。
(1)BeautifulSoup使用步骤
- 实例化一个BeautifulSoup对象,必须把即将被解析的页面源码加载到该对象中
- 调用该对象中相关的属性或方法进行标签的定位和内容的提取
(2)BeautifulSoup配置解析器
Beautiful Soup在解析时实际上依赖解析器,它除了支持Python标准库中的HTML解析器外,还支持一些第三方解析器(比如lxml)。
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库、执行速度适中、文档容错能力强 | Python 2.7.3及Python 3.2.2之前的版本文档容错能力差 |
| xml HTML解析器 | BeautifulSoup(markup, “lxml”) | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML解析器 | BeautifulSoup(markup, “xml”) | 速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
五.储存爬虫爬取到的数据
在使用工具解析到网页上的数据后,要想办法把数据存储起来,这也是网络爬虫的最后一步。存储,即选用合适的存储媒介来存储爬取到的结果。
- 文件,如 JSON、CSV、TXT、图⽚、视频、⾳频等,常用的一些库有 csv、xlwt、json、pandas、pickle、python-docx 等。
- 数据库,分为关系型数据库、非关系型数据库,如 MySQL、MongoDB、HBase 等,常用的库有 pymysql、pymssql、redis-py、pymongo、py2neo、thrift。
- 云存储,某些媒体文件可以存到如七⽜牛云、又拍云、阿里云、腾讯云、Amazon S3 等,常用的库有 qiniu、upyun、boto、azure-storage、google-cloud-storage 等。
六.爬取前端渲染的网页数据
有时通过爬虫获取的网页源码不能在html代码里面找到想要的数据,但是通过浏览器打开的网页上面却有这些数据。这是因为浏览器通过ajax技术异步加载了这些数据。要了解这其中的原理我们首先要知道html的渲染方式。网页常见的有两种渲染页面的方式:一种是服务端渲染,一种是前端渲染。
1.服务器端渲染网页
在互联网早期,用户使用浏览器浏览的都是一些没有复杂逻辑的、简单的页面,这些页面都是在后端将html拼接好的,然后返回给前端完整的html文件,浏览器拿到这个html文件之后就可以直接解析展示了,这就是服务器渲染网页了。
2.前端渲染网页
随着前端页面的复杂性提高,前端就不仅仅是普通的页面展示了,也可能添加了更多功能性的组件,复杂性更大,另外,随着ajax的兴起,使得业界开始推崇前后端分离的开发模式,即后端不提供完成的html页面,而是提供一些api使前端可以获取到json等数据,然后前端拿到json等数据之后再在前端进行html页面的拼接,然后展示在浏览器上,这就是前端渲染。
这样做的好处是前后端代码分离,可以让前端更专注于UI的开发,后端专注于逻辑的开发。也就是说页面的主要内容由 JavaScript 渲染而成,真实的数据是通过 Ajax 接口等形式获取的,比如淘宝、微博手机版等等站点就是这种方式实现的。
ajax全称叫Asynchronous JavaScript and XML,意思是异步的 JavaScript 和 XML。ajax是现有标准的一种新方法,不是编程语言,可以在不刷新网页的情况下,和服务器交换数据并且更新部分页面内容,不需要任何插件,只需要游览器允许运行JavaScript就可以。
而传统的网页(不使用ajax的)如果需要更新页面内容,就需要重新请求服务器,返回网页内容,重新渲染刷新页面。当访问很多列表网页时,鼠标不断向下滑,数据不断的更新而http网址没有变化,那么这个网页就利用了ajax异步加载技术.
