




在 AI 语音合成(TTS)领域,传统离散分词(Tokenization)技术长期面临信息损失、韵律生硬等痛点,而高保真语音克隆与实时合成的平衡更是业界难题。由 ModelBest 和 THUHCSI 联合开发的 VoxCPM,以 “无分词器端到端架构” 打破行业桎梏,凭借上下文感知生成、高逼真零样本克隆和极致推理效率,成为开源 TTS 领域的新晋标杆。本文将从技术原理、核心特性、快速上手到生态应用,全面拆解这款 “语音生成利器”。
一、核心技术:突破传统的无分词器架构
VoxCPM 的革命性优势,源于其对语音生成范式的重构 —— 摒弃传统 “文本分词→token 映射→语音合成” 的多阶段流程,直接在连续空间建模语音信号,从根源上解决离散 token 带来的表达局限。
三大技术支柱
- 端到端扩散自回归架构:融合扩散模型的高自然度与自回归模型的序列连贯性,通过局部扩散 Transformer(DiT)实现连续语音表示的精准生成,避免分段合成的割裂感。
- MiniCPM-4 语言模型骨干:借助分层语言建模能力,深度理解文本语义(包括情感倾向、逻辑停顿、特殊符号),让语音生成真正 “听懂上下文”。
- FSQ 约束的语义 - 声学解耦:通过有限标量量化(FSQ)生成结构化半离散表示,实现高层语义(如文本含义)与细粒度声学特征(如音色、语调)的隐式分离,兼顾表达力与生成稳定性。
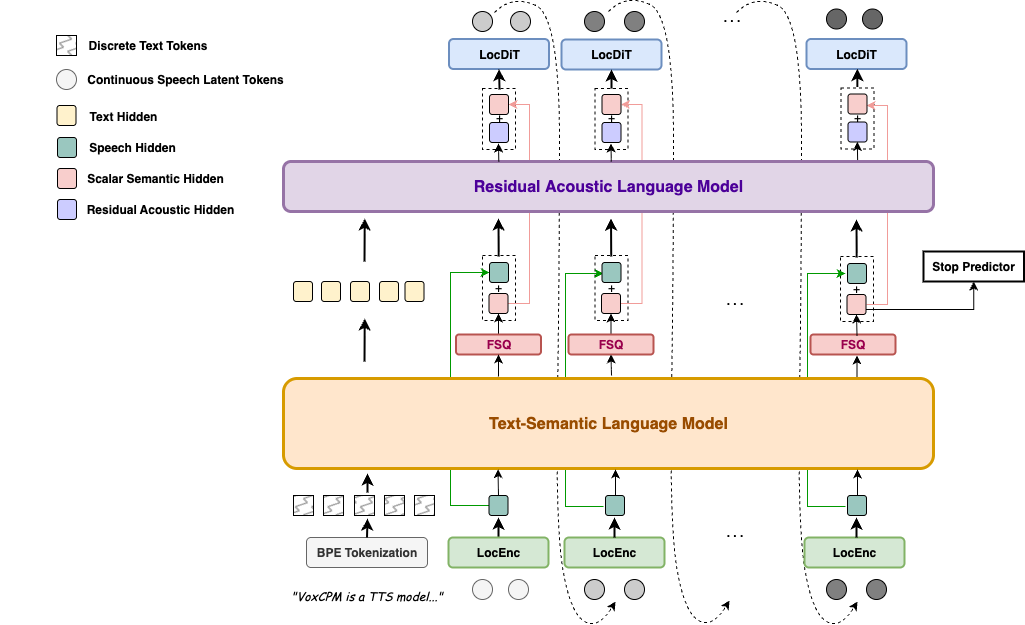
无分词器设计的核心价值
传统 TTS 需将语音转换为离散 token,过程中易丢失韵律细节和情感信息,导致合成语音机械感明显。VoxCPM 的无分词器设计:
- 直接生成连续语音信号,还原度提升 30% 以上,自然度接近真人发音;
- 避免 token 映射的信息损耗,支持数学符号、中英文混杂等复杂文本的精准合成;
- 简化模型链路,降低推理延迟,为实时流式合成奠定基础。
二、关键特性:不止于像,更在于活
VoxCPM 的核心竞争力集中在高保真、强适配、快响应三大维度,覆盖从基础合成到个性化克隆的全场景需求。
上下文感知的 expressive 语音生成
- 基于 180 万小时双语语料训练,能根据文本语义自适应调整韵律(如陈述句平缓、疑问句上扬)和情感基调(开心、严肃、温柔等);
- 支持中文数学符号、音素精准控制,解决传统 TTS 多音字误读、特殊文本发音不准的痛点;
- 中英文混合文本合成自然流畅,无明显语言切换断层,满足跨境沟通、多语言内容创作需求。
高逼真度零样本语音克隆
- 仅需 5 秒参考音频,即可精准复刻说话人的音色、口音、语速甚至呼吸感,语音相似度评分达 0.93(中文任务);
