




论文作者知乎专栏介绍:https://zhuanlan.zhihu.com/p/34222060
本论文关注点在于关注跟踪目标的细节信息,提高目标的判别能力。
提出原因:Siam类方法普遍判别性不强,在图像中出现与目标相似的干扰物时,经常出现跟踪错误的目标的情况。
改进点:使用自编码(encoder-decoder)结构使得特征网络更多的关注目标的细节信息,并结合context-aware的相关滤波抑制掉周边的干扰,并且使得模型可以在线更新。自编码结构,通过计算解码出来的图像与原图像之间的误差损失,通过优化使其不断缩小,达到编码器中间的输出包含目标更多的细节信息。
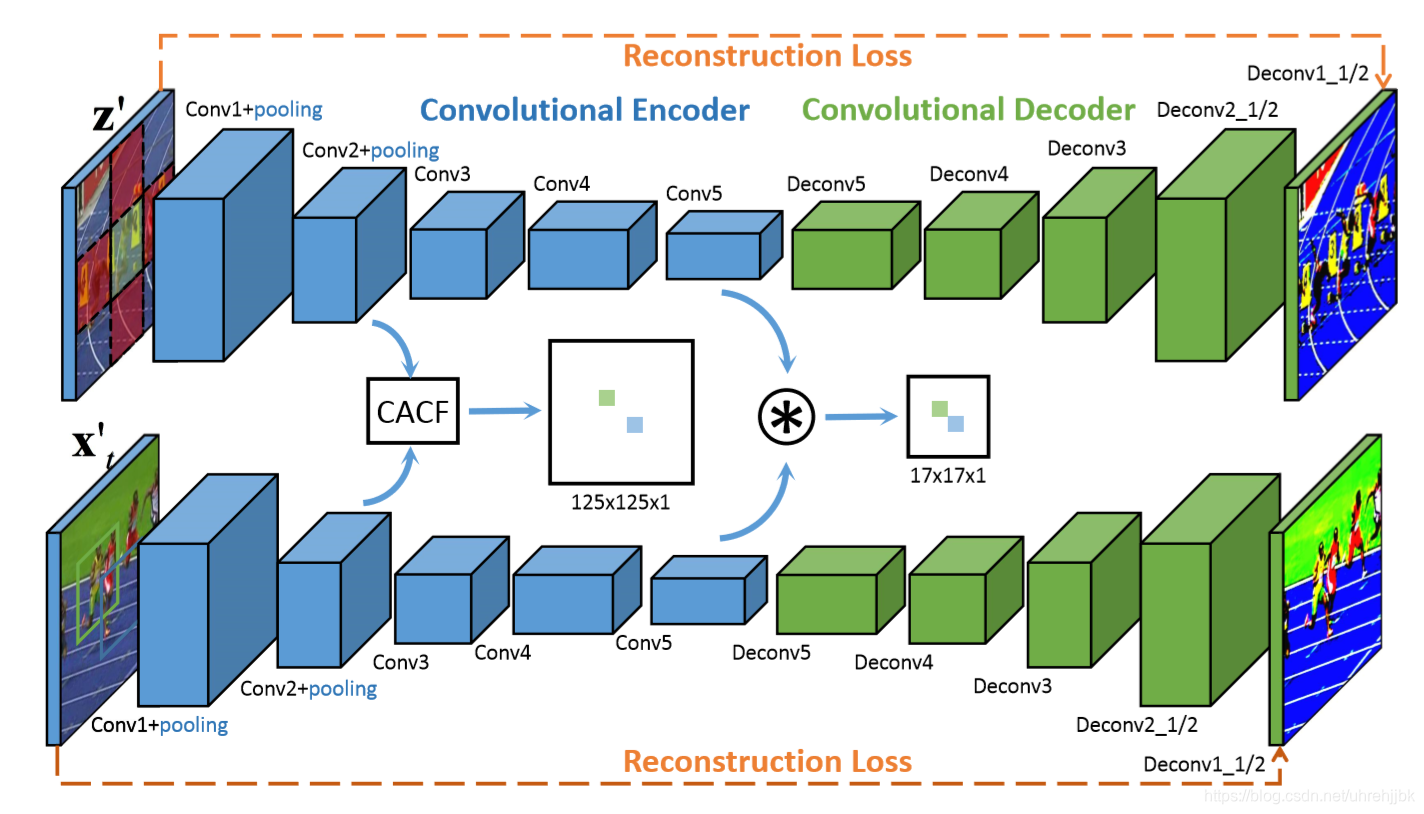
本篇依然是孪生网络的变体,上分支为模板图像分支,下分支为待搜索图像分支。模板图像和待搜索图像均通过encoder-decoder结构,原图和生成图像之间的差异成为reconstruction loss,利用增加的重构损失提高网络的判别能力。然后只考虑encoder结构的话,两图像均通过CNN网络,先利用CACF提取浅层特征得到125*125*1的响应图。再利用深层特征进行互相关计算得到17*17的响应图,将该响应图上采样到125*125*1大小,最后将两幅响应图进行融合得到最终的响应图。
CACF来源于《Context-Aware Correlation Filter Tracking》上下文感知的相关滤波器http://openaccess.thecvf.com/content_cvpr_2017/papers/Mueller_Context-Aware_Correlation_Filter_CVPR_2017_paper.pdf
出发点:余弦窗(用来抑制边界效应的)和search region的限制,导致CF模板学不到太多的背景信息,当目标发生比较大的形变或者复杂背景干扰的时候,容易跟丢。
基本思想是在目标图像块周围采样k个上下文图像块,将这些图像块看作困难负样本,目标是让目标图像块有高响应,周围图像块响应接近0

具体细节可详细阅读:https://zhuanlan.zhihu.com/p/26586334

















 2155
2155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









