







官方文档:https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html
MySQL从5.7一跃直接到8.0,这其中的缘由,咱就不关心那么多了,有兴趣的朋友自行百度,本次的版本更新,在功能上主要有以下6点:
- 账户与安全
- 优化器索引
- 通用表表达式
- 窗口函数
- InnoDB 增强
- JSON 增强
一、账户与安全
1.用户的创建与授权
在MySQL5.7的版本:
> grant all privileges on *.* to '用户名'@'主机' identified by '密码';
在MySQL8.0需要分开执行:
>create user '用户名'@'主机' identified by '密码';
>grant all privileges on *.* to '用户名'@'主机';
用以前的一条命令在8.0里面创建用户,会出现sql语法错误2.认证插件更新
MySQL5.7默认身份插件是mysql_native_password
MySQL8.0默认的身份插件是caching_sha2_password
查看身份认证插件命令:show variables like 'default_authentication_plugin%';
身份认证插件可以通过以下2中方式改变:
1)系统变量default_authentication_plugin去改变,在my.ini文件的[mysqld]下面设置default_authentication_plugin=mysql_native_password即可
2)如果希望只是某一个用户通过mysql_native_password的方式认证,可以修改数据库mysql下面的user表的字段,执行以下命令:
>alter user '用户名'@'主机' identified width mysql_native_password by '密码';
3.密码管理
MySQL8.0的密码管理策略有3个变量
password_history 修改密码不允许与最近几次使用或的密码重复,默认是0,即不限制
password_reuse_interval 修改密码不允许与最近多少天的使用过的密码重复,默认是0,即不限制
password_require_current 修改密码是否需要提供当前的登录密码,默认是OFF,即不需要;如果需要,则设置成ON
查询当前MySQL密码管理策略相关变量,使用以下命令:
>show variables like 'password%';
