







背景:
1、你知道Spring的一级、二级、三级 缓存分别存放的什么类型的Bean嘛?
- singletonObjects: 一级缓存,实例化且初始化完成的完整对象
- earlySingletonObjects: 二级缓存、实例化完成但未初始话的半成品对象
- singletonFactories: 三级缓存、lambda表达式 用来返回代理或原始对象
2、一般面试经常面试会问Spring是如何解决循环依赖问题的?
- 很多人会回答使用三级缓存。其实最终是二级缓存(提前暴露),Spring使用三级缓存最终解决的不是循环依赖问题 而是代理问题。如果单纯想解决循环依赖问题、使用二级缓存足矣(下面我会尝试修改源码使用二级缓存单纯解决循环依赖问题)。
3、既然二级缓存能够解决循环依赖问题 Spring为什么又引入了三级缓存呢?
- 因为在Bean的创建过程、Spring无法预先知道到底生成Bean的对象到底是原始对象或者代理 对象、所以需要设计这样的一个lambda表达式回调机制、来动态判断返回代理对象还是原生对象.当三级缓存lambda表达式执行完 放入二级缓存 三级缓存清空。保证Bean的生命周期。
假如我设计这样一种依赖 A依赖B、B依赖A、C对象、C依赖A对象。A需要代理对象。
此时Spring只有一级缓存和二级缓存,根据上面得推理二级缓存肯定是存储一个lambda回调机制, 创建过程如下
A 实例化后 lambda放入二级缓存 -> 填充A的B属性 -> B实例化后 lambda放入二级缓存 ->
填充B的A属性 -> 调用lambda表达式生成A的代理对象 -> 填充B的C属性 -> C实例化后 lambda放入二级缓存 -> (一级缓存还没有A)调用lambda表达式生成A的代理对象 -> C对象进入一级缓存 -> B对象放入一级缓存 -> A对象放入一级缓存。
从上面可以看出经过两次调用lambda表达式生成A对象 无法保证单例。换句话说、B的A属性和C的A属性内存地址是不同的。
知识储备:
Spring的Bean的生命周期要比较熟悉
什么是循环依赖:
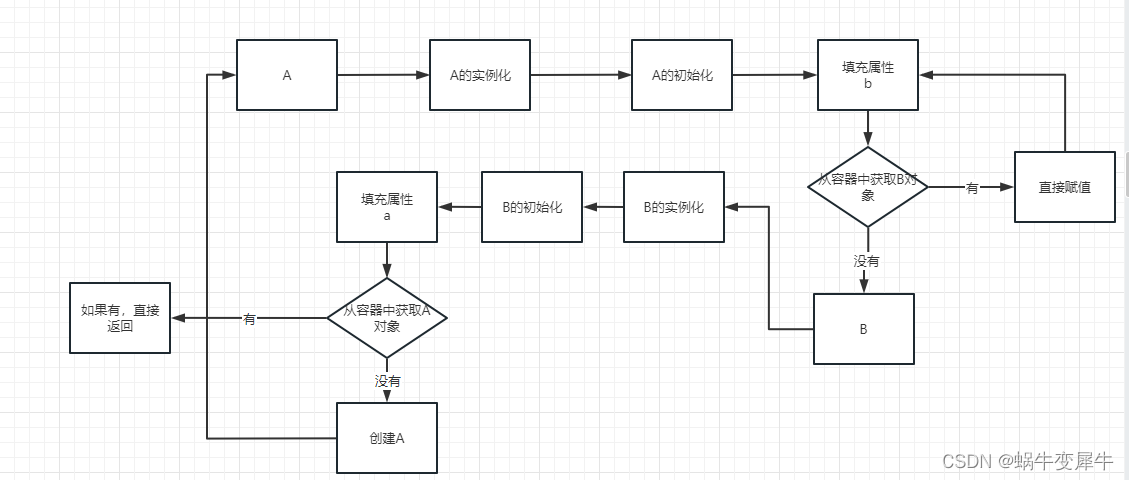
