 二进制编码解析
二进制编码解析





 本文深入探讨了计算机中数据的二进制表示方法,包括有符号和无符号整数的编码原理,以及浮点数的IEEE标准编码方式。通过具体示例,详细解释了不同数据类型如何在内存中存储和解释。
本文深入探讨了计算机中数据的二进制表示方法,包括有符号和无符号整数的编码原理,以及浮点数的IEEE标准编码方式。通过具体示例,详细解释了不同数据类型如何在内存中存储和解释。
signed和float类型数据编码
计算机只能处理存储二进制数据,不管是字符、整数、小数,在计算机中同样是二进制数,只是系统将其做了不同的解释。对于无符号整数,存储到存储中的即是它的二进制表示,比如十进制数10对应二进制1010,十进制数30对应二进制11110。对于有符号数,我们需要考虑同时保存它的值和符号,通常使用最高位为1表示负号-,最高位0表示非负。
有符号整数
举个例子,char类型变量在内存中占用一个字节,8位二进制数,为了方便我们使用16进制表示,char类型可以存储0x00到0xff,总共256(十进制)个不同的值,最高位是1和0的分别有128个,即有128个负数和128个非负数。我们编程测试一下
char i = -1;
//强制转换为unsigned char变量
unsigned uc = (signed char)i;
printf(“16进制输出为,i:%x,ui:%x\n”,i,ui);
输出结果

出现这种情况,是因为%x 是int格式化符,i和ui被强制转换为int类型,i和ui变量所在的内存,都是存储的0xff,但是编译器将i的值解释为-1,强制转换为int型变量-1,16进制表示为0xffffffff,而ui变量被解释为255,强制转化后int型255,16进制表示为0x000000ff。事实上存储无符号数和有符号数,随着二进制的增加,十进制值也在增加,如果使用一个函数表示,二进制数是输入,十进制数是输出,这个函数是递增的。
| 0x | 00 | 01 | 02 | … | 80 | 81 | … | fb | fc | fd | fe | ff |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| char | 0 | 1 | 2 | … | -128 | -127 | … | -5 | -4 | -3 | -2 | -1 |
| unsigned char | 0 | 1 | 2 | … | 128 | 129 | … | 251 | 252 | 253 | 254 | 255 |
总结,计算机中的数据是通过补码的方式表示的,对于有效数字为n为的二进制数N,它的补码Ncomp表示为
Ncomp=N(N为非负数)
Ncomp = N (N为非负数)
Ncomp=N(N为非负数)
Ncomp=2n+N(N为负数)
Ncomp = 2^n + N (N 为负数)
Ncomp=2n+N(N为负数)
(char)-1是0xff,(short)-1是0xffff,(int)-1是0xffffffff。
32位float
浮点数有不同的标准,IEEE标准,单精度float使用4字节32位表示。基数为2,最高位是符号位,紧接着8位是阶码E,最后23位是尾数M,
最高位s 8位阶码 E 23位尾数M
阶码取值为【0,255】区间的整数,使用阶码的移码做基数的幂指数。
±1.m∗2E−127
±1.m * 2^{E-127}
±1.m∗2E−127
使用时,阶码减127做幂指数,23位尾数在最低位补0成24位二进制数做小数。(−1)S∗(1+M∗2∗256−3)∗2(E−127)(-1)^S * (1 + M * 2 * 256^-3) * 2^(E-127) (−1)S∗(1+M∗2∗256−3)∗2(E−127)
举例
//想要给一块内存赋对应的二进制值,要把内存声明成整数类型,无符号和有符号都可以,但是无符号更符合我们的认知
//直接给非无符号整数类型( char int long float…)赋值十六进制和二进制当然不是非法的。但编译器会首先进行编码,然后写入内存
//比如,下面的float赋值,绝不是把32位存储的高3字节赋0,低8字节赋5
//编译器首先会把0x05,强制转换为浮点数5.0,
//然后按照浮点数编码标准编码,存在内存中。
float test = 0x00000005;
printf("%f\n",test);
//5.0存在float中的二进制形式是
unsigned int pui = (unsigned int)&test;
printf("%ux",*pui);
unsigned int ui32 = 0xc0000005;
//不要直接给float 赋值16进制数
float *f32 = &ui32;
printf("*pf是:%.22f\n",f32);
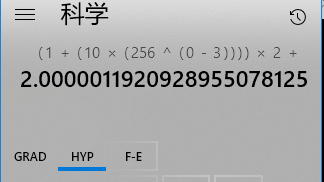
最高位S是1,这是一个负数,其次8位数是0x80,则2的幂指数128-127,最低23位是5,最低位补0 就是23位数左移一位,即使23位数乘以2,小数点后24位是0x0000A0。
使用16进制表示
−1.0000A0∗2==>−(1+0∗256−1+0∗256−2+10∗256−3)∗2128−127=
-1.00 00 A0* 2 ==> -(1 + 0 * 256^{-1} + 0 * 256^{-2} + 10 * 256^{-3}) * 2^{128-127} =
−1.0000A0∗2==>−(1+0∗256−1+0∗256−2+10∗256−3)∗2128−127=
输出结果

如果按照阶码尾数的格式计算,不能表示浮点数0.0,所以浮点格式有特殊编码表示特殊值
一、0,指数部分全部为0,并且尾数全部为0,则表示为浮点0.0,并且规定-0 = +0。如果按阶码式子,此值为1.0 * 2^-127,不考虑符号位,这也是阶码能表示的最小值
二、指数部分全为0,尾数部分不为0,这是非规格值,计算机默认不会使用这些值编码浮点数。如果你手动填充内存,打印出来是0;
二、无限大,32位二进制值一直增加,到阶码全为1,尾数为0时,此时表示为无限大,根据符号位,分为+ref和-ref
三,NAN,阶码全为1时,尾数非0,此时表示NAN,则表示这个值不是一个真正的值(Not A Number),根据尾数M的最高位分为QNAN(1)和SNAN(0),QNAN一般表示未定义的算术运算结果,最常见的莫过于除0运算;SNAN一般被用于标记未初始化的值,以此来捕获异常。
所以,32位单精度浮点的有效范围只在区间
(−2128,2128)(-2^{128},2^{128})(−2128,2128)而不是
(−2∗2128,2∗2128)(-2 * 2^{128},2 * 2^{128})(−2∗2128,2∗2128),更精确的说单精度浮点最大有效值编码为0x7F7FFFFF,最小值0xFF7FFFFF,有效范围区间
[−(2128−2−103),2128−2−103]
[-(2^{128}-2^{-103}), 2^{128}-2^{-103}]
[−(2128−2−103),2128−2−103]

















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