1)设置全局的密码管理策略,在my.ini配置文件中,设置以上3个变量的值这种设置方式,需要重启mysql服务器;某些生产环境不允许重启,MySQL8.0提供了关键字persist,持久化,执行以下命令:
>set persist password_history=6;
这条命令会在数据目录下生成新的配置文件(/var/lib/mysql/mysqld-auto.cnf),下次服务器重启的时候除了读取全局配置文件,还会读取这个配置文件,这条配置就会被读入从而达到持久化的目的
2)针对某一个用户单独设置密码管理策略
>alter user '用户名'@'主机' password history 5;
这样,这个用户的password_history 就被设置成了5,查看一下:
>show user,host,Password_reuse_history from user;
查看某一张的字段的所有字段,使用以下命令:
>desc 表名;
4.角色管理
角色:一组权限的集合
一组权限赋予某个角色,再把某个角色赋予某个用户,那用户就拥有角色对应的权限
1)创建一个角色
>create role '角色1';
2)为这个角色赋予相应权限
>grant insert,update on *.* to '角色1';
3)创建一个用户
>create user '用户1' identified by '用户1的密码';
4)为这个用户赋予角色的权限
>grant '角色1' on *.* to '用户1';
执行完上面4步,用户1就拥有了插入与更新的权限
5)再创建1个用户
>create user '用户2' identified by '用户2的密码';
6)为这个用户赋予同样的角色
>grant '角色1' on *.* to '用户2';
执行完上面2步,用户2也用了角色1的权限,即插入与更新
查看用户权限,执行以下命令:
>show grants for '用户名';
7)启用角色,设置了角色,如果不启用,用户登录的时候,依旧没有该角色的权限
>set default role '角色名' to '用户名';
8)如果一个用户有多个角色,使用以下命令
>set default role all to '用户名';
MySQL中与用户角色相关的表:mysql.default_roles、mysql.role_edges,有兴趣的朋友可以进去查看下。
9)撤销权限
>revoke insert,update on *.* from '角色名';
二、优化器索引
1.隐藏索引(invisible index)