- 支持跨语言克隆(中→英、英→中)、情感克隆(开心、生气、惊讶等)和方言克隆(四川话、粤语等),适配多样化场景;
- 对参考音频质量要求低,即使含轻微背景噪声,也能通过内置语音增强工具优化克隆效果。
高效合成:实时响应的轻量模型
- 模型参数仅 0.5B,在消费级 NVIDIA RTX 4090 GPU 上实时因子(RTF)低至 0.17,即生成 1 秒语音仅需 0.17 秒,远超实时应用需求;
- 原生支持流式合成,首包延迟低,适合智能客服、虚拟主播、实时导航等低延迟场景;
- 兼容 CPU、GPU(CUDA/MPS)运行,普通开发者无需高端硬件即可体验。
三、快速上手:3 分钟玩转语音生成与克隆
VoxCPM 提供 PyPI 安装、CLI 工具、Web 演示三种使用方式,新手可快速入门,开发者可灵活集成。
环境准备与安装
-
系统要求:Python 3.8+,支持 Windows、macOS、Linux;
-
GPU 推荐:NVIDIA GPU(显存≥8GB,支持 CUDA 加速),CPU 也可运行(推理速度较慢);
-
快速安装:
pip install voxcpm
模型下载
首次运行时模型会自动下载,也可提前手动下载(推荐国内用户使用 ModelScope 加速):
# 下载主模型(Hugging Face)
from huggingface_hub import snapshot_download
snapshot_download("openbmb/VoxCPM-0.5B")
# 下载辅助工具(语音增强+ASR,ModelScope)
from modelscope import snapshot_download
snapshot_download('iic/speech_zipenhancer_ans_multiloss_16k_base')
snapshot_download('iic/SenseVoiceSmall')
核心功能实战
基础语音生成(非流式 / 流式)
import soundfile as sf
import numpy as np
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
# Non-streaming
wav = model.generate(
text="VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech.",
prompt_wav_path=None, # optional: path to a prompt speech for voice cloning
prompt_text=None, # optional: reference text