此时,图中是一个闭环,如果想解决这个问题,那么就必须要保证不会出现第二次创建A对象这个步骤,也就是说从容器中获取A的时候必须要能够获取到
思考,在spring中,对象的创建可以分为实例化和初始化,实例化好单未完成初始化的对象是可以直接给其他对象引用的,所以此时可以做一件事,把完成实例化但未完成初始化的对象提前暴露出去,让其他对象能够进行引用,就完成了这个闭环的解环操作,这也就是常规说的提前暴露对象
Debug案例:
- 配置文件
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd "> <context:component-scan base-package="com.zhangfuyin.circle"/> </beans> - java
@Component
public class A {
@Autowired
private B b;
}
=============================================================================
@Component
public class B {
@Autowired
private A a;
}
源码跟踪:
提示:因为Spring循环依赖用贴代码的方式 还是很难理解、因为Spring的创建是一个递归的过程、且几乎涵盖Bean的生命周期的所有方法,这里使用流程图的方式比较容易表达清楚、我会在流程图上标注重要的方法。大家按照数字(实际是递归、我拆了出来)顺序肯定能够明白Spring是如何解决循环依赖的
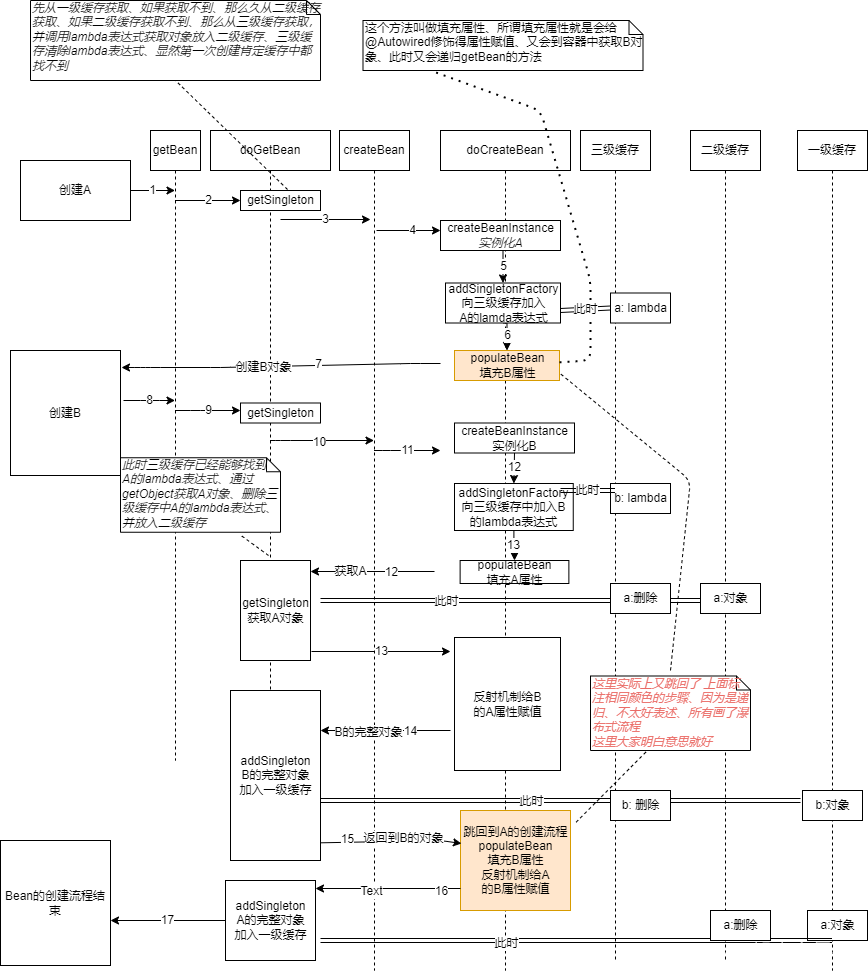
现象:
A对象:经历了从 三级缓存 ----> 二级缓存 --------> 一级缓存
B对象:经历了从 三级缓存 -----> 一级缓存
总结:
1、三级缓存中并不是严格的从三级到二级到一级,这样的一个对象转化顺序,有可能在三级和一级中有对象,也有可能再一二三级中都有对象
2、三级缓存:存放的Lambda表达式
3、二级缓存:存放半成品对象
4、一级缓存:存放完整对象
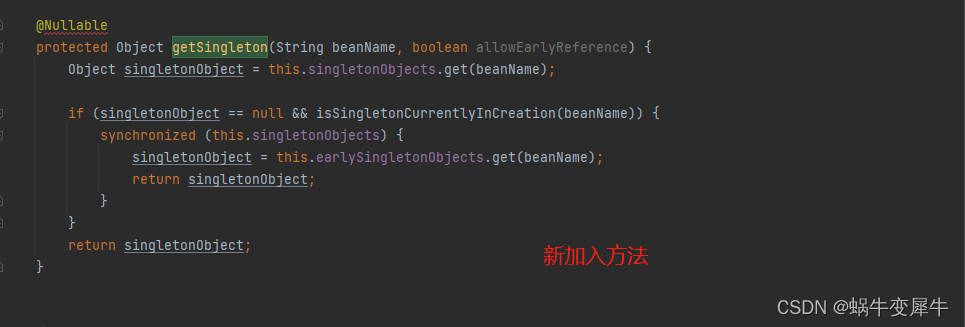
思考:根据流程图,如果说不考虑代理的问题,我如何修改源码 直接用二级缓存就能解决循环依赖问题呢?
