




 这篇博客汇总了机器学习面试中的常见问题,涵盖损失函数、交叉验证、特征选择、机器学习流程、模型融合策略等。讨论了决策树的参数、节点分割标准及剪枝方法,还涉及SVM、LR区别、无监督学习算法、聚类方法和PCA、LDA等概念。
这篇博客汇总了机器学习面试中的常见问题,涵盖损失函数、交叉验证、特征选择、机器学习流程、模型融合策略等。讨论了决策树的参数、节点分割标准及剪枝方法,还涉及SVM、LR区别、无监督学习算法、聚类方法和PCA、LDA等概念。
机器学习算法工程师面试集锦(更新中)
- 面试问题汇总
-
- 常用的损失函数
- 介绍交叉验证
- 特征选择方法
- 机器学习项目的一般步骤
- 经验风险最小化与结构风险最小化
- 训练决策树时的参数是什么
- 在决策树的节点处分割标准是什么
- 决策树的剪枝策略
- 基尼系数的公式
- 熵的公式是什么
- 决策树如何决定在哪个特征处分割
- 随机森林的优点有哪些
- 为什么要模型融合,模型融合方法有哪些
- 介绍一下boosting
- Bagging 和 Boosting区别
- gradient boosting如何工作
- GBDT和XGBoost区别
- 关于AdaBoost算法,你了解多少?它如何工作?
- SVM中用到了哪些核?SVM中的优化技术有哪些?
- SVM和LR的区别
- SVM如何学习超平面?用数学方法详细解释一下。
- 介绍一下无监督学习,算法有哪些?
- 聚类方法有哪几种?
- 在K-Means聚类算法中,如何定义K?
- 讲一下PCA
- 讲一下LDA
- Isolation Forest——异常检测(没问过,但我把它总结在这里)
- ReLU函数的性质(相比sigmoid)
- 参考资料
面试问题汇总
问题来自于牛客,公众号,以及自己的亲身体验。
常用的损失函数
- 0-1损失函数
- 平方损失函数
L(Y,f(X))=(Y-f(X))^2 - 绝对损失函数
L(Y,f(X))=|Y-f(X)| - 对数损失函数
L(Y,P(Y|X))=-log P(Y-|X)
介绍交叉验证
- 简单交叉验证
- K折交叉验证
- 留一交叉验证
特征选择方法
- 递归特征消除RFE(网上有很多RFE资料)
- 基于学习模型的特征排序
- 去掉取值变化小的特征
机器学习项目的一般步骤
- 问题抽象
- 数据获取
- 特征工程(数据清洗,预处理,采样)
- 模型训练、调优
- 模型验证、误差分析
- 模型融合
- 模型上线
经验风险最小化与结构风险最小化
- 经验风险最小化
统计学中的极大似然估计(Maximum Likelihood Estimation MLE)就是经验风险最小化的一个典型的例子。当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化与极大似然估计等价。虽然在样本数量足够大的情况下,经验风险最小化求解出来的模型能够取得不错的预测效果,但是当训练数据集也就是样本容量比较小时,基于经验风险最小化训练出来的模型往往容易过拟合
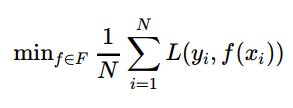
- 结构风险最小化
与经验风险最小化对应的叫做结构风险最小化。结构风险最小化是为了防止过拟合而提出来的一种策略,它与正则化等价。结构风险在经验风险的基础上加上表示模型复杂度的正则化项或者罚项。其定义如下:
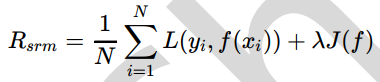
训练决策树时的参数是什么
class sklearn.tree.DecisionTreeClassifier(criterion=‘gini’, splitter=‘best’, max_depth=None, min_samples_split=2,min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None,min_impurity_split=1e-07, class_weight=None, presort=False)
重要的参数 :
criterion:规定了该决策树所采用的的最佳分割属性的判决方法,有两种:“gini”,“entropy”。
max_depth:限定了决策树的最大深度,对于防止过拟合非常有用。
min_samples_leaf:限定了叶子节点包含的最小样本数,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









