




聚类
非标记数据的聚类在sklearn.cluster模块中执行。
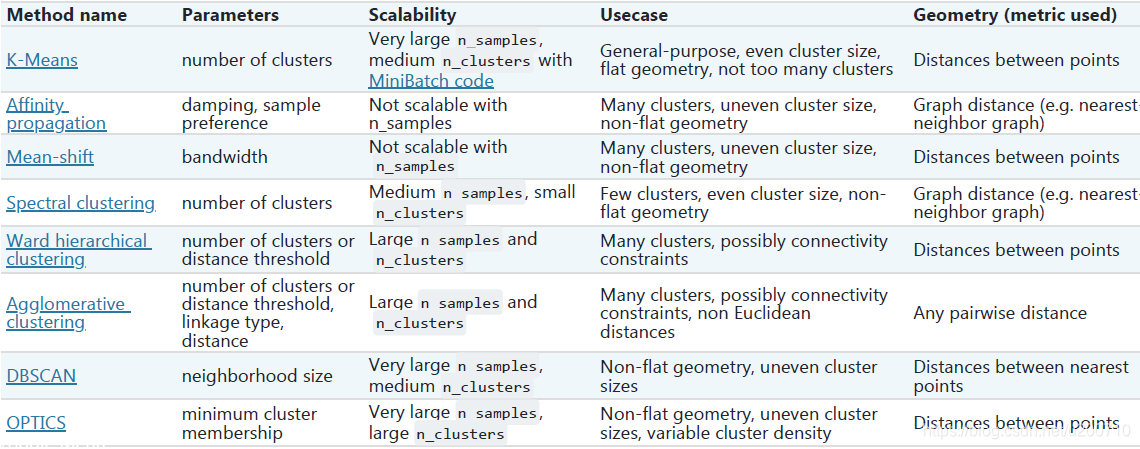
聚类方法一览

K-means
KMeans算法通过最小化聚类间的距离平方和作为聚类标准。
∑i=0nminμj∈C(∣∣xi−μj∣∣2)
\sum\limits_{i=0}^n \min\limits_{\mu_{j} \in C}(||x_i - \mu_j||^2)
i=0∑nμj∈Cmin(∣∣xi−μj∣∣2)
KMeans算法等价于特殊情况下的期望最大算法。
# coding: utf-8
# Demonstration of k-means assumptions
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
plt.figure(figsize=(12, 12))
n_samples = 1500
random_state = 170
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
y_pred = KMeans(n_clusters=2, random_state=random_state).fit_predict(X)
plt.subplot(221)
plt.scatter(X[:,0], X[:, 1], c=y_pred)
plt.title("Incorrect Number of Blobs")
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]]
X_aniso = np.dot(X, transformation)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_aniso)
plt.subplot(222)
plt.scatter(X_aniso[:,0], X_aniso[:, 1], c=y_pred)
plt.title("Anisotropicly Distributed Blobs")
X_varied, y_varied = make_blobs(n_samples=n_samples,
cluster_std=[1.0, 2.5, 0.5],
random_state=random_state)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_varied)
plt.subplot(223)
plt.scatter(X_varied[:, 0], X_varied[:, 1], c=y_pred)
plt.title("Unequal Variance")
X_filtered = np.vstack((X[y == 0][:500], X[y == 1][:100], X[y == 2][:10]))
y_pred = KMeans(n_clusters=3,
random_state=random_state).fit_predict(X_filtered)
plt.subplot(224)
plt.scatter(X_filtered[:, 0], X_filtered[:, 1], c=y_pred)
plt.title("Unevenly Sized Blobs")
plt.show()
使用MiniBatchKMeans是KMeans算法的变体,使用小批量减少计算时间。其产生的结果比标准算法稍差。
仿射传播 Affinity Propagation
AffinityPropagation通过在样本对间传播消息来构建聚类。由于算法的复杂性,使得仿射传播仅适宜于小到中型的数据集。
均值漂移 Mean Shift
MeanShift聚类是为了在平滑密度的样本中发现斑点。
光谱聚类 Spectral Clustering
SpectralClustering在样本之间执行仿射矩阵的低维嵌入,然后通过KMeans,聚类低维空间中的特征向量。
层次化聚类 Hierarchical Clustering
层次聚类是一个通用的聚类算法家族,它通过合并或拆分嵌套聚类来构建嵌套聚类。类别的层次结构由树表示。AgglomerativeClustering
DBSCAN
DBSCAN算法将簇视为由低密度区域分隔的高密度区域。由于这种观点,DBSCAN发现的簇可以是任何形状,而k-means则假设簇是凸形的。
OPTICS
OPTICS算法与DBSCAN算法有许多相似之处,可以看作是DBSCAN算法的一个推广,它可以使DBSCAN算法的性能得到放松eps要求从一个值到一个值范围。
Birch
Birch构建了一种称作聚类特征树的树。
聚类性能评价
评估一个聚类算法的性能并不像计算错误数量或监督的精确度和召回率那么简单分类算法。
真实的分类已知
Adjusted Rand Index
Mutual Information based scores
Homogeneity, completeness and V-measure
Fowlkes-Mallows scores
真实的分类未知

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









