







🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 —— 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
文章目录
- 1. 背景介绍
- **2. 相关工作**
- **3. 数据集**
- **4. 方法(METHOD)**
- **5. 实验**
- **6. 结论**
1. 背景介绍
Zhou P, Min W, Fu C, et al. FoodSky: A Food-oriented Large Language Model that Passes the Chef and Dietetic Examination[J]. arXiv preprint arXiv:2406.10261, 2024.
🚀以上学术论文翻译由ChatGPT辅助。
食物是人类生活的基础,不仅是营养来源,也是文化认同和社交互动的基石。随着全球饮食需求和偏好的日益复杂,食品智能(Food Intelligence) 变得尤为重要,以支持食品感知与推理,从菜谱生成、膳食推荐到饮食-疾病关联发现和理解等多个任务。
为此,借助大语言模型(Large Language Models, LLMs) 在多个领域和任务中的强大能力,我们引入面向食品的 LLM——FoodSky,用于通过感知与推理理解食品数据。考虑到中餐的复杂性和代表性,我们首先从多个权威来源构建了综合性中文食品语料库 FoodEarth,以供 FoodSky 深度理解食品相关数据。
随后,我们提出了基于主题的选择性状态空间模型(Topic-based Selective State Space Model, TS3M)和层次化主题检索增强生成机制(Hierarchical Topic Retrieval Augmented Generation, HTRAG),分别用于提升 FoodSky 在细粒度食品语义捕捉和上下文感知食品文本生成方面的能力。
大量评估结果表明,FoodSky 在厨师考试和营养师考试中明显优于通用 LLMs,分别在中国国家厨师考试和国家营养师考试中达到了 67.2% 和 66.4% 的准确率。FoodSky 不仅有助于提升烹饪创意、促进健康饮食模式,还为解决食品领域复杂现实问题的专用 LLM 树立了新标准。
FoodSky 的在线演示可在 http://222.92.101.211:8200 访问。
食物是人类生存和文化的基础,与社会价值观和个人习惯密切相关 [1], [2]。丰富多样的饮食不仅提升了我们的美食体验,也促进了复杂的食品数据体系的形成 [3], [4]。随着社会不断发展,食品系统的复杂性也随之增加,导致大量与烹饪实践 [5], [6]、消费模式 [1], [7], [8] 和营养成分 [9], [10] 相关的数据不断积累。
食品计算(Food Computing) 已成为推动食品智能(Food Intelligence)的关键交叉学科,该领域利用广泛的数据支持**从农业到餐桌(Farm-to-Fork)的关键应用 [11]–[13],包括农业建议 [14]–[16]、食品机器人控制 [17]–[19]、烹饪创作 [20]–[22]、膳食跟踪 [23]、慢性病预防 [24]–[26]**等。
在食品计算的广泛研究领域中,菜肴(Cuisine)和营养(Nutrition) 是两个关键主题,因为它们直接影响人们的日常生活和健康状况。近年来,研究人员探索了多种相关任务,例如食材识别 [27]–[29]、菜谱检索 [5], [30], [31] 和营养评估 [32]–[34]。例如,基于Transformer 模型的食材识别已取得了良好的效果,并在多个应用中提升了食品的细粒度感知能力 [35]。
然而,烹饪和膳食的主题极为复杂,它们与饮食文化和慢性疾病等现实因素密切相关,并相互作用。以往的研究通常将这些领域分开处理,忽略了二者结合所能带来的潜在优势,限制了食品计算研究和应用的进一步发展。
1.2 大规模数据驱动的食品智能
随着食品系统的发展,研究已逐步从局部数据分析向大规模全球数据积累过渡,从而为食品计算提供了新的解决方案 [36], [37]。这一趋势促进了**大语言模型(Large Language Models, LLMs)的应用,它们已在多个领域成功解决复杂的现实世界问题 [38],如医学 [39], [40]、教育 [41], [42]、金融 [43], [44]**等。