隐藏索引不会被优化器使用,但仍需要维护
应用场景:
1)软删除
删除索引,在线上,如果删除错了索引,只能通过创建索引的方式将其添加回来,对于一些大的数据库而言,是比较耗性能的;为了避免删错,可以先将其设置为不可见,优化器这时候就不会使用它,但是后台仍然在维护,确定后,再删除。
2)灰度发布
与软删除差不多,如果想要测试一些索引的功能或者随后可能会使用到这个索引,可以先将其设置为隐藏索引,对于现有的查询不会产生影响,测试后,确定需要该索引,可以将其设置成可见索引。
创建隐藏索引,执行如下命令(如果是不隐藏,则不需要后面的invisible关键字):
>create index 索引名称 on 表名(字段名) invisible;
查询某一张表的索引,执行如下命令:
>show index from 表名;
使用explain语句查看查询优化器对索引的使用情况
>explain select * from 表名 where 条件;
查询优化器有很多开关,有一个是use_invisible_indexes(是否使用隐藏索引),默认是off(不适用),将其设置成on,即可使用隐藏索引。查看当前查询优化器的所有开关变脸,执行如下命令:
>select @@optimizer_switch;
设置已经存在的索引为可见或者隐藏,执行如下命令:
>alter table 表名 alter index 索引名 visible;
>alter table 表名 alter index 索引名 invisible;
主键不可以设置为隐藏所以。2.降序索引(descending index)
MySQL8.0开始真正支持降序索引,只有InnoDB引擎支持降序所以,且必须是BTREE降序索引,MySQL8.0不在对group by操作进行隐式排序。3.函数索引
索引中使用函数表达式
支持JSON数据节点的索引
函数索引是基于虚拟列的功能实现的
假设用户表(tb_user)的的用户登录账号(username)不需要区分大小写,则可以创建一个函数索引
>create index username_upper_index on tb_user((upper(username)));
这样在查询的时候 SELECT * FROM tb_user WHERE upper(username) = 'ABD123DSJ'; 就会使用索引。
上面的函数索引,也可以通过MySQL5.7已有的虚拟计算列来模拟,为用户表(tb_user)创建新的一列(new_column),这一列是计算列,不需要赋值,它的值就是username的大写。
