






05-使用分治法分析最大子数组问题_哔哩哔哩_bilibili
1.分治算法
2.二叉树
3.堆排序
4.动态规划
5.贪心算法
一、 分治算法
对于一个规模较小的问题,则直接解决。若其规模较大,则分解为k个规模较小的子问题,子问题互相独立且与主问题形式相同。
去递归的解决这些子问题,然后将各个子问题的解结合得到原问题的解。
f(0)=1
f(1)=9
f(n)=f(n-1)+f(n-1)
例题:
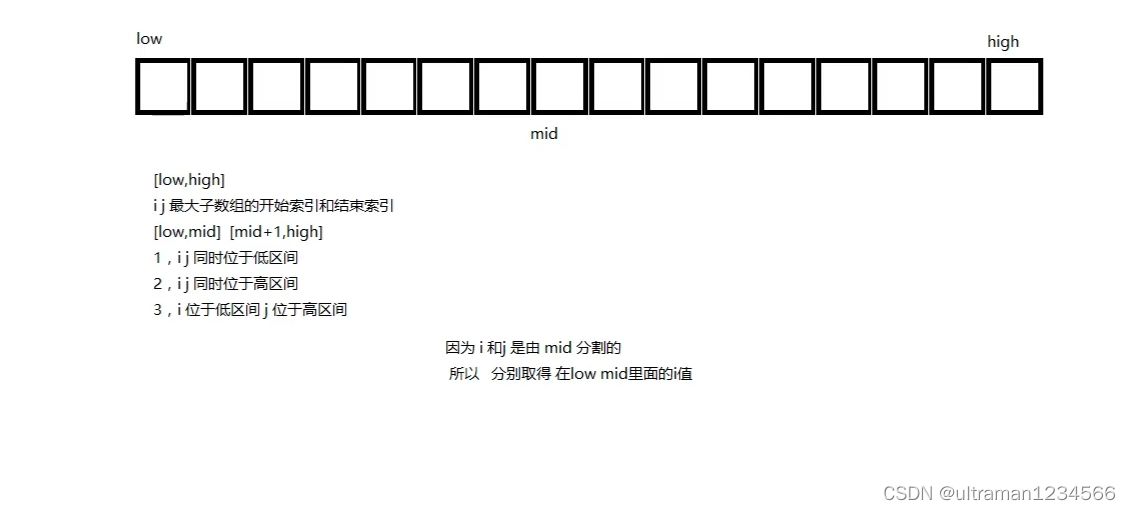
关于第三种情况,i到中间和中间到j之间的值也一定是最大的,所以左右分别遍历一次找到两个最大的和。
using System;
class Stock
{
public int MaxProfit(int[] prices)
{
return MaxProfit(prices, 0, prices.Length - 1);
}
private int MaxProfit(int[] prices, int start, int end)
{
if (start >= end)
{
return 0;
}
int mid = (start + end) / 2;
// 计算左半部分的最大收益
int leftMaxProfit = MaxProfit(prices, start, mid);
// 计算右半部分的最大收益
int rightMaxProfit = MaxProfit(prices, mid + 1, end);
// 计算跨越左右两部分的最大收益
int crossMaxProfit = MaxCrossProfit(prices, start, mid, end);
// 返回三者中的最大值
return Math.Max(Math.Max(leftMaxProfit, rightMaxProfit), crossMaxProfit);
}
private int MaxCrossProfit(int[] prices, int start, int mid, int end)
{
int leftMax = int.MinValue;
int rightMin = int.MaxValue;