通过对海量数据的大规模预训练和指令微调(Instruction Fine-tuning),LLMs 具备精准理解和生成自然语言的能力,使其适用于需要知识推理的任务,如医学诊断 [45] 和临床报告生成 [46]。这些成功案例表明,开发一个专门针对食品领域的 LLM(Food-Specific LLM) 具有极大的潜力。
食品领域专用 LLM 可以利用大规模数据集,提供精确的信息感知、理解和推理能力,以应对膳食分析、食品推荐、营养膳食、烹饪建议等关键挑战。这种食品计算与 LLM 的结合,不仅能为食品研究提供数据驱动的洞察,还能增强食品应用的用户体验,推动食品智能的发展。
1.2 食品领域 LLM 研究现状与不足
尽管 LLM 研究日益增长,但针对烹饪和膳食领域的可靠 LLM 仍然较少。近期,一些研究人员认识到了 LLM 在食品领域的潜力,并开始探索其在膳食助手开发中的应用。例如:
- FoodGPT [47] 提出了一个框架,利用知识图谱(Knowledge Graph) 构建知识库,并开发了一个食品领域的 LLM。然而,FoodGPT 并未发布完整训练的模型,无法供其他研究人员进一步开发。
- 另一项研究 [48] 关注食材替代和菜谱推荐,使用面向食品的语言模型(Food-Oriented LLM)。
- FoodLMM [49] 进一步扩展了这些工作,构建了一个多任务膳食助手,能够同时识别食物并估算营养成分,基于现有的多模态基础模型(Multimodal Foundation Models)。
上述研究表明,LLM 在食品领域的应用研究正逐步兴起,并展示了膳食助手进一步发展的潜力。
1.3 现有食品 LLM 存在的主要问题
尽管现有的膳食助手在多媒体膳食分析和推荐方面取得了重要进展,但仍存在多个局限性:
-
泛化能力有限,无法精准理解食品信息
- 现有食品 LLM 基于通用语言模型预训练,但未针对食品领域的细粒度信息进行优化。
- 由于缺乏特定的烹饪和膳食知识,导致成分替换、营养评估等任务的识别和分析结果不准确。
-
未充分覆盖多样化的饮食习惯和烹饪传统
- 目前的 LLM 主要基于西方饮食数据训练,存在文化偏见,在处理亚洲饮食或其他多元文化背景的查询时可能会产生不准确或文化不敏感的回答 [50]。
1.4 FoodSky:首个专门针对食品领域的中文 LLM
为了解决上述问题,我们提出 FoodSky,这是首个针对食品领域优化的中文 LLM。然而,FoodSky 的开发过程中面临多个挑战:
-
缺乏大规模食品语料库
- 与新闻、社交媒体等领域不同,食品数据相对稀缺,分散于烹饪网站、菜谱数据库、食品博客等多个来源。
- 数据质量参差不齐,包含拼写和语法错误、无效数据、重复信息,数据清理难度较大。
-
食品领域知识复杂,覆盖广泛
- 食品领域涉及 食材、菜系、饮食习惯、营养信息 等多个主题,对模型的理解能力提出了较高要求。
-
跨文化的食品知识处理
- 不同地区和文化的饮食习惯、口味偏好、烹饪传统各不相同,需要 LLM 具备跨文化的知识处理能力,以应对全球化的食品计算挑战。
1.5 我们的解决方案
为克服这些挑战,我们采取了以下措施:
-
构建 FoodEarth:首个大规模食品相关中文语料库
- 收集和处理 81.1 万条指令数据,数据来源涵盖电子书、食品网站等权威来源。
- 采用多种数据过滤方法,确保数据的高质量。
-
开发基于主题的食品知识建模方法
- 基于主题的选择性状态空间模型(TS3M):
- 捕捉食品领域的细粒度语义,适应不同主题任务。
- 层次化主题检索增强生成机制(HTRAG):
- 增强模型的泛化能力,优化跨文化食品信息处理能力。
- 基于主题的选择性状态空间模型(TS3M):
-
FoodSky 在厨师和营养师考试中的表现
- FoodSky 在零样本(Zero-Shot)设置下取得 67.2%(国家厨师考试)和 66.4%(国家营养师考试)的准确率。
- 在中国国家厨师考试和国家营养师考试中,相比 InternLM2 [51] 和 ChatGPT-3.5 [52],FoodSky 取得了更好的性能。