3.判断网页是前端渲染还是服务端渲染
审查浏览器源代码,如果能看到页面上展示的数据,则说明是服务器端渲染,看不到则就是前端渲染。
4.爬取前端渲染网页数据
(1.)爬取服务器端渲染的网页的方法
上文重要讲的就是服务器端渲染的网页的爬取方式,可以用一些基本的 HTTP 请求库就可以实现爬取,如 urllib、urllib3、pycurl、hyper、requests、grab 等框架,其中应用最多的可能就是 requests 了。
(2.)爬取前端端渲染的网页的方法
上文说到随着AJAX技术不断的普及,以及现在Vue、AngularJS这种Single-page application框架的出现,现在js渲染出的页面越来越多。对于爬虫来说,这种页面仅仅提取HTML内容,往往无法拿到有效的信息。
那么如何处理这种页面,总的来说有两种做法:
- 通过分析AJAX请求,因为js渲染页面的数据也是通过接口从后端拿到的,而且基本上都是AJAX获取,所以分析AJAX请求,找到对应数据的请求,我们就可以通过请求模拟拿到数据进行分析。
- 在抓取阶段,在爬虫中内置一个浏览器内核,执行js渲染页面后,再抓取网页内容。对应的工具有Selenium、HtmlUnit或者PhantomJs。(Selenium是一个 自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作, 同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。)
对于一些网页,甚至还有一些js混淆的技术,这个时候,使用浏览器模拟抓取的的方式基本是万能的,但是这些工具都存在一定的效率问题,因为要依赖于浏览器进行操作.
5.Selenium简介
Selenium 是一个用于web应用程序自动化测试的工具,直接运行在浏览器当中,支持chrome、firefox等主流浏览器。可以通过代码控制与页面上元素进行交互(点击、输入等),也可以获取指定元素的内容。
例如:
通过Selenium运行Chorme访问百度并且通过代码将关键字输入到搜索框进行搜索
- 通过pip安装selenium
pip install selenium
- 编写python脚本
# 导包
from selenium import webdriver
#定义url
url = "https://www.baidu.com/"
#实例化驱动
chrom = webdriver.Chrome()
#发起get请求
chrom.get(url)
#使用选这起完成元素的捕获
search = chrom.find_element_by_id("kw")
#发送数据请求
search.send_keys("python")
#使用选择器完成元素的捕获
submit = chrom.find_element_by_id("su")
#点击触发
submit.click()
6.PhantomJS简介
上文中使用Selenium爬取网页还必须依赖一个外部的浏览器,那么能不能内置一个浏览器来完成这个功能能?PhantomJS 是一个无界面的,可脚本编程的 WebKit 浏览器引擎。它原生支持多种 web 标准:DOM 操作,CSS 选择器,JSON,Canvas 以及 SVG。可以理解为无界面的浏览器。配合selenium使用,就可以无需依赖额外的浏览器,来实现可视化爬虫的功能.
注意,目前Selenium 貌似已经放弃对PhantomJS的支持了。
七.爬虫的攻防
1.通过限制仅浏览器能访问
通过浏览器进行网站访问时,都会携带user-agent信息。很多网站都会建立 user-agent白名单,只有属于正常范围的user-agent才能够正常访问。而在通过请求时,携带user-agent信息并不是浏览器的user-agent信息,因此就会被拒绝访问。
爬虫解决方案:
可以在浏览器的请求内复制完整的请求头。伪装成浏览器来进行爬取.
herder={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Upgrade-Insecure-Requests':'1'
}
url='https://www.baidu.com'
request=requests.get(url,headers=herder)
2.通过限制IP访问
IP 限制是很常见的一种反爬虫的方式。服务端在一定时间内统计 IP 地址的访问 次数,当次数、频率达到一定阈值时返回错误码或者拒绝服务。
爬虫解决方案:
- 通过添加定时器:随机几秒延迟,不超过服务器的阈值,简单模拟人的访问频率。
- 使用代理服务器:大部分语言的请求,都提供了proxy的api。使用代理后,就可避开ip的限制了。所以我们反爬虫时尽力用非ip方式判断是不是用了proxy在爬取服务器。
例如:
url='https://www.baidu.com'
#ip代理池,放在本地获取通过网络获取.
proxies = ["192.168.0.1","192.168.0.2","192.168.0.3","192.168.0.4"]
#随机取出一个Ip
proxie=rondom.randint(0,len(proxies))
#请求添加代理
request=requests.get(url,headers=herder,proxies=proxies)
3.通过登录限制
登录限制是一种更加有效的保护数据的方式。网站或者 APP 可以展示一些基础的数据,当需要访问比较重要或者更多的数据时则要求用户必须登录。同时浏览器会保持一个session会话,而一般的request模块中,并不能携带session。
爬虫解决方案:
- 如果是session保存登录状态的,使用带session的模块。比如python的requests或者使用headless。
- 如果使用令牌的方式验证登录情况则模拟登录拿到登录的令牌进行操作.
