







 本文介绍了ElasticSearch的基础概念,包括其定义、核心概念、数据架构与特点优势。同时,详细阐述了ES的增删改查操作及RESTful API的基本用法。
本文介绍了ElasticSearch的基础概念,包括其定义、核心概念、数据架构与特点优势。同时,详细阐述了ES的增删改查操作及RESTful API的基本用法。
ElasticSearch 学习笔记
一, ES 学习前言
1.1 ES 的定义
ES 是一个开源的高扩展分布式全文检索引擎,它可以实现存储,检索数据;扩展性好,可以扩展到上百台服务器,处理PB 级别的数据(1PB = 1024T = 1048576G)。
ES 是使用Java 开发并使用Lucene 作为核心来实现所有索引和搜索功能,它通过RESTF完全来隐藏Lucene 的复杂性,从而让全文搜索变得简单。
1.2 ES 的核心概念
l 集群:集群
ES 可以作为一个独立的单个搜索服务器。不过,为了处理大数据集,实现容错和高可用性,ES 可以运行在许多相互组合的服务器上。这些服务器的集合称为集群。
l 节点:节点
形成集群的每个服务器称为一个节点
l 碎片:分片
当有大量的文档时,由于内存的限制,磁盘处理能力不足,无法足够快速的响应客户端请求,一个节点可能不够,这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时, ES 会把查询发送给每一个分片,并且结果组合在一起,而应用程序并不知道分片的存在,即:这个过程对用户是透明的。
l Replia:副本
为了提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精准复制,每个分片可以有一个或多个副本。ES 中可以有许多相同的分片。主分片负责更改索引,其他分片负责提供查询。
当主分片丢失时,集群会重新选择一个副本提升为主分片。
升 全文检索
全文检索就是把内容根据词的意义进行分词,然后分别创建索引。
1.3 ES 数据架构的主要概念(与mysql 对比)
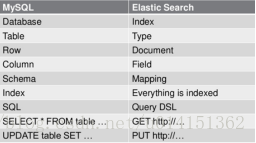
(1)关系型数据库中数据库( DataBase ),等价于ES 中的索引(index )
(2)一个数据库下有 N 张表(Table )等价于一个索引index 下面有N 多类型Type
(3)一个数据库表( Table )下的数据由多行(Row )多列(column )组成,等价于一个类型由多个文档(Document )和多个Field 组成。
(4)在一个关系型数据库里面, schema 定义了表,每个表的字段,还有表和字段之间的关系。与之对应的,在ES 中:Mapping 定义索引下的Type 的字段处理规则,即索引如何建立,索引类型,是否保存原始索引JSON 文档,是否压缩原始JSON 文档,是否需要分词处理,如何进行分词处理等。
(5)在数据库中的增插入,删除,改更新,查找搜索操作等价于ES 中的增PUT / POST ,删除,改_update ,查GET。
1.4 ES 的特点和优势
(1)分布式实时存储,可将每一个字段存入索引,使其可以被检索到。
(2)实时分析的分布式索引引擎。
分布式:索引分拆成多个分片,每个分片可以有零个或多个副本集群中的每个数据节点都可以承载一个或多个分片,并且协调和处理各种操作。
负载再平衡和路由在大多数情况下自动完成
(3)可以扩展到上百台服务器,处理 PB 级别的结构化或非结构化数据。也可以运行在单台PC 上。
(4)支持插件机制,分词插件,同步插件, Hadoop 插件,可视化插件等。
1.5 ES 的性能

二,ES 增,删,改,查详解
ES Restful API 中GET ,POST ,PUT ,DELETE ,HEAD 的含义:
(1)GET :获取请求对象的当前状态
(2)POST :改变对象的当前状态
(3)PUT :创建一个对象
(4)DELETE :销毁一个对象
(5)HEAD :请求获取对象的基本信息

















 2911
2911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









