







这篇文章来回答这个问题:当应用层提交了一个事务,mysql底层是如何将增删改写入到最底层的.ibd文件中,并保证这个已提交的事务的原子性和持久性的
为了解决这个问题,要分析mysql的写过程。
整体上来看,可以分为这两大部分:
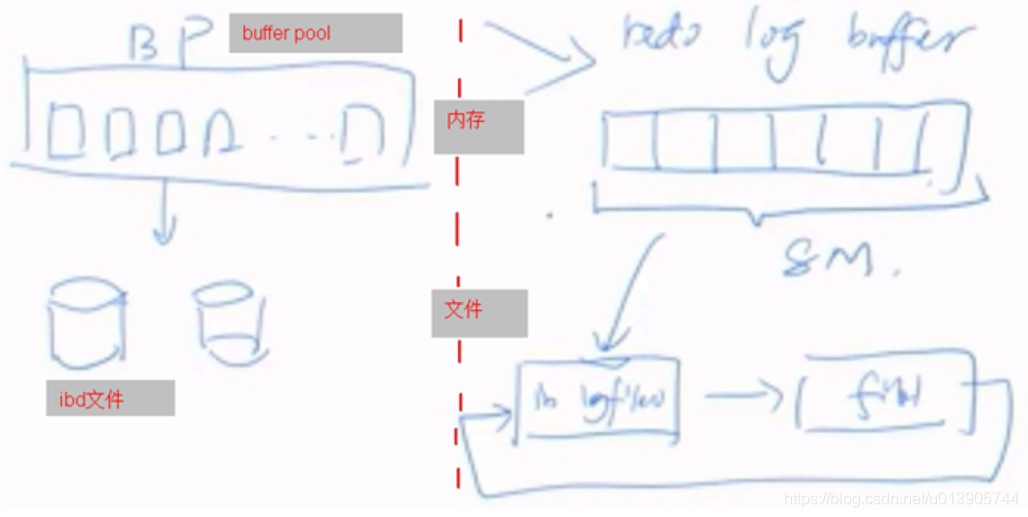
左侧为数据部分。左侧上部分是innodb内存缓冲池buffer pool,左侧下部分是磁盘上的record记录.ibd文件
右侧为redo log部分。右侧上部分为redo log buffer,右侧下部分为redo log file。
关于redo log,可参考:mysql面试关键知识点:redo log
背景知识
LSN(log sequence number)
由于要保证事务的原子性和持久性,需要引入一个版本的概念。在mysql中使用log sequence number 来标记版本。LSN 是8字节的数字。
mysql中的LSN分布
-
重做日志中的LSN
比如一个新的页,LSN是有一个初始值的,比如说16,这时我对这个页进行了修改,那会产生redo log日志,比如说这个日志为10个字节,LSN就变为26,这个时候又进行了修改,产生redo log 20个字节,LSN就变为46了,所以LSN是一个单调递增的值,这个是重做日志中的LSN
-
每个数据页的LSN
在每个数据页中也有LSN,表示这个页在做修改的时候,在做checkpoint的时候,其LSN值是多少(即当时对应的重做日志的LSN是多少)
在每个数据页的头部FILE_HEADER部分,有一个FIL_PAGE_LSN—记录了该数据页最后被修改的日志序列位置。
-
checkpoint的LSN
在每个database里面,还有一个叫checkpoint的LSN
checkpoint的LSN代表的是最后一次刷新到磁盘的那个页的LSN,其意义就是在这个LSN之前的脏页,都已经被写入了,是保存在重做日志redo log前2k大小的区域中的
mysql的checkpoint是记录在redo log file的前2K字节中(一个log block=512 bytes,所以是前4个log block)
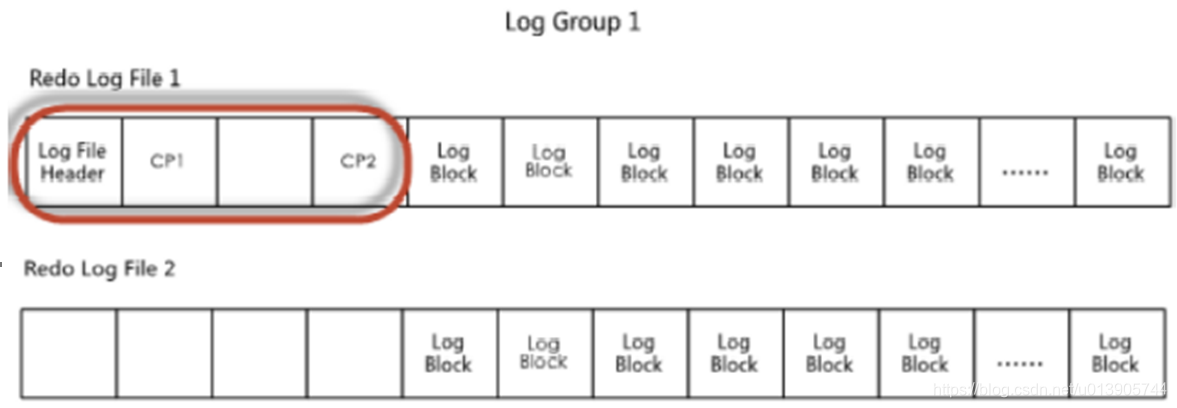
存在两个checkpoint(cp1,cp2),两个checkpoint循环写入,设计成两个,主要是为了容灾考虑。
buffer pool
每次读写数据都是通过Buffer Pool ;