for (int i = mid; i >= start; i--)
{
leftMax = Math.Max(leftMax, prices[i]);
}
for (int i = mid + 1; i <= end; i++)
{
rightMin = Math.Min(rightMin, prices[i]);
}
return rightMin - leftMax;
}
}
class Program
{
static void Main()
{
int[] prices = { 7, 1, 5, 3, 6, 4 };
Stock stock = new Stock();
int maxProfit = stock.MaxProfit(prices);
Console.WriteLine("最大收益为:" + maxProfit);
}
}
注释:该方法首先拆分成三个部分,只计算第三种情况,然后把前两种情况再拆分,直到他们的中间数也允许他们成为第三种情况为止。 然后比较这三个情况中最大的那个数即可。
计算第三种情况的方法: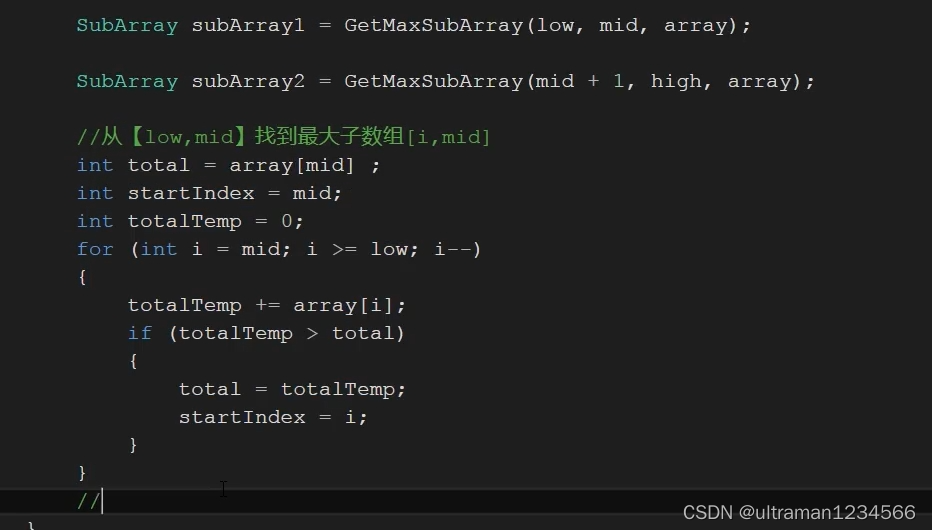
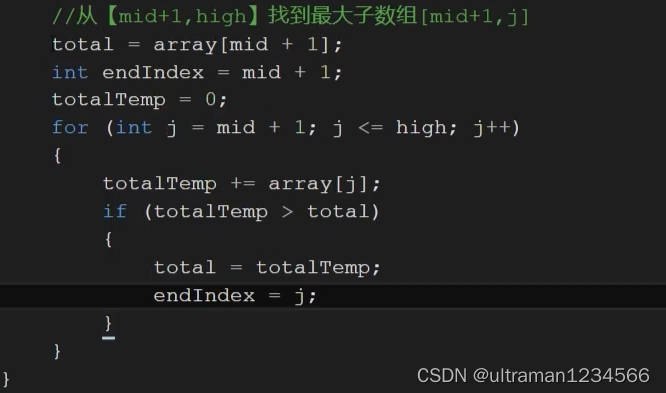 该递归终止的条件,也就是左右无法再继续分下去,只有一个值的时候。
该递归终止的条件,也就是左右无法再继续分下去,只有一个值的时候。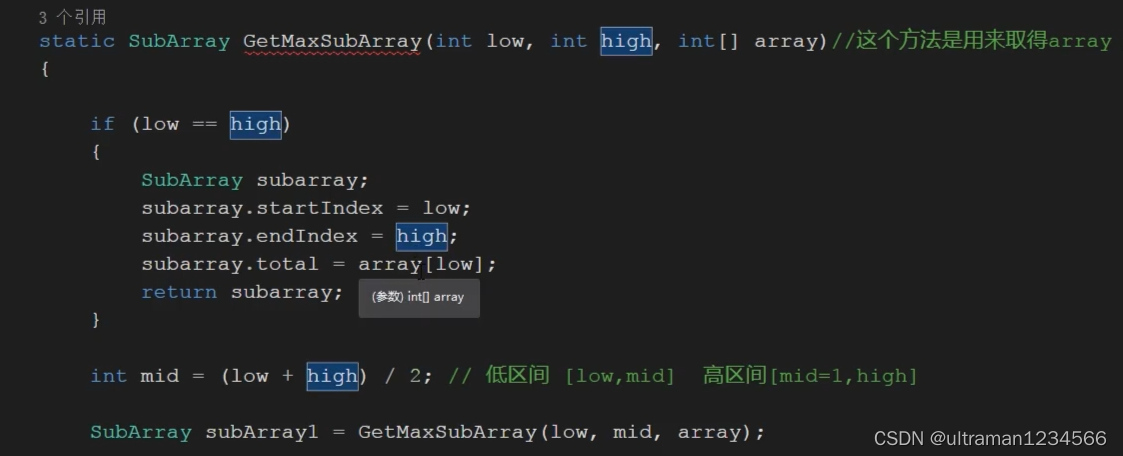
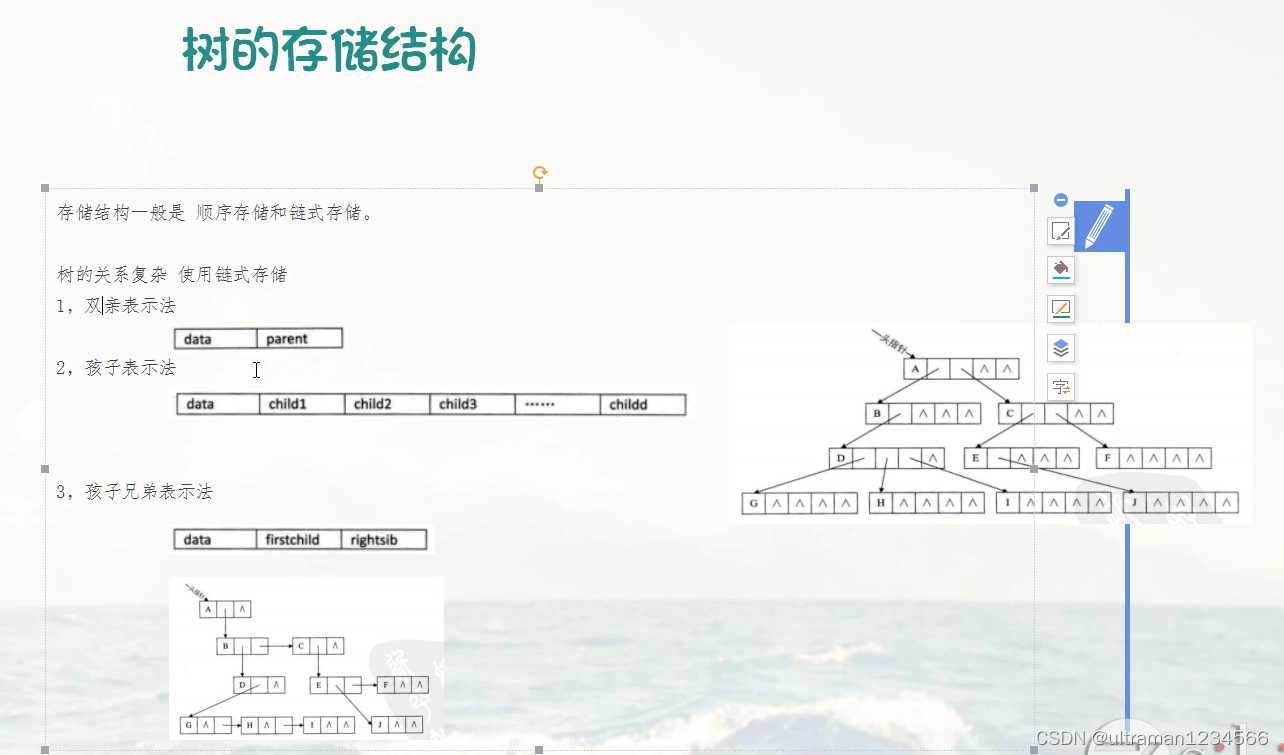
二、树(编号比索引少1)
结点关系:孩子,兄弟 度:拥有子树的个数 树采用链式存储↓,但完全二叉树可以采用顺序存储。
1. data parent 2.data child1 child2 child3 3.data firstchild rightsilb 孩子兄弟表示法,并且只保存第一个孩子与第一个兄弟
2.1 二叉树: 每个根节点至多只有左右两个结点
左斜树:只有左结点
右斜树:只有右结点
满二叉树:每个结点都有左右子结点,且数量相同
完全二叉树:比起满二叉树,可以略微宽松。从右向左可以逐渐没有
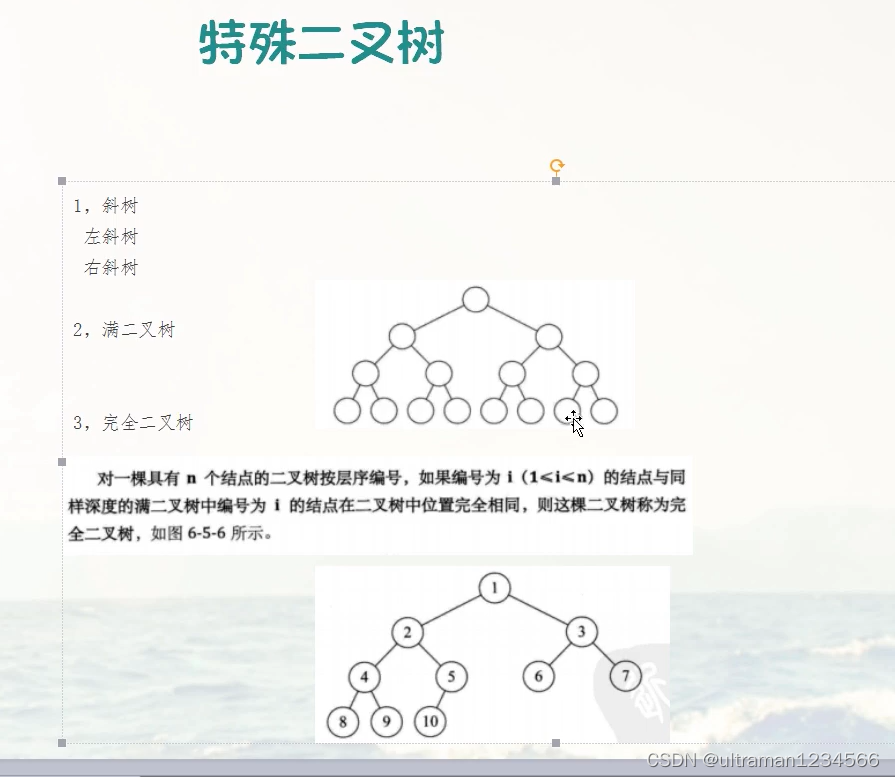