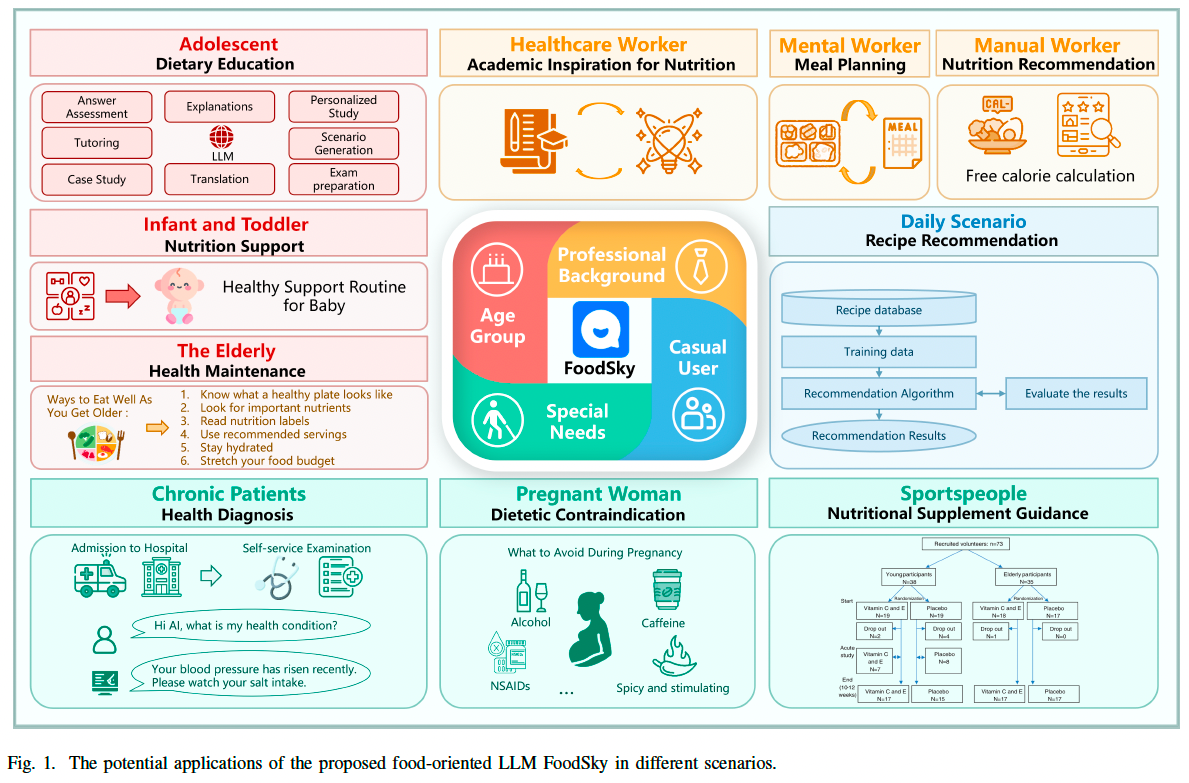
2. 相关工作
本节回顾了与大语言模型(LLMs) 和 食品助手 相关的最新研究进展。
2.1 大语言模型
语言是人类表达和交流的基本能力,它在人类幼年时期形成,并随着时间不断演化 [53]。然而,机器无法自然地理解和使用人类语言,因此,语言模型(Language Models, LMs) 被提出,以使机器能够像人类一样进行阅读和写作 [54]。
语言模型通过建模单词序列的生成概率,预测未来词元(token)的可能性。LMs 的研究经历了四个阶段:
- 统计语言模型(SLMs):主要用于增强特定任务的概率预测。
- 神经语言模型(NLMs):学习**任务无关(task-agnostic)**的表征,减少人工特征工程。
- 预训练语言模型(PLMs):通过大规模预训练,学习上下文感知(context-aware) 表征。
- 大语言模型(LLMs):基于模型规模扩展(Scaling Effect) 实现更强的能力 [55]。
通常,LLMs 指基于 Transformer 架构 的模型,参数量达到数千亿级别,并在大规模文本数据上进行训练 [56]。典型代表包括:
- GPT-3 [57]
- PaLM [58]
- Galactica [59]
- LLaMA [60]
数据中心化人工智能(Data-Centric AI, DCAI) 概念由 Ng 等人 [61] 提出,该概念强调数据比模型架构更重要。这一思想也称为数据中心化思维(Data-Centric Thinking),认为数据的规模和质量 是构建强大 AI 模型的关键因素 [55]。
基于数据中心化理念,LLMs 深刻影响了 AI 研究领域,并引发了多个研究方向的变革 [62], [63]:
- 自然语言处理(NLP):LLMs 作为通用语言任务求解器。
- 信息检索(IR):传统搜索引擎受到 AI 驱动的聊天机器人挑战。
- 计算机视觉(CV):研究人员正在开发 GPT-like 多模态大语言模型(Multimodal LLMs, MLLMs) 以处理多模态问题 [64]–[67]。
- 医疗领域:
- ChatGPT 在医学教育 [68]、放射学决策 [69]、临床遗传学 [70] 方面展现潜力。
- 专用医疗 LLMs(如 Baize [45]、仲景 [40]、华佗 [46])在特定医疗任务上表现更优。
- 教育领域:
- 个性化内容生成 [38], [71]。
- 作业辅助 [72]。
- 自学过程中实时反馈 [42]。
- 金融领域:
- 金融 LLMs(如 FinMA [73]、InvestLM [74]、FinGPT [75]、BloombergGPT [44])提升客户服务、风险评估、算法交易、市场预测等任务 [75]。
不同于这些 LLMs,FoodSky 针对食品领域的独特需求,结合烹饪艺术和营养科学。此外,通用 LLMs 在处理多样化食品主题和文化背景时存在挑战,而 FoodSky 采用 TS3M 结构 以捕捉细粒度主题差异,并通过 HTRAG 机制 确保模型能够生成更精确且具备背景感知能力的回答。这些特性使 FoodSky 成为烹饪专业人士、营养师和消费者的强大工具,并为食品领域 AI 应用树立新标准。
2.2 食品计算
食品计算(Food Computing) 是一个交叉学科,利用计算方法解决食品领域的问题,涉及医学、生物学、烹饪学、农学等多个领域,在学术研究和工业应用中发挥重要作用 [11]。
2.2.1 学术研究
食品计算带来了多个挑战性研究问题,如:
- 细粒度食品识别(Fine-Grained Food Recognition),推动机器学习领域的研究 [37], [76]。
2.2.2 工业应用
食品计算支持多个关键应用:
- 智能农业(Smart Agriculture) [4], [77]。
- 自动化食品加工(Automated Food Processing) [78], [79]。
- 食品推荐系统(Food Recommendation) [80], [81]。
2.2.3 膳食助手:食品计算的重要应用
膳食助手(Dietary Assistant) 是食品计算的一个重要应用,能够帮助消费者做出更智能、更健康的膳食选择 [49], [82],其智能方法可用于:
- 日常烹饪