4.通过验证码限制
验证码是一种非常常见的反爬虫方式。服务提供方在 IP 地址访问次数达到一定 数量后,可以返回验证码让用户进行验证。
爬虫解决方案:
- 使用第三方平台接入,手工在线破解验证码。
- 使用机器学习框架,破解验证码。
5.页面使用Ajax异步加载
前文分析过使用Selenium+PhantomJS或者是抓包分析AJAX请求,然后再进行爬取。
八.加速爬虫
1.通过多线程加速爬虫
通过多线程提升爬虫效率。(有兴趣的可以找相关资料查阅,这里不做详细讲解)
2.通过分布式爬虫提升效率
通过将爬虫部署到不同的主机上组成集群,提升爬虫的效率。(有兴趣的可以找相关资料查阅,这里不做详细讲解)
九.爬虫框架
如果是比较小型的爬虫需求,直接使用requests库 + bs4就解决了,再麻烦点就使用selenium解决js的异步加载等问题。相对比较大型的需求才使用框架,主要是便于管理以及扩展等。
1.Scrapy爬虫框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
2.PySpider爬虫框架
Pyspider
是一个用python实现的功能强大的网络爬虫系统,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器,
能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。
十.App内容爬取
1.通过网络抓包获取接口再爬取数据
App几乎都是请求后端接口进行本地渲染的,因此我们通过抓包工具就可以抓取到需要的内容。例如
fiddler
charles
2.利用appium自动控制移动设备并抓取数据
1.安装JDK环境和Android环境
安装配置appuim首先需要配置好JDK环境和Android Sdk环境。这两点不必多说,网上面大把的相关教程。
2.安装appium环境
下载appium-desktop文件,点击进行安装。
3.配置appium
- 安装好appium,打开程序,需要进行配置,host与port默认即可。
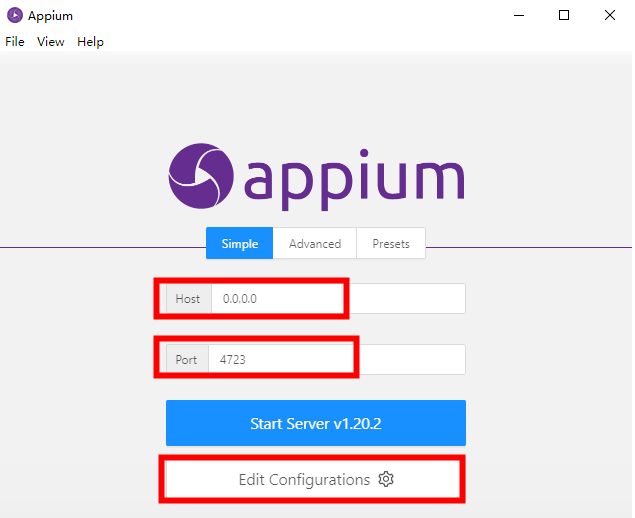