>alter tbale tb_user add column new_column varchar(10) generated always as (upper(username));
然后给new_column创建一个索引,可以达到模拟MySQL8.0中的函数索引的效果。
三、通用表表达式
1.非递归 CTE
派生表:select * from (select 1) as dt;
通用表表达式:with cte as (select 1) select * from cte;
with cte1(id) as (select 1),cte2 as (select id+1 from cte1) select * from cte1 join cte2;
2.递归 CTE
四、窗口函数
MySQL中还有许多其他的窗口函数,本文列举一些,大家可以自行测试
| 类别 | 函数 | 参数 | 说明 |
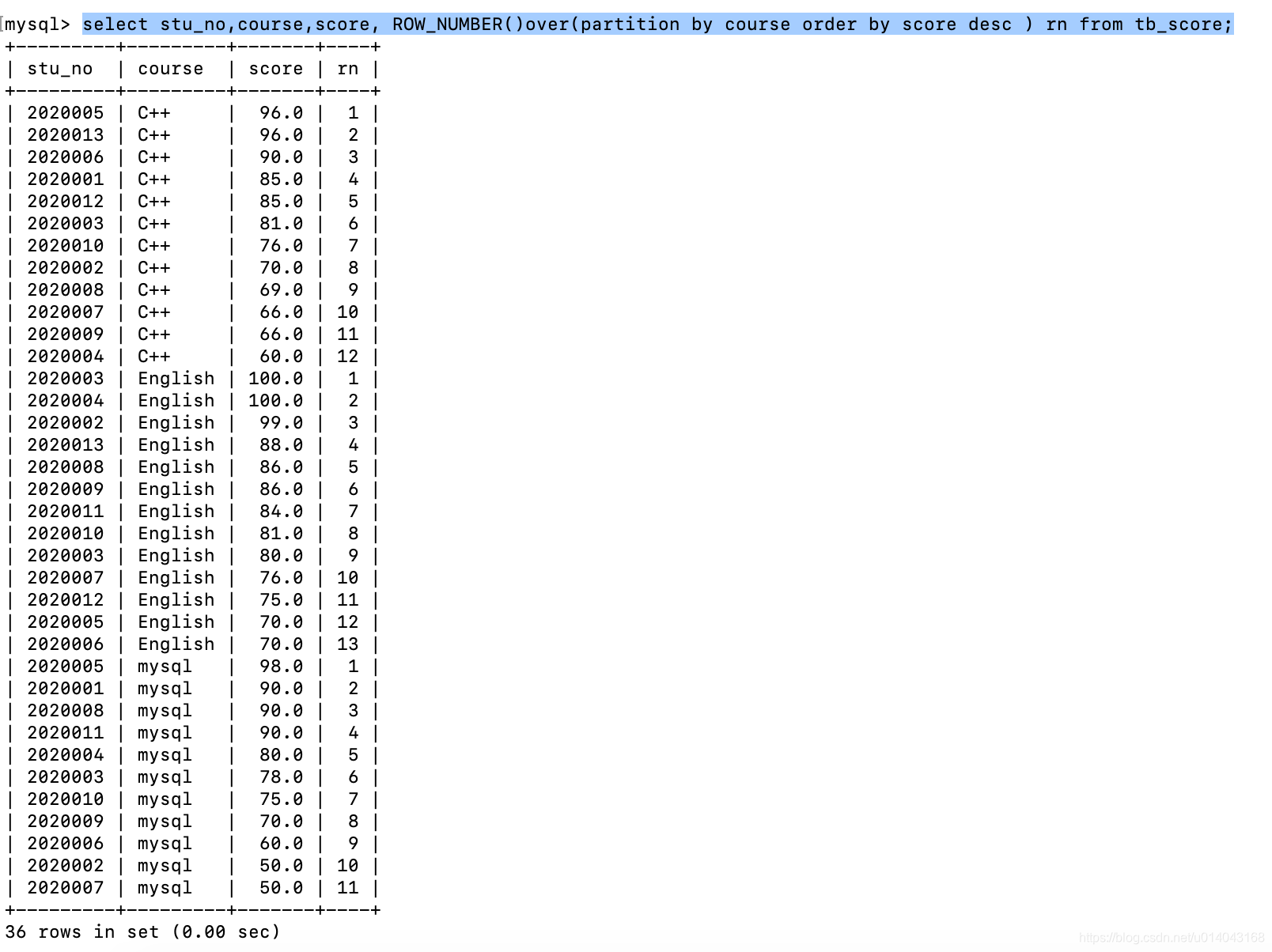
| 排序 | ROW_NUMBER | ROW_NUMBER() over_clause | 为表中的每一行分配一个序号,可以指定分组(也可以不指定)及排序字段 |
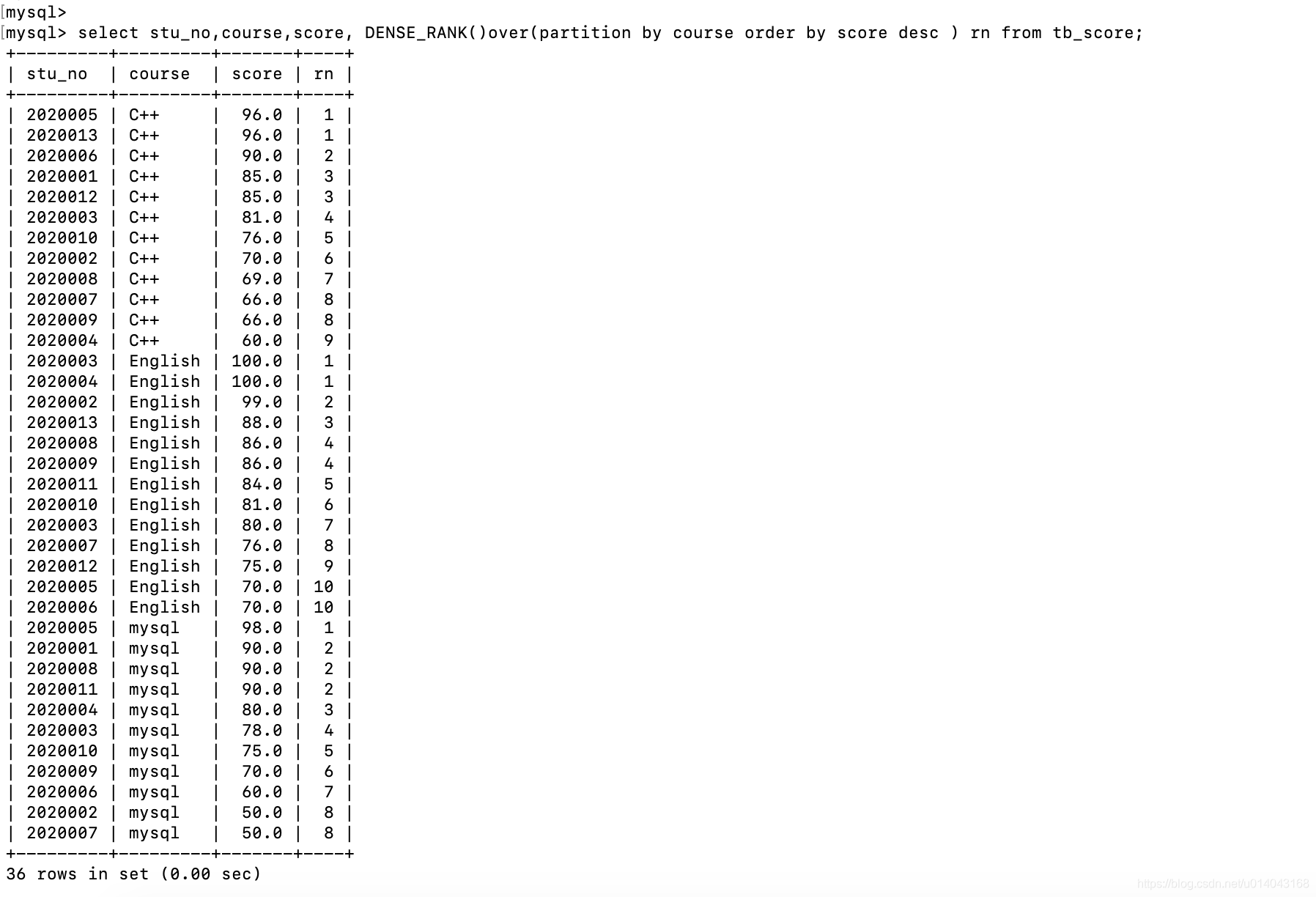
| DENSE_RANK | DENSE_RANK() over_clause | 根据排序字段为每个分组中的每一行分配一个序号。 排名值相同时,序号相同,序号中没有间隙(1,1,2,3这种) | |
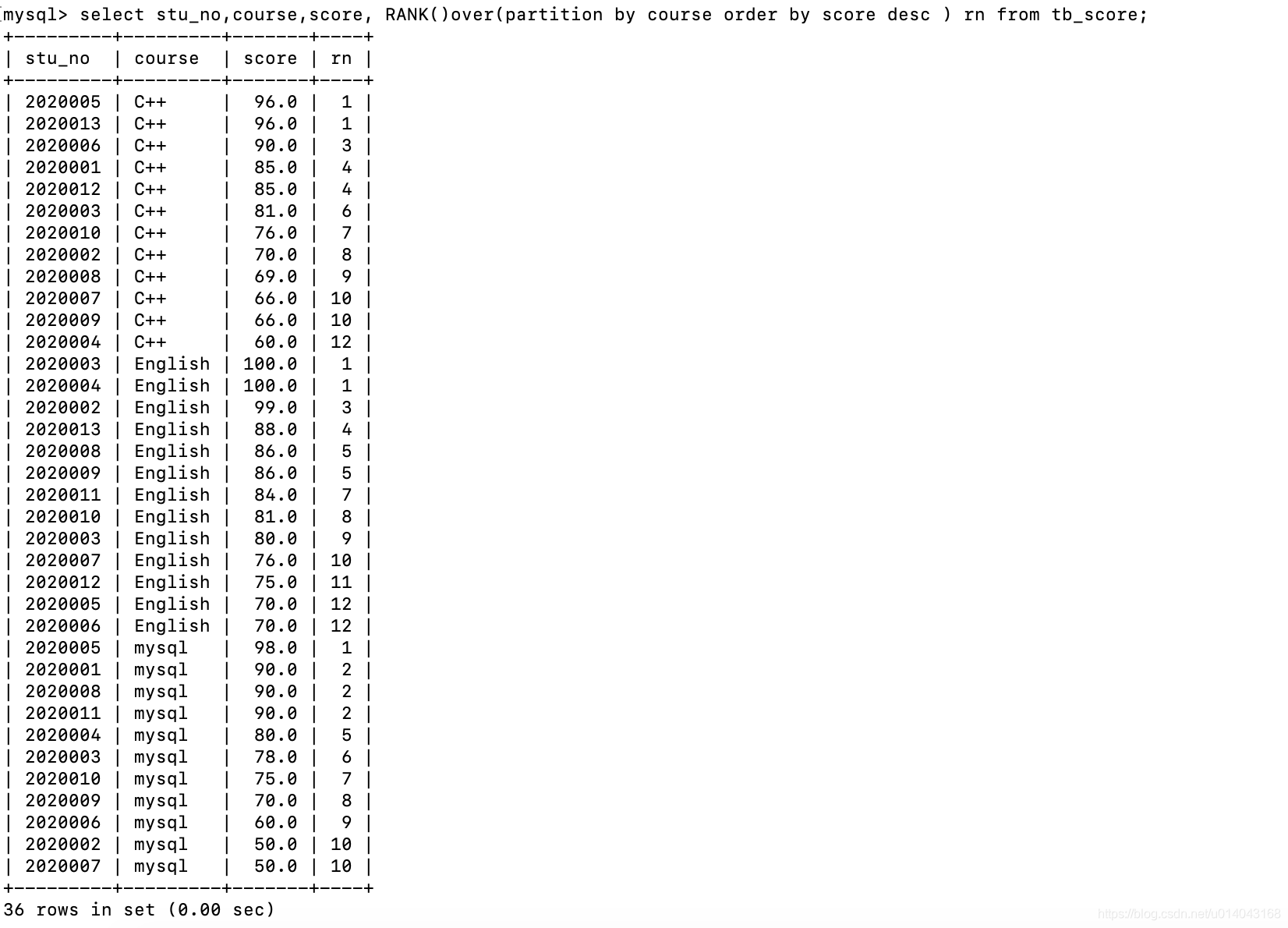
| RANK | RANK() over_clause | 根据排序字段为每个分组中的每一行分配一个序号。 排名值相同时,序号相同,但序号中存在间隙(1,1,3,4这种) | |
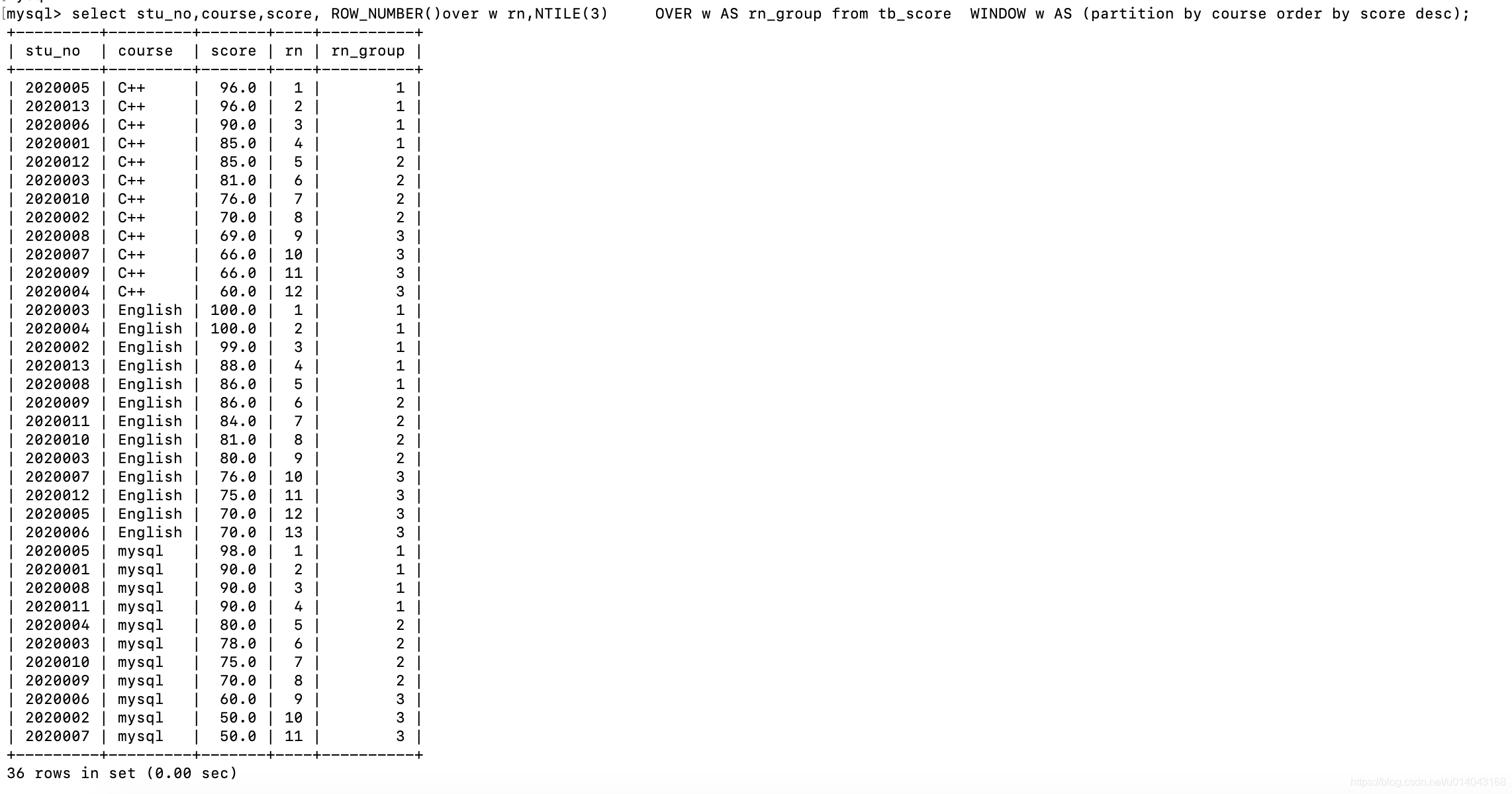
| NTILE | NTILE(N) over_clause | 根据排序字段为每个分组中根据指定字段的排序再分成对应的组(具体分组算法不明,建议不要使用) | |
| 分布 | PERCENT_RANK | PERCENT_RANK() over_clause | 计算各分组或结果集中行的百分数等级 |
| CUME_DIST | CUME_DIST() over_clause | 计算某个值在一组有序的数据中累计的分布 | |
| 前后 | LEAD | LEAD(expr [, N[, default]]) | 返回分组中当前行之后的第N行的值。如果不存在对应行,则返回NULL。比如N=1时,第一名对应的值是第二名的,最后一名结果是NULL |