- 营养分析
- 饮食健康管理
近年来,膳食助手的研究进展主要集中在:
- 食品推荐(Food Recommendation)
- 菜谱检索(Recipe Retrieval)
食品推荐
食品推荐对饮食分析和健康管理至关重要 [83]–[86]:
- Chu 等人 [87] 结合餐厅博客中的图像分析构建混合推荐系统。
- Asani 等人 [88] 通过用户评论提取食品名称,分析饮食情感。
- Ling 等人 [89] 研究成功减肥用户的行为数据,进行个性化推荐。
- Ribeiro 等人 [90] 针对老年人,结合营养、口味偏好、预算 提供个性化推荐。
菜谱检索
菜谱检索(Recipe Retrieval) 旨在提供烹饪建议,已成为食品计算中的重要研究方向 [91]–[94]:
- Zhu 等人 [30] 和 Guerrero 等人 [95] 采用 GAN 生成食品图像,提升检索性能。
- Salvador 等人 [31] 使用分类器 + Transformer 解码器,基于输入图像生成菜谱内容,其泛化能力优于传统方法。
2.2.4 大语言模型在食品计算中的应用
由于 LLMs 在知识推理任务中的成功,研究人员开始探索其在膳食助手中的应用:
- Qarajeh 等人 [96] 研究不同 LLMs 在检测食品中的钾(Potassium)和磷(Phosphorus)含量 方面的有效性,并用于规划更健康的饮食,以防止 高钾血症(Hyperkalemia)和高磷血症(Hyperphosphatemia)。
- Yin 等人 [49] 提出 FoodLMM,基于 LLaVA [97] 构建一个多任务膳食助手,支持:
- 食品识别
- 食材识别
- 食品分割
- 菜谱生成
- 营养估算
- 多轮对话
- Nag 等人 [98] 提出个性化健康导航框架,基于用户健康状态进行评估,并引导用户实现健康目标。
2.2.5 构建食品计算的首个大规模中文数据集
目前,食品菜谱建议、食品科学普及、膳食推荐、营养评估 仍缺乏综合性数据集。因此,我们构建了首个大规模食品领域中文指令数据集——FoodEarth:
- 与医学 [39], [40] 和教育 [41], [43] 领域的研究不同,我们采用多阶段数据集构建流程,专门针对食品数据的来源多样性和原始数据的复杂性。
基于此,FoodSky 作为食品领域的基础 LLM,可以直接为用户提供烹饪洞察和膳食指导,同时促进膳食助手和食品计算的研究。
3. 数据集
本节详细介绍了食品领域的大规模中文指令数据集的构建过程,如图 2 所示。该数据集汇总了来自多种权威中文来源的数据,包括营养数据库、学术期刊和专家认证的网站。为了保证数据质量,我们首先按照数据来源的权威等级对原始数据进行排序,然后通过数据标注流程提取逻辑性强的指令数据。在数据标注过程中,我们采用半自动数据过滤和半自动数据标注。此外,为了减少数据集的重复率并提高数据的专业性,我们通过基于相似度的筛选机制,最终在专家指导下完成了数据集的构建。最终建立的数据集 FoodEarth 包含 811,491 组问答对,为食品和营养领域的大语言模型(LLMs)微调提供了坚实的数据基础。
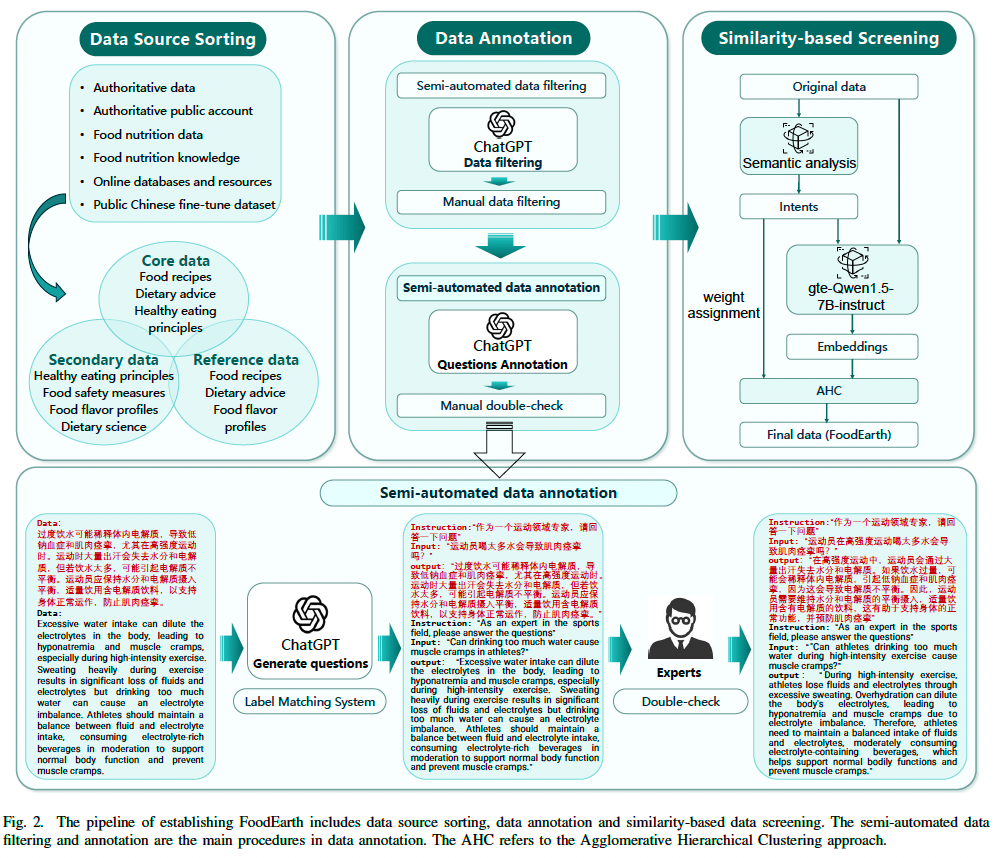
3.1 数据来源整理
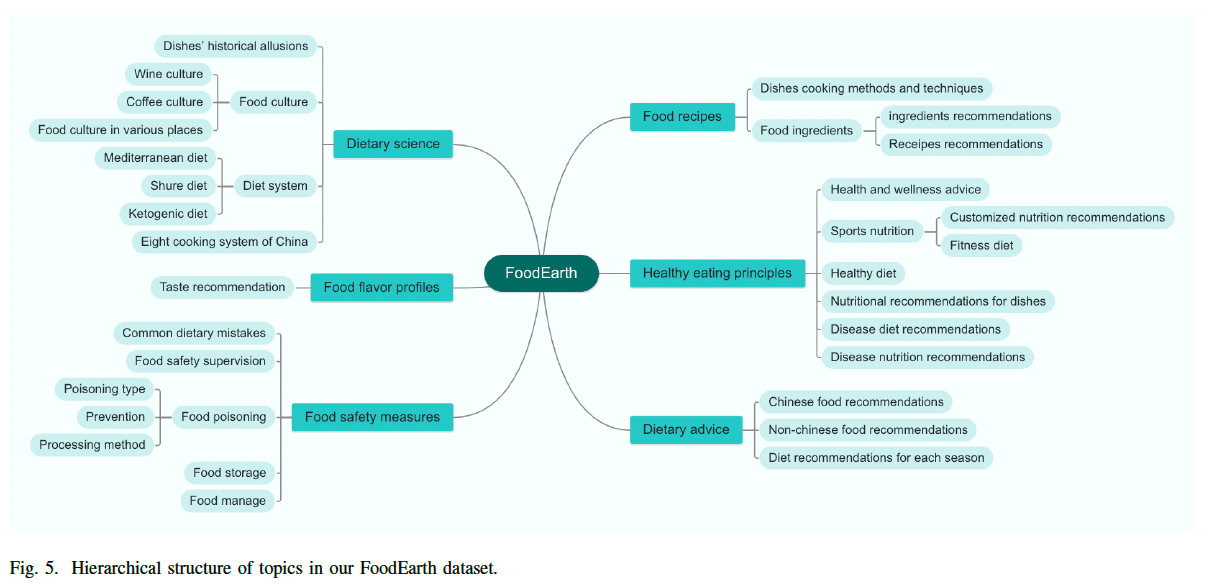
我们的研究目标是在烹饪和膳食领域提供专业的咨询服务,为此,我们希望构建一个涵盖六大食品专业领域的综合知识库:
- 膳食科学(Dietary Science)
- 膳食建议(Dietary Advice)
- 食品风味分析(Food Flavour Profiles)
- 食品安全措施(Food Safety Measures)
- 食品配方与菜谱(Food Recipes)
- 健康饮食原则(Healthy Eating Principles)
食品领域的文本数据因其来源多样、内容复杂,与医学、金融等领域的数据有很大不同:
- 在医学和金融领域,数据通常具有明确的因果关系,如疾病治疗映射和经济调控咨询。
- 而食品相关数据则可信度不均,并常常存在相互矛盾的观点,其复杂性主要源于:
- 个人口味偏好
- 食品测量标准的差异
- 地域性食品多样性
- 不同的烹饪方式
