



realnet torch代码训练过程报错及解决
背景
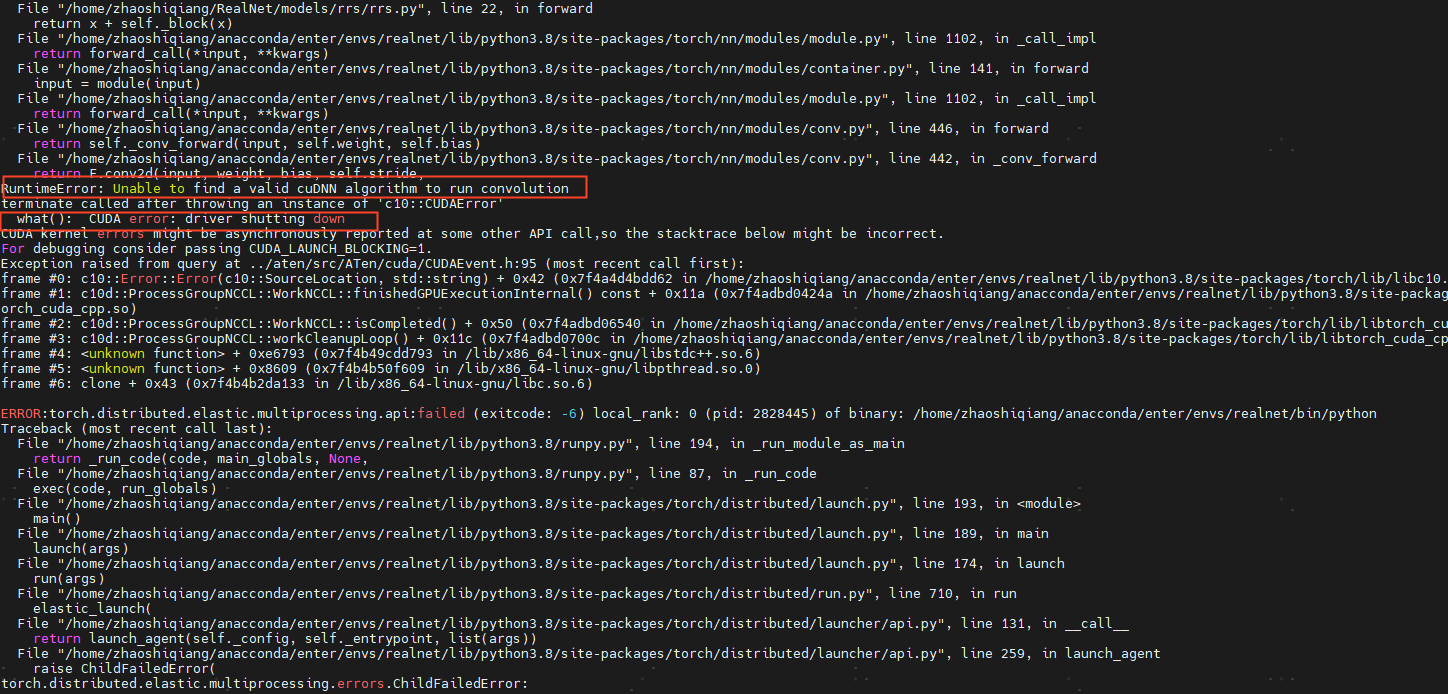
在使用realnet的官方代码进行训练时报错如下,使用的命令为,采用了分布式DDP,不过本地只用了1张显卡:
python -m torch.distributed.launch --nproc_per_node=1 train_realnet.py --dataset VisA --class_name candle
网络参数等均采用的Visa下的realnet.yaml文件中的参数,本地显卡显存为24G,直接运行后出现这个错误
File "/home/zhaoshiqiang/anacconda/enter/envs/realnet/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 446, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/home/zhaoshiqiang/anacconda/enter/envs/realnet/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 442, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
terminate called after throwing an instance of 'c10::CUDAError'
what(): CUDA error: driver shutting down
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Exception raised from query at ../aten/src/ATen/cuda/CUDAEvent.h:95 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x42 (0x7f4a4d4bdd62 in /home/zhaoshiqiang/anacconda/enter/envs/realnet/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #1: c10d::ProcessGroupNCCL::WorkNCCL::finishedGPUExecutionInternal() const + 0x11a (0x7f4adbd0424a in /home/zhaoshiqiang/anacconda/enter/envs/realnet/lib/python3.8/site-packages/torch/lib/libt
orch_cuda_cpp.so)
frame #2: c10d::ProcessGroupNCCL::WorkNCCL::isCompleted() + 0x50 (0x7f4adbd06540 in /home/zhaoshiqiang/anacconda/enter/envs/realnet/lib/python3.8/site-packages/torch/lib/libtorch_cuda_cpp.so)
frame #3: c10d::ProcessGroupNCCL::workCleanupLoop() + 0x11c (0x7f4adbd0700c in /home/zhaoshiqiang/anacconda/enter/envs/realnet/lib/python3.8/site-packages/torch/lib/libtorch_cuda_cpp.so)
frame #4: <unknown function> + 0xe6793 (0x7f4b49cdd793 in /lib/x86_64-linux-gnu/libstdc++.so.6)
frame #5: <unknown function> + 0x8609 (0x7f4b4b50f609 in /lib/x86_64-linux-gnu/libpthread.so.0)
frame #6: clone + 0x43 (0x7f4b4b2da133 in /lib/x86_64-linux-gnu/libc.so.6)
解决办法
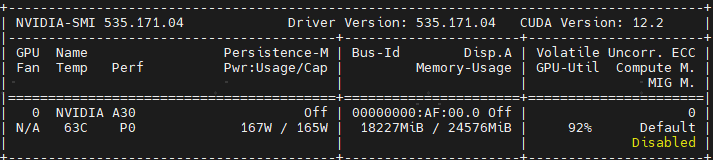
将batch size将原来的16修改为8后,即可正常运行了,运行期间显存占用约为18G,nvidia-smi显示如下:



















 4498
4498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