| LAG | LAG(expr [, N[, default]]) | 返回分组中当前行之前的第N行的值。如果不存在对应行,则返回NULL。比如N=1时,第一名对应的值是是NUL,最后一名结果是倒数第2的值 | |
| 首尾中 | FIRST_VALUE | FIRST_VALUE(expr) [null_treatment] over_clause | 返回每个分组中第一名对应的字段(或表达式)的值,例如本文中可以是第一名的分数、学号等任意字段的值 |
| LAST_VALUE | LAST_VALUE(expr) [null_treatment] over_clause | 返回每个分组中最后一名对应的字段(或表达式)的值,例如本文中可以是最后一名的分数、学号等任意字段的值 | |
| NTH_VALUE | NTH_VALUE(expr, N) [from_first_last] [null_treatment] over_clause | 返回每个分组中排名第N的对应字段(或表达式)的值,但小于N的行对应的值是NULL |
MySQL中主要的窗口函数先总结这么多,建议还是得动手实践一番。另外,MySQL5.7及之前版本的排序方式的实现很多人已总结,也建议实操一番。
示例:
#生成测试数据
create table tb_score(id int primary key auto_increment,stu_no varchar(10),course varchar(50),score decimal(4,1),key idx_stuNo_course(stu_no,course));
insert into tb_score(stu_no,course,score)values('2020001','mysql',90),('2020001','C++',85),('2020003','English',100),('2020002','mysql',50),('2020002','C++',70),('2020002','English',99);
insert into tb_score(stu_no,course,score)values('2020003','mysql',78),('2020003','C++',81),('2020003','English',80),('2020004','mysql',80),('2020004','C++',60),('2020004','English',100);