为了解决这些挑战,我们的数据集基于广泛的权威来源构建,确保其可靠性和全面性,并提供对食品计算领域的深入理解。这种多样性至关重要,因为它能够涵盖各种烹饪技巧和个性化营养需求,使其不同于其他领域的数据集。
目前,主流食品数据广泛存在于:
- 专业书籍
- 权威营养论文
- 权威网站
- 微信公众号
- 其他在线数据源
如图 3 所示,我们将数据来源划分为:
- 知识图谱数据源
- 权威数据源
- 在线数据库与资源
- 公共中文指令数据集
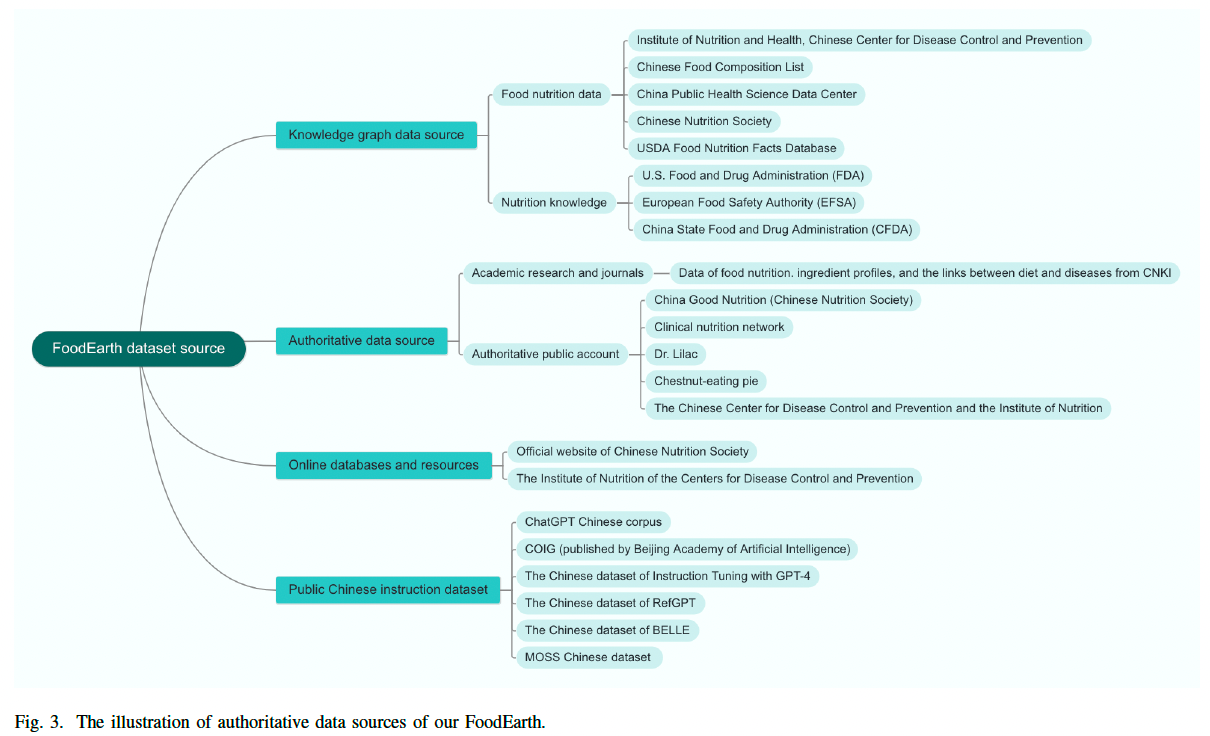
然后,我们根据数据的权威性和时效性重新组织数据。在食品领域,我们累计了数百万个食品营养和菜谱知识图谱数据节点,这些数据主要来自上述权威网站内容,作为本研究的核心数据内容。此外,我们还使用 CNKI(中国知网)专业论文和权威网站 作为二级数据源,涵盖:
- 膳食建议
- 健康饮食原则
- 食品安全措施
- 食品风味分析
- 膳食科学
此外,我们还整合了 ChatGPT 生成的数据 和 公共中文数据集 作为参考数据,以扩展数据的覆盖范围。最终,通过多轮手工标注、专业筛选、ChatGPT 数据处理等清洗方法,我们收集了 超过 25 亿 tokens 的纯文本数据,并完成了包含 811,491 组问答对的数据集。
3.2 数据标注
为了构建高质量数据集,我们采用半自动策略,结合自动化处理和人工处理,确保 FoodEarth 数据集的质量和实用性。具体而言,我们的处理过程可分为两个阶段:
- 半自动数据过滤
- 半自动数据标注
1) 半自动数据过滤
由于食品文本数据集种类繁多、来源广泛且数据质量参差不齐,我们采用了三阶段过滤机制:
-
第一阶段:人工初筛
- 我们的团队基于预设的质量标准和相关性指标进行人工过滤。例如,我们首先剔除无关的噪声数据(如无意义的词汇、表情符号等)。
- 该阶段由 10 名具有数据处理经验的团队成员 共同完成,并利用数据挖掘系统同时进行清理工作。
- 该步骤耗时 近 1 个月,最终将初步清洗后的数据存储为字典格式,以便后续处理。
-
第二阶段:ChatGPT 辅助数据过滤
- 在人工过滤的基础上,我们进一步利用 ChatGPT API 进行智能数据筛选。如图 4 所示:
- 我们设定了一个提示机制,要求 ChatGPT 识别并剔除无关数据:
- 对于不属于研究主题的文本,ChatGPT 返回 0(负样本)
- 对于相关文本,ChatGPT 返回 1(正样本)
- 然后,我们使用过滤系统判定返回值:
- 过滤掉负样本数据
- 仅保留正样本数据
- 这样,ChatGPT 处理的二级过滤数据能够揭示人工筛选可能忽略的细粒度相关性模式。
- 我们设定了一个提示机制,要求 ChatGPT 识别并剔除无关数据:
- 在人工过滤的基础上,我们进一步利用 ChatGPT API 进行智能数据筛选。如图 4 所示:

- 第三阶段:专家审核
- 经过 ChatGPT 处理后,我们将数据集提交给3 名食品安全和营养领域的专家进行双重核查:
- 验证数据的相关性
- 评估数据的真实性和可信度
- 专家通过与最新的文献和行业报告比对,确保数据的准确性和有用性。
- 该步骤至关重要,因为数据质量最终会影响依赖 LLM 提供信息的用户的健康和身体状况。
- 经过 ChatGPT 处理后,我们将数据集提交给3 名食品安全和营养领域的专家进行双重核查:
2) 半自动数据标注
为了进一步优化 LLM,我们特别构建了基于文本的高质量问答(Q&A)训练数据集,专门面向食品领域。标注流程包括:
- 自动生成
- 人工审核
自动生成
- 我们使用 ChatGPT API 自动生成食品相关问答对。
- 采用**提示工程(Prompt Engineering)**技术:
- 设计引导性提示词,使 ChatGPT 生成多样化的高质量问题,且问题内容能准确反映文本中的信息。
- 通过迭代优化提示词,确保生成的问题覆盖广泛的信息需求:
- 从基本定义
- 到复杂概念讨论
- 这些提示词的设计直接决定了模型能否生成高质量、相关性强的问题。
人工审核
- 标注团队由食品科学专家组成,进行详细审查:
- 验证问题的相关性
- 核对答案的准确性
- 审查过程中,所有不准确或含糊的 Q&A 对均直接修正或替换,以符合高标准要求。
为了进一步提升数据集质量,我们还对标注团队的工作流程进行严格记录和审查:
- 识别并减少潜在偏差或错误。
这一严格的审查流程,对构建高质量的食品领域 Q&A 训练数据集至关重要。如图 5 所示,最终构建的 FoodEarth 数据集覆盖了广泛的食品相关主题,并经过严格的质量保障。
3.3 基于相似度的筛选
在构建 FoodEarth 这一包含近百万组指令数据的大规模食品数据集后,我们发现数据集中存在大量语义相似的问答对。这些重复数据使得模型在训练过程中多次学习相似数据,导致泛化性能不佳。因此,为了高效处理并去重这一大规模数据集,我们考虑使用现有的文本表示模型对问答文本进行编码,并基于相似度进行去重。
我们首先随机抽取了一个包含 506 条数据的小型测试集(mini-test set),用于评估并选择最适合本次相似度计算任务的文本编码模型。我们在该小型测试集上测试了多种文本表示模型,选出效果最优的模型用于全数据集的编码。随后,我们使用选定的编码模型对整个数据集进行转换,将每条数据转换为编码向量,并通过计算不同数据项之间的特征向量相似度,结合阈值设定与聚类方法,识别并删除相似度超过 0.9 的数据项。最终,该方法有效减少了数据冗余,确保了所提出模型的泛化能力。
1) 小型测试集(Mini-Test Set)
为了确定最适合我们数据集的相似度筛选方法,我们首先构建了一个小型测试集,用于评估不同文本嵌入方法的性能。该小型测试集包含 506 组样本,其中每条样本包含两句话,并标注了0/1 标签,表示这两条文本是否语义相似。
2) 文本嵌入方法(Embedding Methods)
为了确定适用于本数据集的文本相似度计算方法,并更好地完成相似性筛选任务,我们选择了当前性能最优的文本嵌入模型,并在小型测试集上进行了实验。这些模型在C-MTEB 评测榜单中排名靠前,包括:
- gte-base-zh [99]: GTE 系列中的中文模型,基于 Dual Encoder 结构,使用 BERT-base 作为初始化,拥有 110M 参数。
- gte-large-zh [99]: GTE 系列中的大型中文模型,基于 Dual Encoder 结构,使用 BERT-large 作为初始化,拥有 330M 参数。
- gte-Qwen1.5-7B-instruct [99]: 基于 Qwen1.5-7B 语言模型进行微调,增强了其自然语言处理能力。
- bge-large-zh-v1.5 [100]: 北京智源人工智能研究院(BAAI)开源的大规模中文向量模型,支持中英文嵌入,参数规模 326M,输入序列长度 512,输出维度 1024。
- acge text embedding [101]: 基于 Matryoshka Representation Learning(MRL)框架,提高长文档信息提取精度,适用于不同场景的通用分类任务。
- Baichuan-text-embedding [102]: 百川智能自研嵌入模型,基于 1.5T tokens 的高质量中文数据 进行预训练,优化了对比学习中的 batch size 依赖问题。
- stella-mrl-large-zh-v3.5 [103]: 采用 MRL 训练方法,支持可变向量维度,基于 stella-large-zh-v3-1792d。
- puff-base-v1 [104]: 专门为检索和语义匹配任务设计的模型,支持中英文,强调泛化能力和私有数据集的表现。
3) 不同嵌入方法的比较
为了比较各个模型在相似度计算任务上的表现,我们在小型测试集上进行了实验,并使用准确率(Accuracy)和 F1 分数(F1-score) 作为评估指标:
A
c
c
u
r
a
c
y
=
∣
T
P
∣
+
∣
T
N
∣
∣
T
P
∣
+
∣
T
N
∣
+
∣
F
P
∣
+
∣
F
N
∣
Accuracy = \frac{|TP| + |TN|}{|TP| + |TN| + |FP| + |FN|}
Accuracy=∣TP∣+∣TN∣+∣FP∣+∣FN∣∣TP∣+∣TN∣
F
1
−
s
c
o
r
e
=
2
×
P
r
e
c
i
s
i
o
n
×
R
e
c
a
l
l
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