无非就改两点:
①放对象的时候不放入三级缓存 即:addSingletonFactory里面的逻辑改成 将实例化好的对象放入二级缓存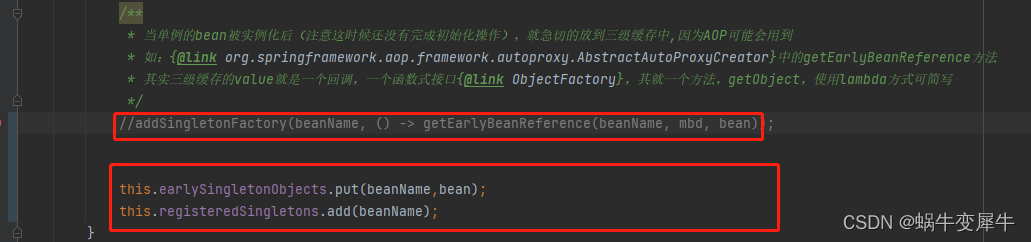
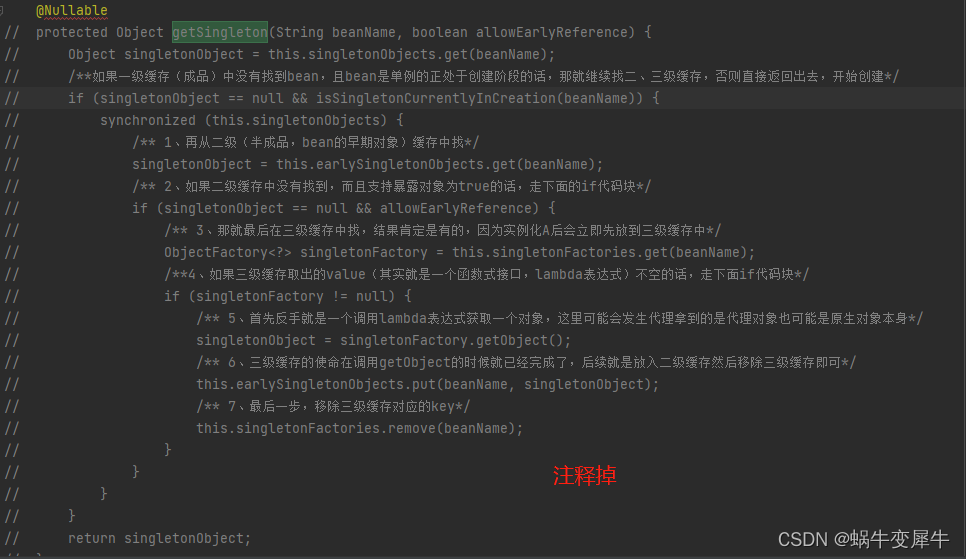
②取对象的时候不向三级缓存获取,即:getSingleton 吧获取三级的逻辑去掉、直接去二级缓存获取

















 3593
3593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