当Buffer Pool 中没有用户所需要的数据时,才去硬盘中获取;
首先将从磁盘读到的页存放在缓冲池中,这个过程称为将页“FIX ”在缓冲池中。下一次再读相同的页时,首先判断该页是否在缓冲池中。若在缓冲池中,称该页在缓冲池中被命中,直接读取该页。否则,读取磁盘上的页。
看一下其读写的基本过程
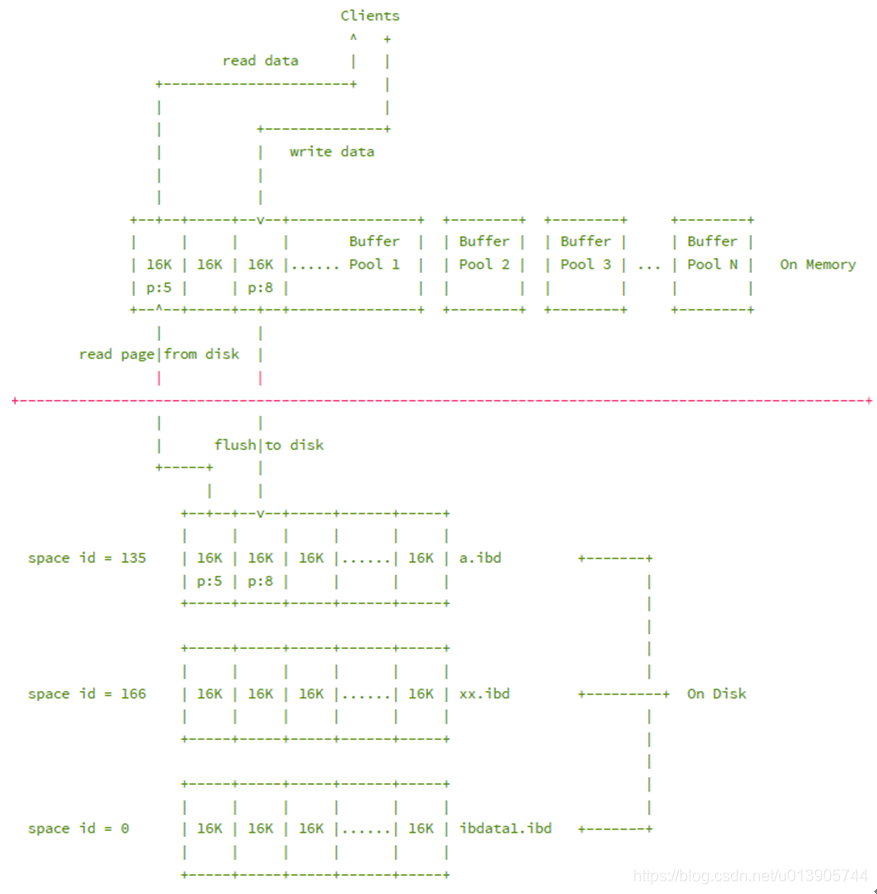
buffer pool中的是由
- Free List
- LRU List
- Flush List
组成的
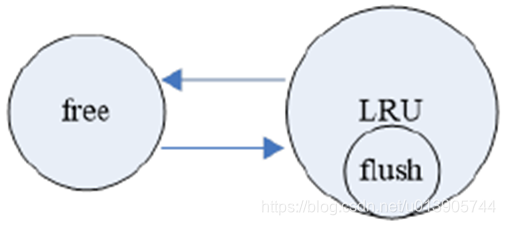
比如说buffer pool分配了2G,对应着很多默认16k的块/页,那这一个一个的块就是存放在free list里面的。
当我要读取一个页的时候,我就从free list中要一个块,把这个块加入到lru list中去,那么这个块就从free list中拿掉,放到LRU list中去
如果这个页被修改了,那就会放到flush list中,实际上是把这个脏页的指针放到flush list中的。
部分写失效及Double Write
当发生数据库宕机时,可能lnnoDB存储引擎正在写入某个页到磁盘中,而这个页只写了一部分,比如16KB 的页,只写了前4KB,之后就发生了宕机,这种情况被称为部分写失效(partial page write)。在InnoDB 存储引擎未使用double write技术前,曾经出现过因为部分写失效而导致数据丢失的情况。
通过redo log进行恢复,那么磁盘上的这个页一定要是完整干净的。发生partial page write,磁盘上的这个页已经corrupt了(非物理介质的corrupt),无法通过redo log进行恢复了。如何处理部分写失效的问题呢?
解决方案:在写一个脏页之前,找一个地方去记录这个页的副本,当部分写失效发生时,先通过页的副本在磁盘上还原该页,再进行重做,这就是double write。
double write 由两部分组成,一部分是内存中的doublewrite buffer,大小为2MB,另一部分是物理磁盘上共享表空间(double write段)中连续的128个页128*16=2M,即2个区(extent),大小同样为2MB。
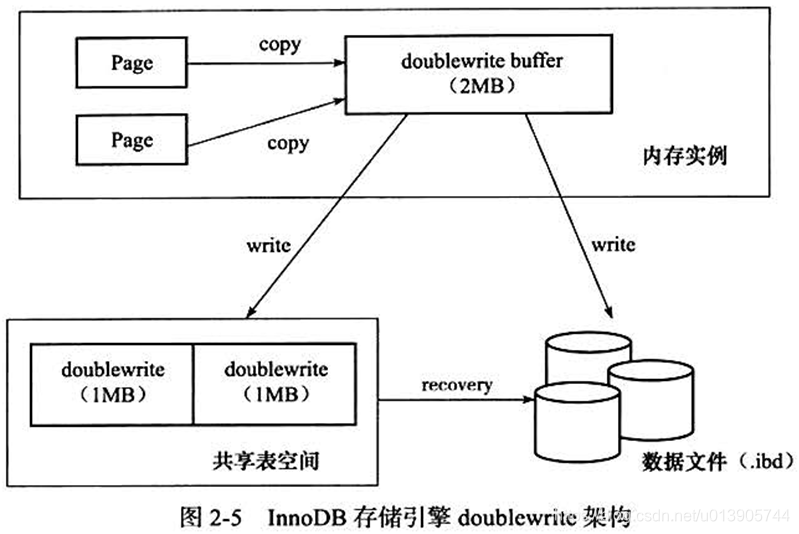