insert into tb_score(stu_no,course,score)values('2020005','mysql',98),('2020005','C++',96),('2020005','English',70),('2020006','mysql',60),('2020006','C++',90),('2020006','English',70);
insert into tb_score(stu_no,course,score)values('2020007','mysql',50),('2020007','C++',66),('2020007','English',76),('2020008','mysql',90),('2020008','C++',69),('2020008','English',86);
insert into tb_score(stu_no,course,score)values('2020009','mysql',70),('2020009','C++',66),('2020009','English',86),('2020010','mysql',75),('2020010','C++',76),('2020010','English',81);
insert into tb_score(stu_no,course,score)values('2020011','mysql',90),('2020012','C++',85),('2020011','English',84),('2020012','English',75),('2020013','C++',96),('2020013','English',88);ROW_NUMBER :
select stu_no,course,score, ROW_NUMBER()over(partition by course order by score desc ) rn from tb_score;
DENSE_RANK:
select stu_no,course,score, DENSE_RANK()over(partition by course order by score desc ) rn from tb_score;
RANK:
select stu_no,course,score, RANK()over(partition by course order by score desc ) rn from tb_score;
NTILE:
select stu_no,course,score, ROW_NUMBER()over w rn,NTILE(3) OVER w AS rn_group from tb_score WINDOW w AS (partition by course order by score desc);
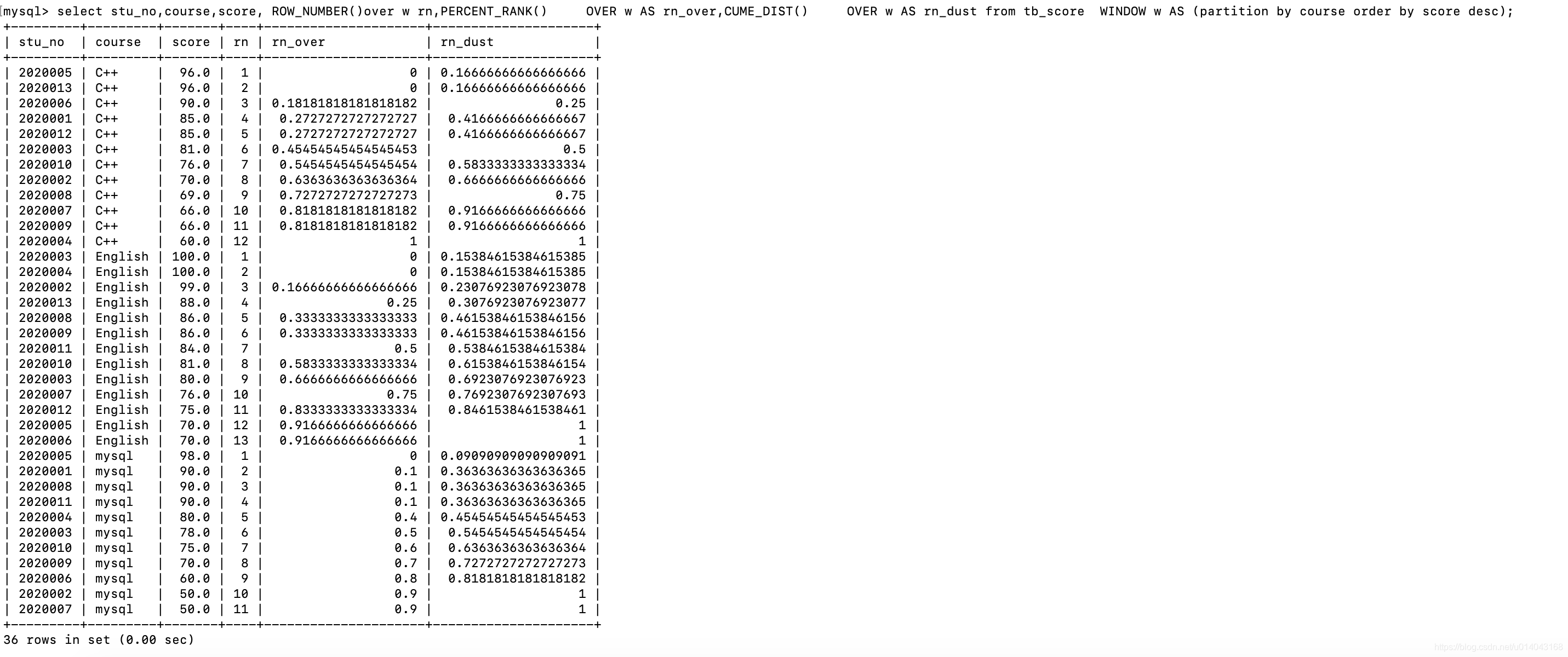
PERCENT_RANK/CUME_DIST:
select stu_no,course,score, ROW_NUMBER()over w rn,PERCENT_RANK() OVER w AS rn_over,CUME_DIST() OVER w AS rn_dust from tb_score WINDOW w AS (partition by course order by score desc);
LEAD:
select stu_no,course,score, RANK()over w rn,LEAD(score) OVER w AS 'LEAD', score - LEAD(score) OVER w AS diffent from tb_score WINDOW w AS (partition by course order by score desc);

LAG:
select stu_no,course,score, RANK()over w rn,LAG(score) OVER w AS 'LAG', LAG(score) OVER w - score AS diffent from tb_score WINDOW w AS (partition by course order by score desc);

五、InnoDB增强
1.集成数据字段
2.原子ddl操作
MySQL5.7执行drop命令 drop table t1,t2; 如果t1存在,t2不存在,会提示t2表不存在,但是t1表仍然会被删除。
MySQL8.0执行同样的drop命令,会提示t2表不存在,而且t1表不会被删除,保证了原子性。
ddl操作(针对表)的原子性前提是该表使用的存储引擎是InnoDB
3.自增列持久化
解决了之前的版本,主键重复的问题。
MySQL5.7及其以前的版本,MySQL服务器重启,会重新扫描表的主键最大值,如果之前已经删除过id=100的数据,但是表中当前记录的最大值如果是99,那么经过扫描,下一条记录的id是100,而不是101。
MySQL8.0则是每次在变化的时候,都会将自增计数器的最大值写入redo log,同时在每次检查点将其写入引擎私有的系统表。则不会出现自增主键重复的问题。
