




 本文深入探讨了分布式系统中的ACID特性和CAP理论,解释了分区容错性的概念,并以Eureka和Zookeeper为例说明了AP与CP策略的选择。接着,介绍了2PC和3PC两种一致性协议,分析了它们的优缺点及应用场景。内容涵盖了从基本理论到实际系统实现,旨在提供一手且准确的分布式事务知识。
本文深入探讨了分布式系统中的ACID特性和CAP理论,解释了分区容错性的概念,并以Eureka和Zookeeper为例说明了AP与CP策略的选择。接着,介绍了2PC和3PC两种一致性协议,分析了它们的优缺点及应用场景。内容涵盖了从基本理论到实际系统实现,旨在提供一手且准确的分布式事务知识。
第一章:
1.1从ACID到CAP/BASE
ACID两张图比较重要,主要是理解ACID概念,特性,以下两张图比较重要(当然mysql还牵扯到锁定读的内容,详见《innodb存储引擎》,有时间会再专门出一期总结一下)
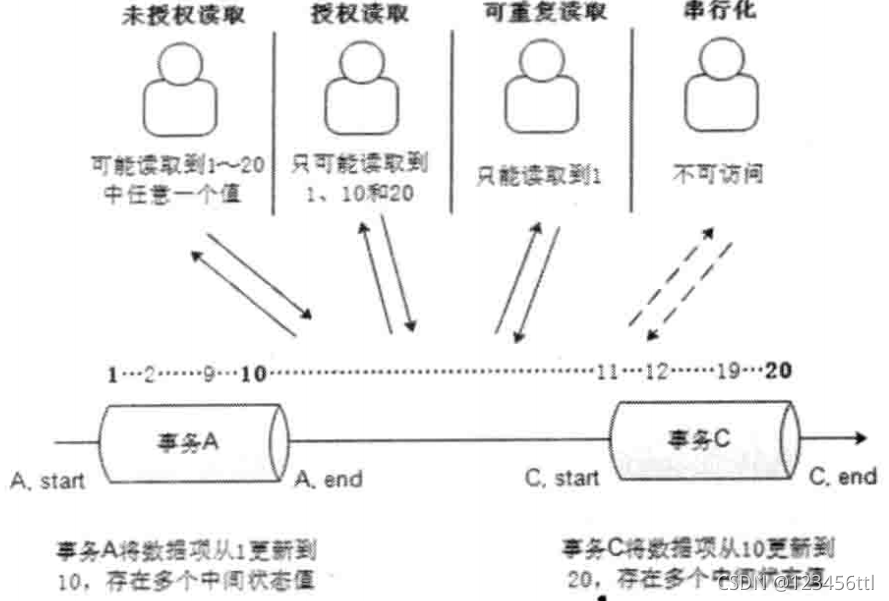
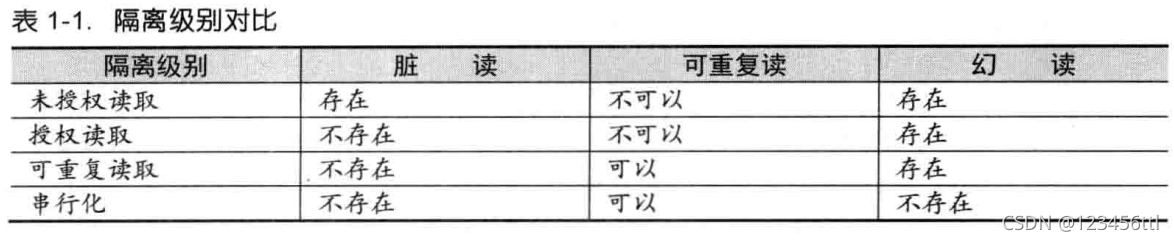
之后就是CAP和BASE,CAP大多数人都知道代表什么,但是如果我问你什么是分区容错性可能你不一定能说的清楚,这里我仍然上原书

其中的网络分区可以是不同的机房,不同地区的机房,甚至可以将微服务新加入的节点看作是一个网络分期,更多的是逻辑上区分。

对于Eureka,采用的是AP,放弃C的策略,不同的注册中心之间允许一段时间的不一致,通过心跳去保持一段时间之后的最终一致性,对于Zookeeper,采用的是CP策略,放弃A,通过算法去选举leader,在此期间服务不可用。所以在使用Zookeeper搭建99.99%甚至更高可靠性系统时,需要考虑选举过程中的不可用问题,对于NameServer(Rocketmq的broker注册中心),采用类似Eureka的形式,有兴趣的同学可以自己研究研究,至少NameServer是开源轻量级的
BASE没有太多要补充的
第二章
2.1一致性协议
这些地方网上教程一大堆,但是我这里都是以书本为准,看文章跟看书一样,确保你拿到的是二手的一手资料(英->中->你)
(1)2PC(我工作中第一套分布式事务就是基于2PC的)
![]()

![]()

 或者当部分事务提交失败的时候做事务中断
或者当部分事务提交失败的时候做事务中断


2PC最大的问题就是阻塞问题,两个阶段所有参与事务的资源都要被锁定,其次TC(事务协调器)存在单点问题,脑裂指的是事务提交阶段如果部分事务提交成功,部分失败,存在不一致的现象,保守指的是,没有TCC那种容错补偿机制
(2)3PC
2PC的提升版,形成了CanCommit,PreCommit和DoCommit三个阶段


或者在PreCommit阶段事务预提交失败,产生回滚



或者在DoCommit过程中产生回滚

总结一下
2PC和3PC区别
1、引入超时机制。同时在协调者和参与者中都引入超时机制。
2、在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
当然,一般情况下,如果成功执行了PreCommit,那么一般认为所有的参与者,都已经完成了事务的主体,仅仅需要进行事务的提交,因此,在这里加入超时重试,是十分合理的
也就是说,除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
回头看一下2PC的缺点,阻塞问题,事务提交阶段可能遇到的阻塞被重试机制屏蔽了,一致性问题,PreCommit能够在第二阶段就开始尝试进行一致性提交,这是3PC对2PC的提升。
当然3PC也存在问题就是PreCommit阶段的数据不一致问题,比如在PreCommit阶段,各个网络分区之间通讯异常导致TC和部分参与者无法通讯,也会存在数据不一致的情况。
第一篇先到这把,我尽量重要的部分以书为准,也会有自己的一些扩展,希望能长期做下去,毕竟很多网络上的资料鱼龙混在,而在细读经典系列里,我将严格的以书为准。部分图片和部分文字可能来源于网络,侵删!!!!!
当然,最重要的是能获得你的点赞和收藏,是我坚持的最大动力。

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









