







- 一、分表
1、建议单表不超过1KW
2、分表方式
- 取模:存储均匀&访问均匀
- 按时间:冷热库
3、水平分表
- 分表场景:系统绝对并发量并没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈。
- 分表分析:表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
4、垂直分表
- 场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大。以至于数据库缓存的数据行减少,查询时会去读磁盘数据产生大量的随机读IO,产生IO瓶颈。
- 分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能会冗余经常一起查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表。这样更多的热点数据就能被缓存下来,进而减少了随机读IO。拆了之后,要想获得全部数据就需要关联两个表来取数据。但记住,千万别用join,因为join不仅会增加CPU负担并且会讲两个表耦合在一起(必须在一个数据库实例上)。关联数据,应该在业务Service层做文章,分别获取主表和扩展表数据然后用关联字段关联得到全部数据。
二、分库
1、按业务垂直分.
- 场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块。
- 分析:到这一步,基本上就可以服务化了。例如,随着业务的发展一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。再有,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
2、水平分库
- 场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库。
- 水平分库分析:库多了,io和cpu的压力自然可以成倍缓解。
四、实践落地方案
1、用户库分表
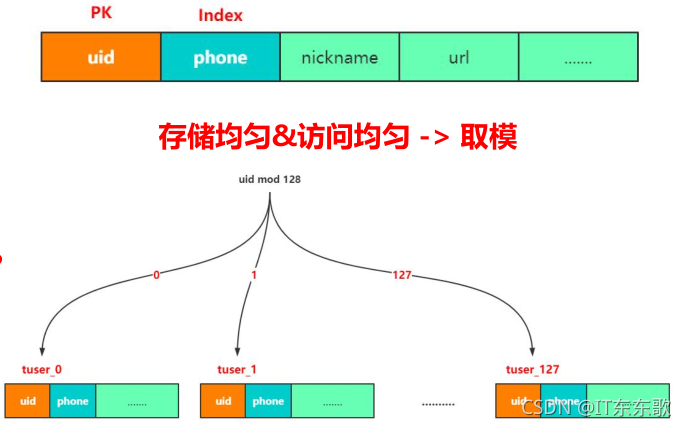
问题:如果查询手机号怎么做?
答案:做一个uid和phone的映射表
2、商品库分表
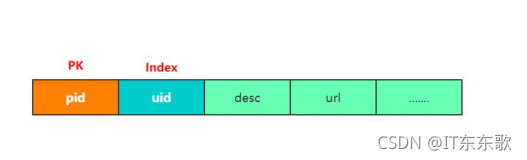
问题1:是否可以按照商品pid取模分表?
问题2:如果问题1可以的话,如果想查找用户下的商品怎么查,继续做映射表吗?
答案:肯定是不可以的,如果做表映射会发下,一个用户的多个商品会散列到不同的表里,这样有可能会查询多张表才能查到结果。
方案:基因注入法
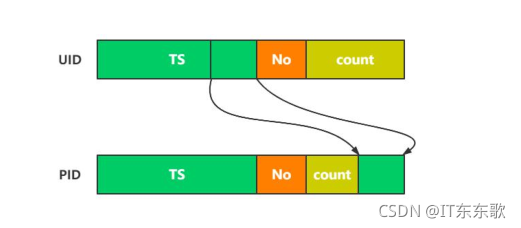
就是在用户生成的时候随机写入一个数字,以后把他的所有商品都用这个数字取模进行分配,这样用户的所有商品都会分到一个表中,减少查询次数。
3、系统消息库分表
a 时效性强
b 冷热数据拆分
假如30条有效,我们按照一个月一张表设计,

也有这么分表的
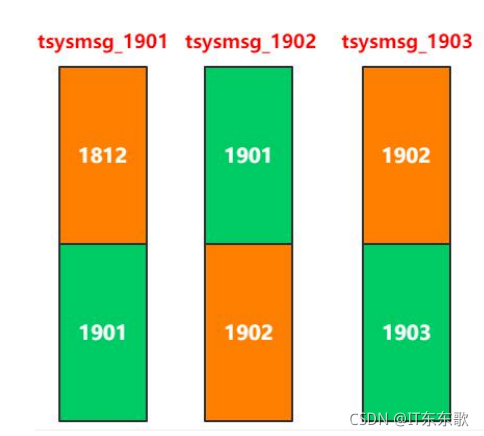
大家可以选择合适自己业务逻辑的
五、扩容--分表分少了
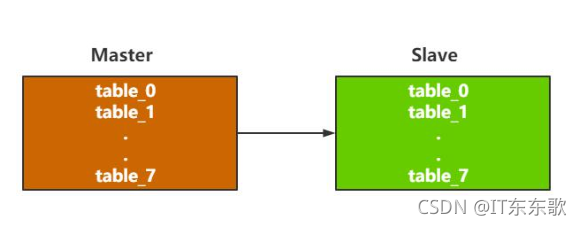
比如上图,一对主从,每个库各8张表:
1、此时再拉出来一套8+8=16个表的Slave来,同步master数据,
2、修改业务路由算法,和16取模,写入到新增的Slave中
3、删除数据。将新的Slave中的table_0-15多余的数据删掉,table_0里多存了table_8的数据,以此类推。
4、断开数据同步,重新组建先的主从

















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









