




 博客讲述了线上LB服务因内存问题导致服务中断,提出优化措施,包括避免haproxy日志重启导致内存增长,设置阿里云监控与报警,以及探讨了haproxy+keepalive主从配置、LVS-DR和阿里云SLB三种高可用LB方案,以确保服务不因LB故障而中断。
博客讲述了线上LB服务因内存问题导致服务中断,提出优化措施,包括避免haproxy日志重启导致内存增长,设置阿里云监控与报警,以及探讨了haproxy+keepalive主从配置、LVS-DR和阿里云SLB三种高可用LB方案,以确保服务不因LB故障而中断。
前几天的碰到一个问题,线上的LB服务因为内存问题挂掉了,导致所有的生产环境服务都直接down掉了,因为没有专业的运维,线上环境都是研发直接来管理的,这里有几个问题:
1. 导致内存不停增长,是因为每次切割haproxy的日志的时候,会通过-st的命令重启haproxy,但是因为旧的进程会管理旧的连接直至连接断开才会退出,但是我们用haproxy来代理MQTT这种长连接,所以导致进程一直残留,相当于每天多了一个进程,最终内存不够倒是服务被kill
2. 线上环境服务器的资源使用情况没有监控及报警,就算没有这个问题最后也会有类似的问题产生
3. 架构设计LB没有任何冗余,所以只有LB挂了,那整个服务肯定都会全部失联
然后是针对既有的问题做优化
1. 测试切割haproxy日志时不需要重启haproxy也会继续记录日志,那就不需要根据教程讲的必须重启haproxy,这样也不会有服务一直变多的问题
2. 阿里云对ECS有提供监控与报警的方案,目前已经配置每台服务器CPU,内存使用超过一定阈值都会直接钉钉+短信报警,另外对主要的一些服务的进程也做了监控,找不到进程也会直接报警
3. 对目前的架构进行优化,保证LB的高可用
通过查找资料,有以下几个方案:
1. haproxy + keepalive 主从配置
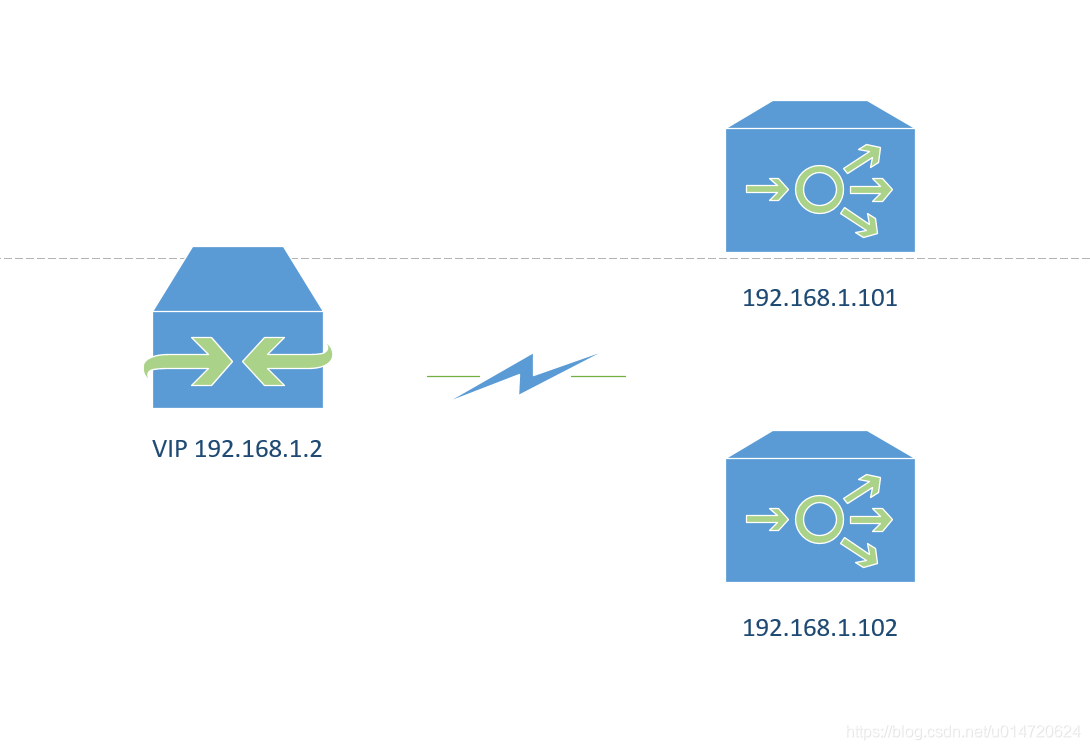
如上图,两台服务器分别是101及102,两台服务器上都部署haproxy,配置一样,然后两台都部署keepalive,101作为主,102作为从,此时网关通过虚拟IP 192.168.1.2 的 ARM协议会被101进行解析到101的一个mac地址,之后消息都会被101解析
当101挂掉时,虚拟IP 192.168.1.2 的 ARM协议会被102进行解析到1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