4.死锁检查控制5.锁定语句选项
六、JSON增强
1.内联路径操作符
column->>path
等价于之前的:
JSON_UNQUOTE(column -> path)
JSON_UNQUOTE(JSON_EXTRACT(column,path))
2.JSON聚合函数
MySQL8.0和MySQL5.7.22增加了2个聚合函数
1)JSON_ARRAYAGG(),将多行数据组合成json数组

示例:select o_id,json_arrayagg(attribute) as attributes from t group by o_id;

2)JSON_OBJECTAGG(),用于生成json对象
示例:select o_id json_objectagg(attribute,value) as attributes from t group by o_id;

注意:json的聚合函数针对重复key,会使用最后的覆盖前面已有的值,如果下面的o_id=3,它的color有2个值,一个green,一个yellow,使用生成json的聚合函数的时候,前面的green会被覆盖掉。


3.JSON实用函数
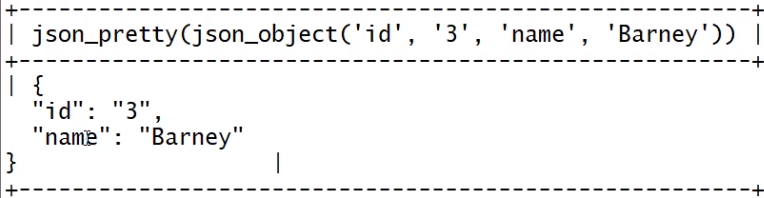
1)JSON_PRETTY() 输出json数据的时候,格式化。
select json_object('id',3,'name','Barney');

select json_pretty(json_object('id',3,'name','Barney'));
2)JSON_STORAGE_SIZE() json数据所占用的存储空间(单位:字节)
3)JSON_STORAGE_FREE() json数据更新后所释放的空间(单位:字节)
4.JSON合并函数
MySQL8.0废弃了JSON_MERGE()函数,推荐使用以下两个函数合并JSON数据
1)JSON_MERGE_PATCH()
2)JSON_MERGE_PRESERV()
上面两个函数都是JSON数据合并,最大的区别就是前者遇到相同key的时候会用后面的覆盖前面的,后者会都保留,看下面的截图:

5.JSON表函数
MySQL8.0新增了JSON_TABLE()函数,将JSON数据转换成关系表,可以将该函数的返回结果当做一个普通的临时表进行sql查询。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