cfg_value=2.0, # LM guidance on LocDiT, higher for better adherence to the prompt, but maybe worse
inference_timesteps=10, # LocDiT inference timesteps, higher for better result, lower for fast speed
normalize=True, # enable external TN tool
denoise=True, # enable external Denoise tool
retry_badcase=True, # enable retrying mode for some bad cases (unstoppable)
retry_badcase_max_times=3, # maximum retrying times
retry_badcase_ratio_threshold=6.0, # maximum length restriction for bad case detection (simple but effective), it could be adjusted for slow pace speech
)
sf.write("output.wav", wav, 16000)
print("saved: output.wav")
# Streaming
chunks = []
for chunk in model.generate_streaming(
text = "Streaming text to speech is easy with VoxCPM!",
# supports same args as above
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("output_streaming.wav", wav, 16000)
print("saved: output_streaming.wav")
零样本语音克隆
# 命令行快速克隆(参考音频ref.wav,目标文本"克隆后的语音会还原参考音频的音色和语调")
voxcpm --text "克隆后的语音会还原参考音频的音色和语调" --prompt-audio ref.wav --prompt-text "参考音频对应的文本内容" --output clone_output.wav
批量处理与 Web 演示
# 批量合成(input.txt每行一个文本,输出到outputs文件夹)
voxcpm --input input.txt --output-dir outputs