- 配置JDK环境和Android Sdk环境。
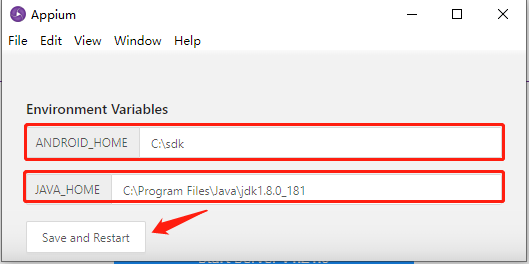
填写Android_home及Java_home后,Save and Restart, - 重启以后回到主界面,点击Start Server vX.X.X按钮。进入控制台日志界面,看到Appium REST http interface listener started on 0.0.0.0:4723就表示启动成功了。
接着点击“start inspector session”进行配置。
- 配置inspector
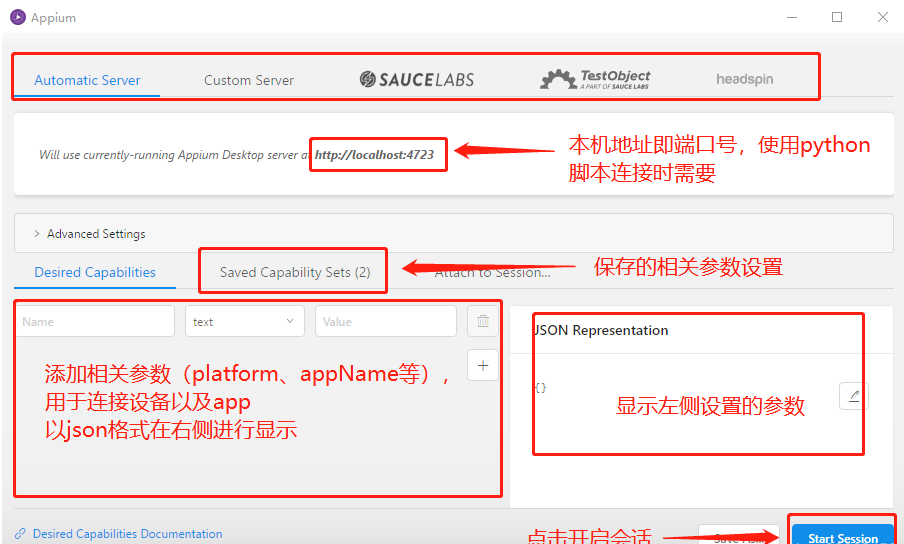
重点是要配置相关参数可以通过键值对进行配置也可以通过右侧的Json文件进行配置:
- platformName:声明是ios还是android系统。
- platformVersion:Android内核版本号,可通过命令adb shell getprop ro.build.version.release查看。
- deviceName:连接的设备名称,通过命令adb devices -l中model查看。
- appPackage:apk的包名。
- appActivity:apk的launcherActivity,通过命令adb shell dumpsys activity | findstr “mResume”查看(需先打开手机应用)。
Json配置文件示例:
{
“platformName”: “Android”,
“platformVersion”: “8.0.0”,
“appPackage”: “com.example.myapplication”,
“appActivity”: “.MainActivity”
}
- 配置完成以后点击start session按钮,进入到操作面板功能中。
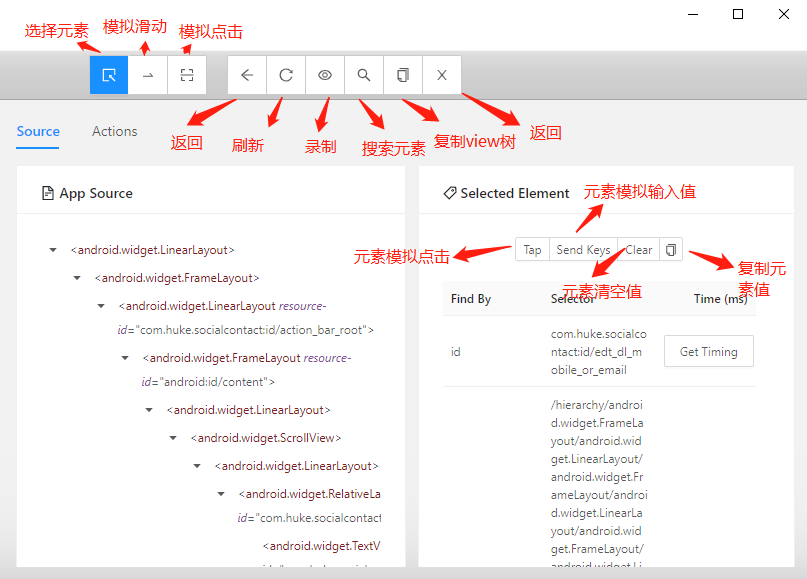

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









