







视频教程链接:
尚硅谷Spark从入门到精通:https://www.bilibili.com/video/BV11A411L7CK?p=90&spm_id_from=pageDriver
尚硅谷Spark性能调优:https://www.bilibili.com/video/BV1QY411x7xL
Spark简介
官方网站:
https://spark.apache.org/docs/1.3.1/
1.什么是Spark?
这里直接引用官网的介绍:
Spark是一个统一的大规模数据分析引擎

2.为什么Spark如此流行?
3.Spark的组成
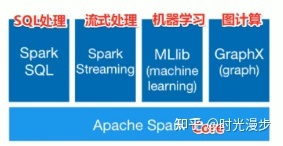
SparkCore作为核心处理引擎,在此之上支持:
- Spark SQL:SQL处理数据集
- SparkStreaming:流式处理
- Mlib:机器学习
- GraphX:支持图计算
4.开箱即用
文档准备:
[root@cloud-3 spark]# vim /tmp/words.txt
hello me you her
hello me you
hello me
hello
代码编写:
scala> val textFile = sc.textFile("file:///tmp/words.txt")
textFile: org.apache.spark.rdd.RDD[String] = file:///tmp/words.txt MapPartitionsRDD[1] at textFile at <console>:23
scala> val counts = textFile.flatMap(_.split(" ")).map(_,1).reduceByKey(_+_)
<console>:23: error: missing parameter type for expanded function ((x$2: <error>) => textFile.flatMap(((x$1) => x$1.split(" "))).map(x$2, 1).reduceByKey(((x$3, x$4) => x$3.$plus(x$4))))
val counts = textFile.flatMap(_.split(" ")).map(_,1).reduceByKey(_+_)
^
scala> val counts = textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:23
scala> counts.collect
res0: Array[(String, Int)] = Array((hello,4), (me,3), (you,2), (her,1))
[(String, Int)] = Array((hello,4), (me,3), (you,2), (her,1))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