完全二叉树的性质:若一个二叉树有n个结点,从1开始依次编号, 那么对于任意结点i
则除1外,每个结点的父节点为 i/2, 左孩子是2i,右孩子是2i+1。
2i>n说明无左孩子,2i+1>n说明无右孩子。

13-使用代码实现二叉树的顺序存储_哔哩哔哩_bilibili
也就是说,即使该结点为空,也要按顺序来存储。到时只要判断数组是否为空,就可以知道该结点是否为空了。
所以造成了空间浪费,一般顺序存储只用于完全二叉树。
这种方法耗存比较多,而且访问不到父节点,所以如果是完全二叉树,不需要用这种方法。
以下是四种遍历方式:14-二叉树的遍历(代码实现)_哔哩哔哩_bilibili

![]()
是为了防止不是完全二叉树的情况下,出现空结点的情况。如果空结点则把它的数组位置设为-1
(前序遍历)中左右
编号是从1开始。索引是从0开始,所以编号=索引+1;
然后输出当前节点,获得左节点和右节点的索引。输出他们其实相当于递归调用
注意。因为传进来的是index,所以-1再加1
【这里结束递归的条件写错了,应该是index > = count, 而不是数组的长度。因为空结点的问题,数组不一定能装满,所以应该以存放的数据个数为界限】
(中序遍历)左中右
代码和前序大同小异,只不过调换一下顺序。
(后序遍历)左右中 不再举例
(层序遍历)直接遍历整个数组即可,因为它本来就是顺序存储的。
但要注意遍历的是已有数据的长度,不需要遍历整个数组的长度。同时考虑空结点的问题
2.2 二叉排序树

排序、查找、删除、插入都很方便。 比它小的放左边,比它大的放右边就好了。
第三种情况,因为中间结点一定是在左(小)右(大)两者之间的值,所以要么是左边最大的,要么是右边选一个最小的。所以要找到左边最大的结点,就遍历左边所有的右节点即可。要找到右边最小的结点,则遍历右边所有的左节点即可。
因为二叉排序树的存储,跟自身值的大小有关系,并不是想之前学习的完全二叉树使用顺序结构可以存储的 所以我们使用链式结构存储二叉排序树。
 节点类
节点类
 添加方法,前半部分
添加方法,前半部分
 添加操作
添加操作
 通过中序遍历,从根节点开始
通过中序遍历,从根节点开始
因为左边的编号最小,然后是中间,然后是右边
 查找方法
查找方法