在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是会通过memcpy函数将脏页先复制到内存中的doublewrite buffer,之后通过doublewrite buffer再分两次,每次1MB顺序地写入共享表空间的物理磁盘上,然后马上调用fsync 函数,同步磁盘,避免缓冲写带来的问题。
在完成doublewrite页的写入后,再将doublewrite buffer 中的页写入各个表空间文件中,此时的写入则是离散的,通过space和page_no刷新到.ibd文件中。
写过程
从应用层提交了一个事务开始
-
数据页首先被读入缓冲池中,当数据页中的某几条记录被更新或者插入新的记录时,所有的操作都是在Buffer Pool先完成的;修改内存中的数据页时,会在数据页中记录LSN,暂且称之为data_in_buffer_lsn;
Buffer Pool中的某个页和磁盘中的某个页在(Space, Page_Number)上是相同的,但是其内容可能是不同的(Buffer Pool中的被更新过了),形成了脏页;
-
在修改数据页的同时(几乎是同时)向redo log buffer中写入redo log,并记录下对应的LSN,暂且称之为redo_log_in_buffer_lsn;
-
写完redo log buffer中的日志后,当触发了redo log刷盘的几种规则时,会向redo log file on disk刷入重做日志,并在该文件中记下对应的LSN,暂且称之为redo_log_on_disk_lsn;
redo log刷盘时机
1. master thread每秒进行刷新
2. redo log buffer使用大于1/2进行刷新
3. 事务提交时进行刷新 -
数据页不可能永远只停留在内存中,在某些情况下,会触发checkpoint来将内存中的脏页(数据脏页和日志脏页)刷到磁盘,所以会在本次checkpoint脏页刷盘结束时,在redo log中记录checkpoint的LSN位置,暂且称之为checkpoint_lsn。
什么时候触发checkpoint呢?
1. 缓冲池innodb buffer pool不够用时,将脏页刷新到磁盘
2. 重做redo log日志不可用(覆盖写的时候发现脏页未刷盘)时,刷新脏页
3. innodb_io_capacity,默认是200。这个参数控制多少个脏页触发checkpoint,以这个参数很重要,值大一点,那么写的能力就会提高起来,但如果值很大,那么可能就会hang住 -