F1-score = 2 \times \frac{Precision \times Recall}{Precision + Recall}
F1−score=2×Precision+RecallPrecision×Recall
实验结果见表 2,所有模型在相似度计算任务上均表现优秀,准确率均超过 98%,仅少量数据被误判。这表明现有的文本嵌入模型可以很好地理解食品领域的语义信息。
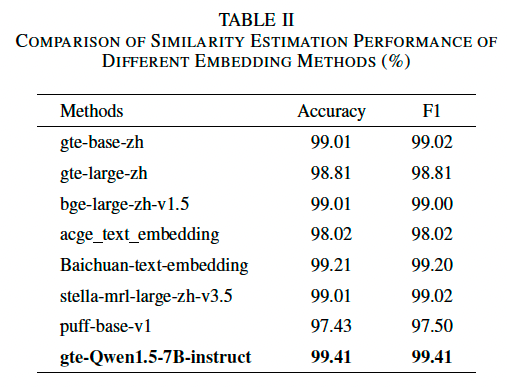
实验结果显示:
- gte-Qwen1.5-7B-instruct 在小型测试集上表现最佳,准确率 99.41%,F1 分数 99.41%。
- 该模型在捕捉食品语义相似度和区分不同食品语义信息方面表现最优。
- 因此,我们选择该模型作为相似数据筛选的最终方法。
4) 数据筛选(Data Screening)
基于评估结果,我们使用 gte-Qwen1.5-7B-instruct 嵌入方法 进行数据过滤和进一步聚类处理。
(1) 阈值去重
我们首先尝试使用固定阈值方法进行数据筛选:
- 使用 gte-Qwen1.5-7B-instruct 模型获取数据集中所有问答对的嵌入表示。
- 计算所有数据对之间的余弦相似度:
- 设定阈值 0.9(基于小型测试集实验)。
- 如果余弦相似度超过 0.9,则认为两条数据为相似数据,并删除较短的数据。
但我们发现,这种方法对于某些文本内容相似但实际意图不同的数据效果不佳。因此,我们采用了基于意图聚类的方法进行数据筛选。
(2) 基于意图聚类的方法
我们进一步使用聚类方法来增强数据筛选效果,具体步骤如下:
-
语义分析与意图分类
- 使用高级语言模型对问题文本进行语义分析,识别核心意图,并将其分类到相应的意图类别中。
- 这些意图类别不仅描述了问题的主题,还反映了用户的潜在需求和目标。
-
意图建模
- 提取出的意图被用于量化数据集中各类意图的频率和权重,从而指导后续的聚类过程。
- 统计分析和概率分布模型保证了对意图的全面理解。
-
文本嵌入
- 经过处理的问答数据及其对应的意图类别,输入到 gte-Qwen1.5-7B-instruct 文本嵌入模型中。
- 该模型将文本转换为高维向量,保留原始语义信息并反映文本之间的语义相似度。
-
聚类方法:凝聚层次聚类(AHC)
- 我们采用**凝聚层次聚类(Agglomerative Hierarchical Clustering, AHC)**方法对数据进行分类:
- 这是一种自底向上的聚类方法,通过迭代合并最相似的数据点形成层次结构。
- 我们在聚类算法中结合意图分布信息,确保结果不仅基于语义相似度,还考虑了不同意图类别的重要性。
- 通过权重调整,使得高频意图类别的数据点在聚类中更具影响力。
- 我们采用**凝聚层次聚类(Agglomerative Hierarchical Clustering, AHC)**方法对数据进行分类:
-
代表性数据点筛选
- 我们计算每个数据点与其所属类别中心点的距离,选取距离最小的数据点作为代表性数据,确保数据集的多样性和代表性。
4. 方法(METHOD)
在 FoodSky 中,我们提出了两个关键算法:
- 基于主题的选择性状态空间模型(Topic-based Selective State Space Model, TS3M),用于通过整合主题相关信息提升模型的准确性。
- 层次化主题检索增强生成(Hierarchical Topic Retrieval Augmented Generation, HTRAG),用于生成信息更加丰富的回复。
在介绍所提出的算法之前,我们首先介绍 主干模型(Backbone Model) 和 指令微调(Instruction Fine-tuning),以提供必要的技术背景。
4.1 主干模型(Backbone Model)
主干模型是 TS3M 和 HTRAG 这两个扩展方法的基础,它增强了模型对食品相关指令和问题的理解能力,并能够生成相关的响应。
具体而言,我们的主干模型 ϕω 是一个大语言模型(LLM)(如 LLaMA-2),该模型在大规模中文语料上进行预训练,并在通用领域的中文指令数据集上进行了微调。我们将该主干模型命名为 Chinese LLaMA-2(CLLaMA2)。