这就是所说的,排序二叉树查找方便的原因。
 查找优化
查找优化
当左右结点为空时,它们被设为头结点的一刻会被判断为node==null ,返回false结束回调
 查找-终极简化版
查找-终极简化版
接下来是删除方法,前半部分同样查询然后把这个节点传到删除方法里。
 查找删除值
查找删除值
 要删除的结点没有子结点,则让该结点的父节点的对应节点为空。
要删除的结点没有子结点,则让该结点的父节点的对应节点为空。
 要删除的结点只有一个孩子的情况,让孩子继承该结点的位置,然后取消它的子结点。 不过我感觉直接让node.parent.left/right=node.left/right 更严谨好些
要删除的结点只有一个孩子的情况,让孩子继承该结点的位置,然后取消它的子结点。 不过我感觉直接让node.parent.left/right=node.left/right 更严谨好些
接下来是第三种情况,要删除的结点有两个子节点。 因为前面两种情况都有return,所以没有被返回的一定是第三种情况,就不用写判断条件了。 这里用了遍历右边结点的所有左结点的情况,这样遍历完之后留下来的一定是最后一个左结点,也就是值最小的。 那么这个值本身要被删除的话,也只可能是前两种情况,所有递归调用一下delete方法
2.3 堆排序
在构造大顶堆时,找到最底下三个当中最大的那个,和三个当中的根节点交换,然后往上循环这个过程,就构成了整体的大顶堆。
从最后一个叶子节点遍历到根节点,只需要将最后一个编号/2可得到它的父节点,依次往上推
第一行是为了得到所有的非子节点,然后遍历他们。每一个根字节都判断左右的大小情况,先得到他们的索引。若左结点存在且大于本身,则更新最大编号为左结点,右边同理。如果这个编号没有变化,就说明没有交换,本身就是最大的,反之,则交换两个结点的位置。
小细节,用来比较原来根节点的tempI被定义在了外面,是为了让判断条件动态变化(随着最大编号的变化而变化,而不是随着i的变化而变化)说白了就是判断还是不是它自己了,所以是自己跟自己的索引比
交换-再构造大顶堆
有一些地方进行了改变。
三、动态规划




第一种方法是 带备忘的自顶向下法
此方法依然是按照自然的递归形式编写过程,但过程中会保存每个子问题的解(通常保存在一个数组中)。