对于数据脏页,通过double write来提高数据写入的可靠性。参考上面的double write流程,在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是会通过memcpy函数将脏页先复制到内存中的doublewrite buffer,之后通过doublewrite buffer再分两次,每次1MB顺序地写入共享表空间的物理磁盘上,然后马上调用fsync 函数,同步磁盘,避免缓冲写带来的问题。
在完成doublewrite页的副本写入后,再将doublewrite buffer 中的页写入各个表空间文件中,此时的写入则是离散的,通过space和page_no刷新到.ibd文件中。 -
对于日志脏页,redo log block的512个字节与磁盘扇区大小一样,所以重做日志的写入可以保证原子性,不需要double write。
-
要记录checkpoint所在位置很快,只需简单的设置一个标志即可,但是刷数据页并不一定很快,例如这一次checkpoint要刷入的数据页非常多。也就是说要刷入所有的数据页需要一定的时间来完成,中途刷入的每个数据页都会记下当前页所在的LSN,暂且称之为data_page_on_disk_lsn。
-
在刷新数据脏页的时候,mysql采用了 刷新邻近页 (flush neighbor page, FNP)的优化策略,这个优化的思想是:随机转顺序。
当刷新一个脏页时,InnoDB 存储引擎会检测该页所在区(extent)的所有页,如果是脏页,那么一起进行刷新。这样做的好处显而易见,通过AIO可以将多个IO写入操作合并为一个IO操作,故该工作机制在传统机械磁盘下有着显著的优势。 -
刷新完成,则写入完成。
整个SLN的变化过程如下图所示
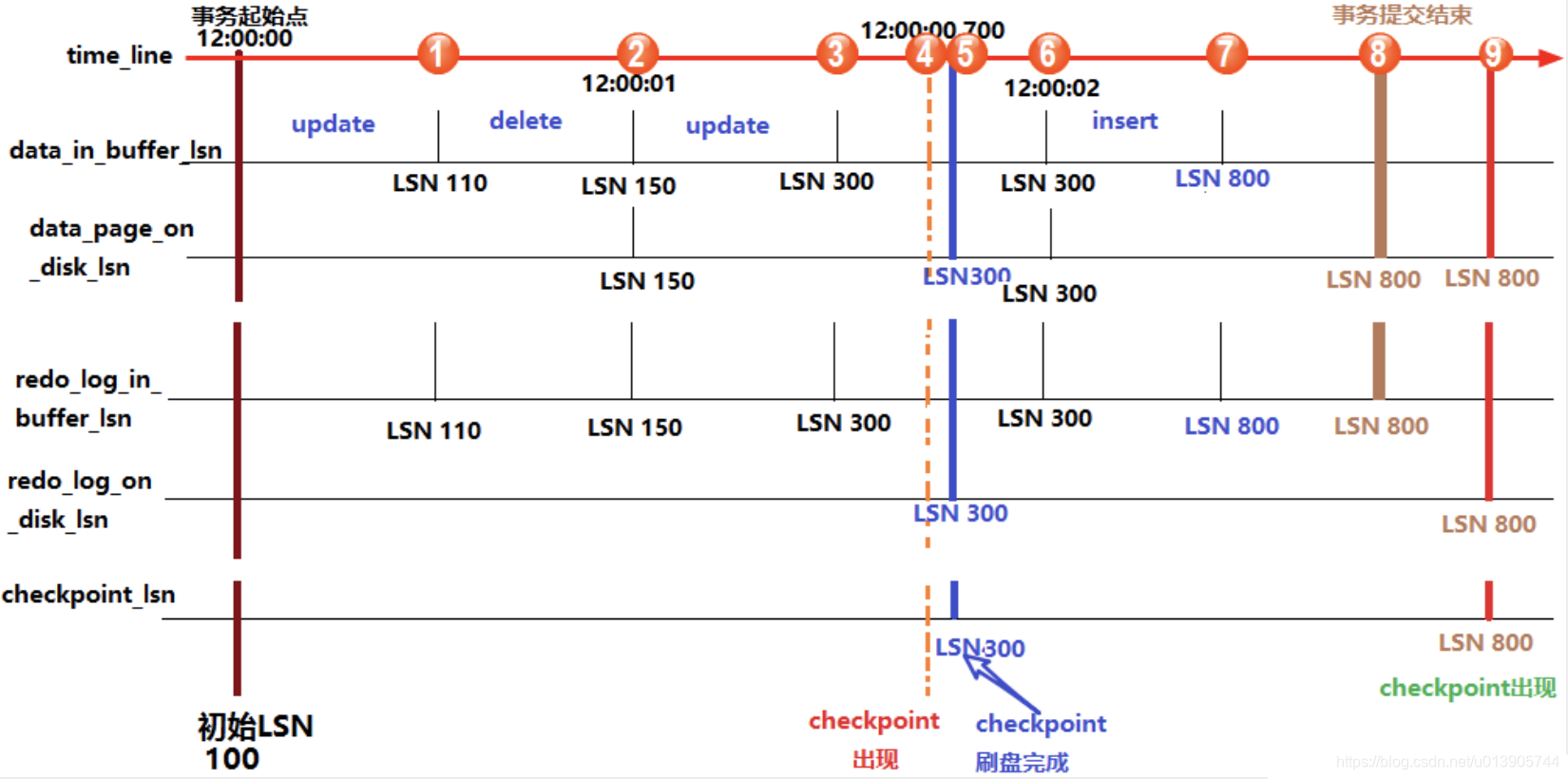
此部分参考:Innodb中LSN(log sequence number)详解
起点
假设在最初时(12:0:00)所有的日志页和数据页都完成了刷盘,也记录好了检查点的LSN,这时它们的LSN都是完全一致的。
位置1
假设此时开启了一个事务,并立刻执行了一个update操作,执行完成后,buffer中的数据页和redo log都记录好了更新后的LSN值,假设为110。这时候如果执行 show engine innodb status 查看各LSN的值,即图中①处的位置状态,结果会是:
log sequence number(110) > log flushed up to(100) = pages flushed up to = last checkpoint at
