







很多时候当我们需要训练一个新的图像分类任务,我们不会完全从一个随机的模型开始训练,而是利用_预训练_的模型来加速训练的过程。我们经常使用在ImageNet上的预训练模型。
这是一种transfer learning的方法。我们常用以下两种方法做迁移学习。
fine tuning: 从一个预训练模型开始,我们改变一些模型的架构,然后继续训练整个模型的参数。
feature extraction: 我们不再改变预训练模型的参数,而是只更新我们改变过的部分模型参数。我们之所以叫它feature extraction是因为我们把预训练的CNN模型当做一个特征提取模型,利用提取出来的特征做来完成我们的训练任务。
以下是构建和训练迁移学习模型的基本步骤:
(1)初始化预训练模型
(2)把最后一层的输出层改变成我们想要分的类别总数
(3)定义一个optimizer来更新参数
(4)模型训练
1.数据准备
我们会使用hymenoptera_data数据集,下载.
这个数据集包括两类图片, bees 和 ants, 这些数据都被处理成了可以使用ImageFolder https://pytorch.org/docs/stable/torchvision/datasets.html#torchvision.datasets.ImageFolder来读取的格式。我们只需要把data_dir设置成数据的根目录,然后把model_name设置成我们想要使用的与训练模型: :: [resnet, alexnet, vgg, squeezenet, densenet, inception]
其他的参数有:
num_classes表示数据集分类的类别数
batch_size
num_epochs
feature_extract表示我们训练的时候使用fine tuning还是feature extraction方法。如果feature_extract = False,整个模型都会被同时更新。如果feature_extract = True,只有模型的最后一层被更新。
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torchvision import datasets, transforms, models
import matplotlib.pyplot as plt
import time
import os
import copy
print("Torchvision Version: ",torchvision.__version__)
# Top level data directory. Here we assume the format of the directory conforms
# to the ImageFolder structure
data_dir = "./hymenoptera_data"
# Models to choose from [resnet, alexnet, vgg, squeezenet, densenet, inception]
model_name = "resnet"
# Number of classes in the dataset
num_classes = 2
# Batch size for training (change depending on how much memory you have)
batch_size = 32
# Number of epochs to train for
num_epochs = 15
# Flag for feature extracting. When False, we finetune the whole model,
# when True we only update the reshaped layer params
feature_extract = True
# res输入数据维数
input_size = 224
2.读入数据
all_images = datasets.ImageFolder(os.path.join(data_dir,"train"),transforms.Compose([
transforms.RandomResizedCrop(input_size), #把每张图片变成resnet需要输入的维度224
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),]
))
loader = torch.utils.data.DataLoader(all_images,batch_size=batch_size,shuffle=True,num_workers=4)
img = next(iter(loader))[0]
img.shape
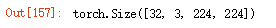
data_transforms = {
"train": transforms.Compose([
transforms.RandomResizedCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
"val": transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),#将给定的PIL.Image进行中心切割,得到给定的size,size可以是tuple,(target_height, target_width)。size也可以是一个Integer,在这种情况下,切出来的图片的形状是正方形。
transforms.ToTensor(),#把一个取值范围是[0,255]的PIL.Image或者shape为(H,W,C)的numpy.ndarray,转换成形状为[C,H,W],取值范围是[0,1.0]的torch.FloadTensor
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) #给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化。即:Normalized_image=(image-mean)/std。
])
}
image_datasets = {x:datasets.ImageFolder(os.path.join(data_dir,x),data_transforms[x]) for x in ['train','val']}
dataloader_dict = {x:torch.utils.data.DataLoader(image_datasets[x],
batch_size = batch_size,shuffle=True,num_workers=4) for x in ['train','val']}
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
unloader = transforms.ToPILImage() #将shape为(C,H,W)的Tensor或shape为(H,W,C)的numpy.ndarray转换成PIL.Image,值不变。
plt.ion() # 交互模式打开
def imshow(tensor,title=None): # reconvert into PIL image
image = tensor.cpu().clone() # we clone the tensor to not do changes on it
image = image.squeeze(0) # remove the fake batch dimension
image = unloader(image)
plt.imshow(image)
if title is not None:
plt.title(title)
plt.pause(0.001)
plt.figure()
imshow(img[11],title="Image")
def set_parameter_requires_grad(model,feature_extract):
if feature_extract:
for param in model.parameters():
param.requires_grad = False
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
if model_name == "resnet":
model_ft = models.resnet18(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 224
else:
print("model not implemented")
return None, None
return model_ft,input_size
model_ft, input_size = initialize_model(model_name,
num_classes, feature_extract, use_pretrained=True)
print(model_ft)

model_ft.layer1[0].conv1.weight.requires_grad

model_fit.fc.weight.requires_grad

3.模型训练
def train_model(model,dataloaders,loss_fn,optimizer,num_epochs=5):
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.
val_acc_history = []
for epoch in range(num_epochs):
for phase in ["train","val"]:
running_loss = 0.
running_corrects = 0.
if phase == "train":
model.train()
else:
model.eval()
for inputs,labels in dataloaders[phase]:
inputs,labels = inputs.to(device),labels.to(device)
# train求导,val不求导
with torch.autograd.set_grad_enabled(phase=="train"):
outputs = model(inputs) # [bsize,2]
loss = loss_fn(outputs, labels)
preds = outputs.argmax(dim=1)
if phase == "train":
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()*inputs.size(0)
running_corrects += torch.sum(preds.view(-1) == labels.view(-1)).item()
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects / len(dataloaders[phase].dataset)
print("Phase {} loss: {}, acc: {}".format(phase, epoch_loss, epoch_acc))
if phase == "val" and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == "val":
val_acc_history.append(epoch_acc)
model.load_state_dict(best_model_wts)
return model, val_acc_history
model_ft = model_ft.to(device)
optimizer = torch.optim.SGD(filter(lambda p: p.requires_grad,
model_ft.parameters()), lr=0.001, momentum=0.9)
loss_fn = nn.CrossEntropyLoss()
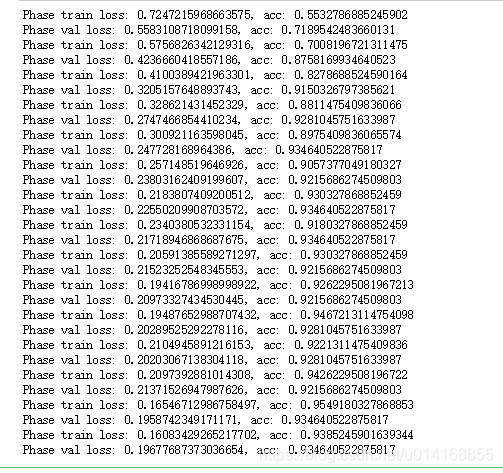
_, ohist = train_model(model_ft, dataloader_dict, loss_fn, optimizer, num_epochs=num_epochs)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