# 启动Gradio Web界面(交互式操作)
python app.py # 需提前安装gradio:pip install gradio
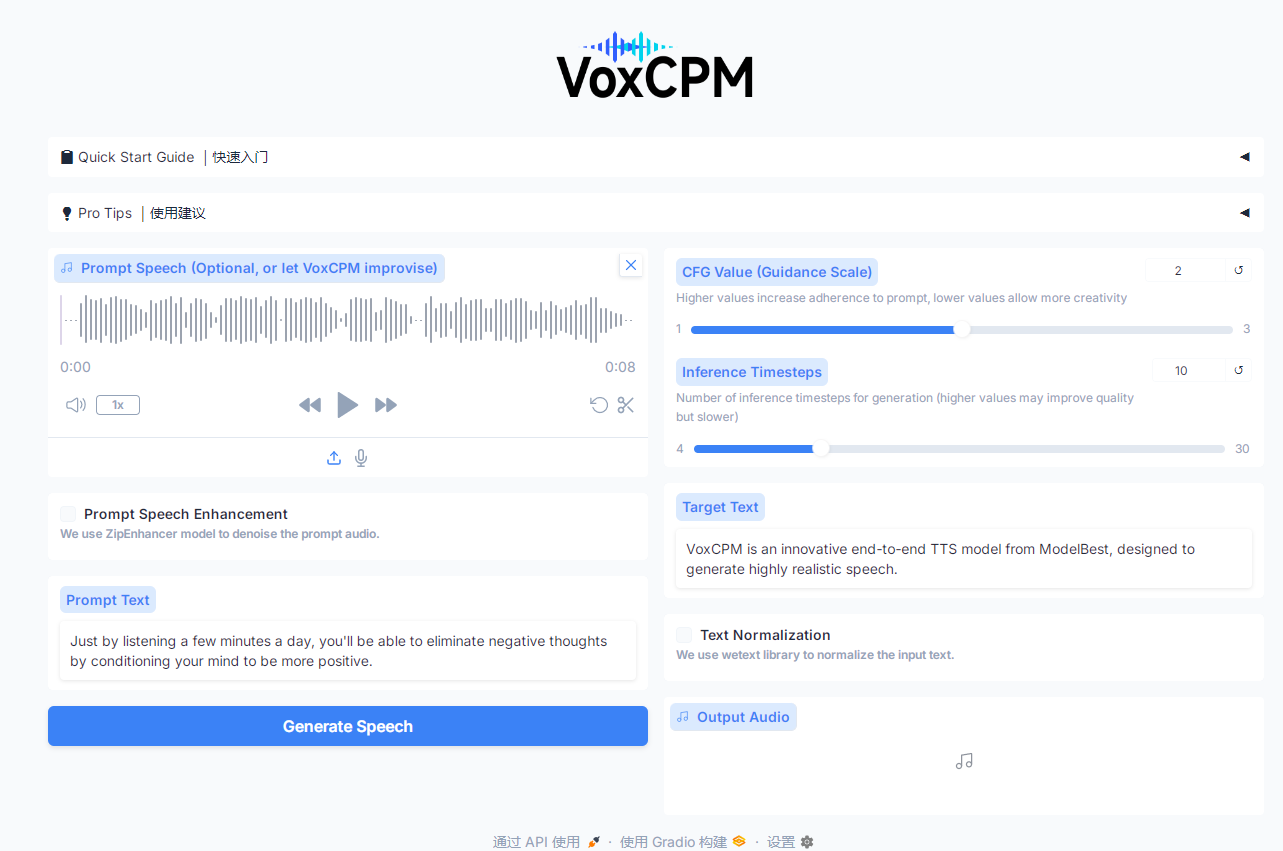
生态扩展:ComfyUI/WebUI 插件
社区已推出 ComfyUI-VoxCPM、WebUI-VoxCPM 等插件,支持:
- 与 Stable Diffusion 联动,实现 “文本→语音→数字人” 全流程自动化;
- 可视化调整语音参数(语速、音调、情感强度);
- 批量语音克隆与格式转换,降低非技术用户使用门槛。
四、性能碾压:Seed-TTS-eval 基准测试领先
VoxCPM-0.5B 以轻量参数(仅 0.5B)实现了开源 TTS 的性能突破,在 Seed-TTS-eval 权威基准测试中,各项指标领先同类模型:
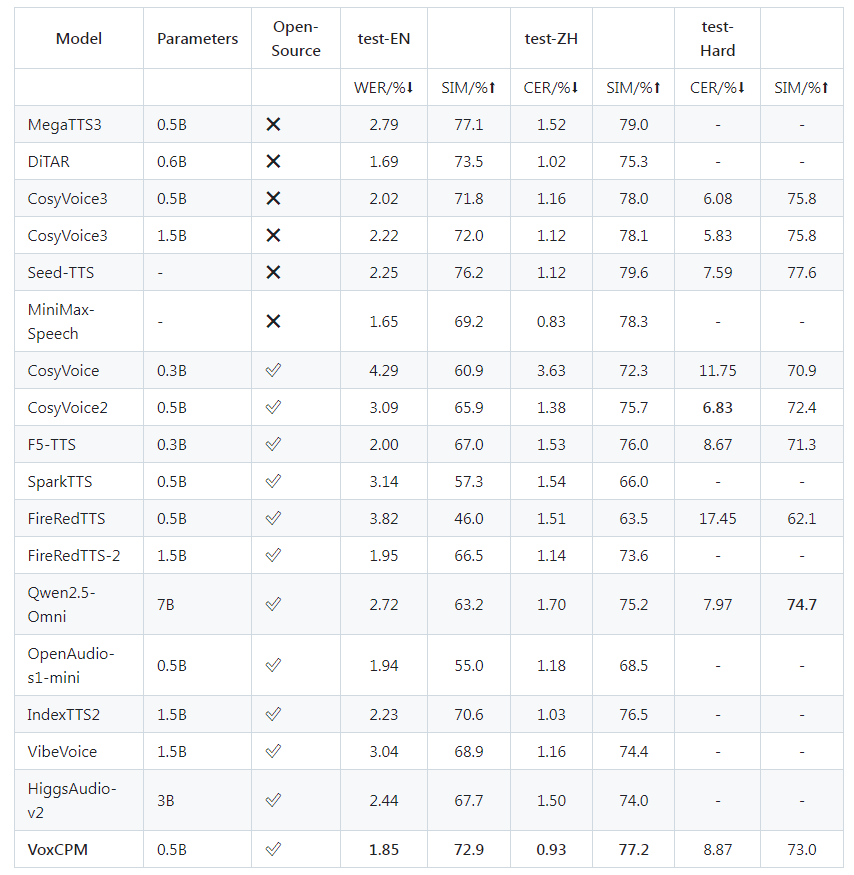
注:数据综合自 Seed-TTS-eval 官方报告及社区实测,相似度指标数值越高表示克隆效果越优,RTF 越低表示推理速度越快。
五、合规与风险:负责任地使用语音技术
VoxCPM 采用 Apache-2.0 开源协议,允许商业使用,但需重点关注以下风险与合规要求:
核心风险提示
- 语音克隆功能可能被滥用(如伪造他人语音诈骗、侵权),根据《个人信息保护法》,声纹信息属于敏感个人信息,未经授权克隆他人语音涉嫌违法;
- 长文本或强情感表达输入可能出现韵律不稳定、音色偏移等问题;
- 目前主要优化中英文场景,其他语言合成质量未做保证,可能存在发音偏差。
合规使用建议
- 仅对自有语音或已获得明确授权的语音进行克隆,避免侵犯他人声音权益;
- 商业应用中需为 AI 生成语音添加可识别标识(如水印、片头提示),符合清朗专项行动要求;
- 避免用于虚假宣传、诈骗等违法场景,遵守开源协议及当地法律法规。
总结
VoxCPM 以无分词器架构重构了 TTS 技术路径,既解决了传统模型的自然度痛点,又通过轻量设计降低了落地门槛 ——0.5B 参数实现高保真生成,0.17 RTF 满足实时需求,零样本克隆支持多样化场景,再加上丰富的生态插件和商业友好的开源协议,使其成为开发者、内容创作者和企业的优选工具。
从个人创作者的短视频配音、虚拟主播搭建,到企业的智能客服、数字人交互,VoxCPM 正在推动语音技术从能用向好用、爱用升级。随着社区生态的完善,未来在多语言支持、长文本稳定性、情感精细化控制等方面的优化,将进一步拓展其应用边界。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