位置2
之后又执行了一个delete语句,LSN增长到150。等到12:00:01时,触发redo log刷盘的规则(其中有一个规则是 innodb_flush_log_at_timeout 控制的默认日志刷盘频率为1秒),这时redo log file on disk中的LSN会更新到和redo log in buffer的LSN一样,所以都等于150,这时 show engine innodb status ,即图中②的位置,结果将会是:
log sequence number(150) = log flushed up to > pages flushed up to(100) = last checkpoint at
位置3
再之后,执行了一个update语句,缓存中的LSN将增长到300,即图中③的位置。
位置4
假设随后checkpoint检查点出现,即图中④的位置,正如前面所说,checkpoint检查点会触发数据页和日志页刷盘,但需要一定的时间来完成,所以在数据页刷盘还未完成时,检查点的LSN还是上一次检查点的LSN,但此时磁盘上数据页和日志页的LSN已经增长了,即:
log sequence number > log flushed up to 和 pages flushed up to > last checkpoint at
但是log flushed up to和pages flushed up to的大小无法确定,因为日志刷盘可能快于数据刷盘,也可能等于,还可能是慢于。但是checkpoint机制有保护数据刷盘速度是慢于日志刷盘的:当数据刷盘速度超过日志刷盘时,将会暂时停止数据刷盘,等待日志刷盘进度超过数据刷盘。
位置5
等到数据页和日志页刷盘完毕,即到了位置⑤的时候,所有的LSN都等于300。
位置6
随着时间的推移到了12:00:02,即图中位置⑥,又触发了日志刷盘的规则,但此时buffer中的日志LSN和磁盘中的日志LSN是一致的,所以不执行日志刷盘,即此时 show engine innodb status 时各种lsn都相等。
位置7
随后执行了一个insert语句,假设buffer中的LSN增长到了800,即图中位置⑦。此时各种LSN的大小和位置①时一样。
log sequence number(800) > log flushed up to = pages flushed up to = last checkpoint at
位置8