当需要计算一个子问题的解时,过程首先检查是否已经保存过此解。如果是,则直接返回保存的值,从而节省了计算时间;
如果没有保存过此解,按照正常方式计算这个子问题。我们称这个递归过程是带备忘的。
第二种方法是 自底向上法
首先恰当的定义子问题的规模,使得任何问题的求解都只依赖于更小的子问题的解。
因而我们将子问题按照规模排序,按从小到大的顺序求解。当求解某个问题的时候,它所依赖的更小的子问题都已经求解完毕,结果已经保存。
回到钢条问题,假设只切一下分成两段,那么第一段就是从1开始,后面那段就是n-1;然后从2开始,后面那段就是n-2;以此类推。
现在要切成三段的话,就是在第二段的基础上,再重复切割成两段的过程。(第一段的结果已经保存,只要计算二三段之间的情况,而二三段不就是递归调用一二段的算法吗?)
要么就不切割,计算这两种情况的最优解。
代码实现:①自顶而下递归
依次遍历前一段有1节长、有2节长、有n-1节长的情况。
那么总价值就等于 前一段的价值,加上递归后一段(前段价值,后段价值)
然后通过比较更新最大收益,照常加上终止条件。
代码实现:②带备忘的自顶而下递归(之前提过的第一种方法)

(n应该是10吧。。)
长度为多少的情况,结果保存在这个数组中。0的情况也算进去,所以长度+1
将这一段的价值计算结果返回,下次碰到这个数组里相同位置的,就直接返回这个位置的值。
不用再进行后面的代码运算。 (用result[n]!=0 说明已经有相同的赋过值了)
代码实现:③自底向上法(之前提过的第二种方法)
【看不懂了,以后再补注释】
3.2 背包问题的动态规划
 算法:物品重量超过容量,直接总数减1不再考虑。 不超过容量,不放入,则同样减1不考虑。
算法:物品重量超过容量,直接总数减1不再考虑。 不超过容量,不放入,则同样减1不考虑。
不超过且放入,则数量减1,容量增加物体重量,价值增加物体价值。
代码实现:
当数量为0或重量为0时应该结束递归;
超过背包容量则直接返回,下一个物品计算;
第一种最大价值是放入,第二种最大价值是不放入。返回更大的那一个值
带备忘的版本
四、贪心算法


【未完待续】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