随后执行了提交动作,即位置⑧。默认情况下,提交动作会触发日志刷盘,但不会触发数据刷盘,所以 show engine innodb status 的结果是:
log sequence number = log flushed up to > pages flushed up to = last checkpoint at
位置9
最后随着时间的推移,检查点再次出现,即图中位置⑨。但是这次检查点不会触发日志刷盘,因为日志的LSN在检查点出现之前已经同步了。假设这次数据刷盘速度极快,快到一瞬间内完成而无法捕捉到状态的变化,这时 show engine innodb status 的结果将是各种LSN相等。
基于redo log实现事务的原子性及持久性
场景1:业务端提交到buffer pool中失败
由于还没有记录到redo log file中,说明此事务提交失败。数据并没有保存到.ibd磁盘文件中,对数据库没有影响。
场景2:在buffer pool中已经修改了,还没有刷到磁盘之前,数据库发生down机了
down机了,也没关系,因为每个页在修改的时候,都将日志写入了redo log。那么mysql重启了,通过回放redo log,还是可以实现磁盘数据更新
场景3:写入到共享表空间的时候发生partial page write
因为磁盘上.ibd文件中的页还是干净的,没有发生corrupt,数据还是一致的,这些页仍然可以通过redo log进行恢复,因为这个页仍处于一致的状态,并没有不一致。
场景4:写到.ibd文件中发生partial write
在double write这个对象里面,是有这个页的一个副本(在共享表空间中),可以把对应这个页的副本(最新的)copy到.ibd文件中,然后再通过redo log进行恢复。
场景5:mysql数据库启动时进行检测
例如,页P1的LSN 为10000,而数据库启动时,lnnoDB检测到redo log中的LSN为13000,并且该事务已经提交,那么数据库需要进行恢复操作,将redo log replay应用到P1页中。
场景6:mysql宕机后恢复
再例如,当数据库在checkpoint的LSN为10000时发生宕机,由于checkpoint表示已经刷新到磁盘页上的LSN,因此在恢复过程中仅需恢复checkpoint开始的日志部分,恢复操作仅恢复LSN 10000~13000范围内的日志。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