为了使模型适应食品领域的特定挑战和特性,我们对其进行了食品领域的专门微调。这一阶段的训练基于我们提出的 FoodEarth 数据集,该数据集包含与食品相关的中文指令、问题和答案。数据涵盖了食谱、食材、营养、菜系和食品安全等多个方面。通过专注于食品领域的数据,模型能够学习更准确、更具信息量的食品相关查询的回答方式。
4.2 指令微调(Instruction Fine-tuning)
指令微调 是使主干语言模型能够有效遵循指令并在食品领域生成恰当响应的关键步骤。我们采用了两阶段指令微调策略:
- 通用指令微调(General Instruction Tuning)
- 食品领域指令微调(Food-specific Instruction Tuning)
(1) 通用指令微调
在第一阶段,我们在大规模通用领域数据集上进行指令微调,得到一个指令微调后的基础模型 CLLaMA2-Alpaca。这一模型具备基本的指令理解和执行能力,能够根据上下文理解并生成符合要求的响应。
(2) 食品领域指令微调
在第二阶段,我们进一步使用 FoodEarth 数据集 对模型进行食品领域指令微调。该数据集涵盖了饮食科学、烹饪技术、健康饮食原则和食品安全指南等多个主题。通过关注食品领域特定的指令,模型能够学习到与食品领域专用术语、挑战及约束相关的知识,如食材特性、烹饪方法和饮食限制,从而生成更具针对性的答案。
(3) 确保食品领域指令微调有效性的策略
为了确保食品领域微调的有效性,我们采取了以下几种策略:
-
数据质量控制:
- 我们精心收集、处理和审核 FoodEarth 数据集,确保其准确性、相关性和多样性。
- 数据主要来源于烹饪专家、食品科学文献和知名烹饪网站。
- 采用人工标注+自动化方法+专家审核的方式进行数据清洗,去除无关或低质量数据。
-
训练技术:
- 在通用指令微调阶段,我们采用掩码语言建模(MLM) 和 下一句预测(NSP) 技术:
- MLM(Masked Language Modeling):随机掩盖输入文本的一部分,训练模型根据上下文预测被掩盖的单词,以学习语义和句法模式。
- NSP(Next Sentence Prediction):训练模型预测给定的响应是否合乎逻辑地承接前一句指令,提升其生成连贯且相关的回答的能力。
- 在通用指令微调阶段,我们采用掩码语言建模(MLM) 和 下一句预测(NSP) 技术:
-
迭代微调(Iterative Fine-tuning):
- 逐步增加食品相关指令的复杂性和专业性,使模型能够逐渐适应食品领域的细粒度特性和挑战,最终形成更具专业能力的模型。
4.3 TS3M 分类器(TS3M Classifier)
图 6 还展示了 基于主题的选择性状态空间模型(TS3M)。该模型的主要作用是:
- 捕捉输入指令中的主题与内容之间的语义关系。
- 利用特定食品主题的先验知识增强模型的输出。
- 使模型能够生成更加连贯和信息丰富的回答。
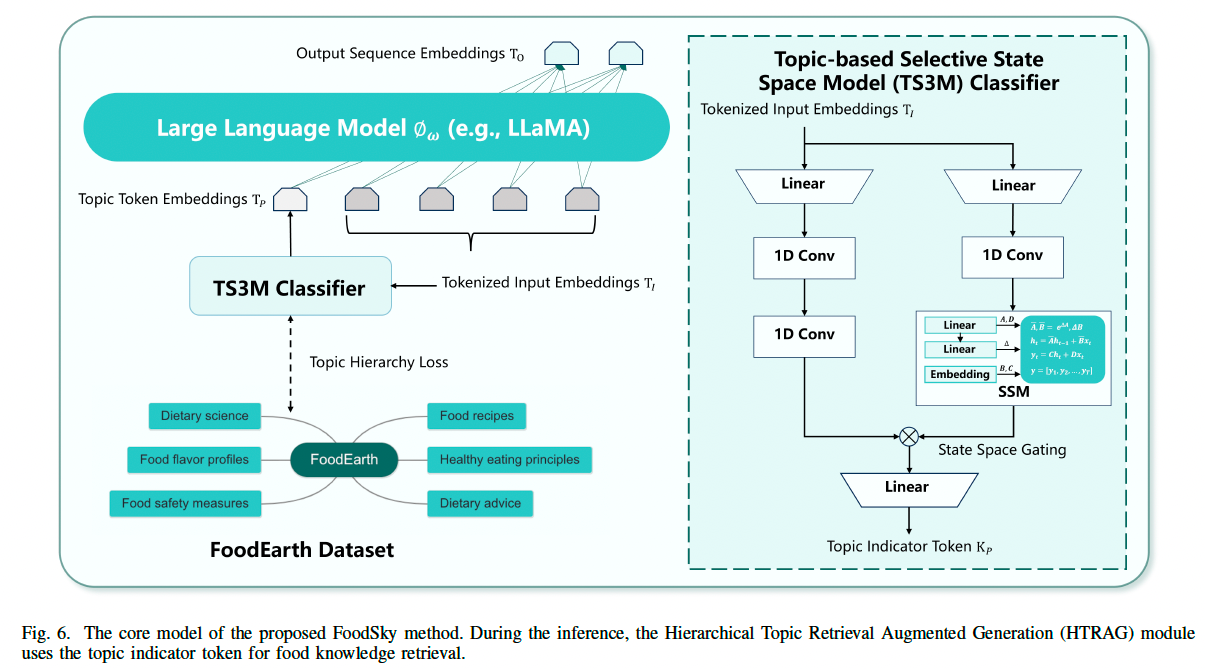
(1) 结构
TS3M 以 tokenized 的指令嵌入 T I ∈ R n × d m T_I \in \mathbb{R}^{n \times d_m} TI∈Rn×dm 作为输入,其中:
- n n n 代表token 的数量,
- d m d_m dm 代表token 的嵌入维度。
TS3M 采用两分支结构:
- 内容表示分支(Content Representation Branch)
- 结合线性变换和卷积层,通过多个层级逐步优化语义嵌入。
- 主题状态表示分支(Topic State Representation Branch)
- 通过选择性地整合内部状态,影响模型的最终输出。
(2) 内容表示分支
初始层首先对输入的 token 嵌入进行线性变换,以适应后续卷积处理:
X
L
1
=
T
I
W
1
+
b
1
X_L^1 = T_I W_1 + b_1
XL1=TIW1+b1
其中:
- W 1 ∈ R d m × d l W_1 \in \mathbb{R}^{d_m \times d_l} W1∈Rdm×dl 和 b 1 ∈ R d l b_1 \in \mathbb{R}^{d_l} b1∈Rdl 分别表示线性变换的权重和偏置,
- d l d_l dl 是变换后的维度。
变换后的输入
X
L
1
∈
R
n
×
d
l
X_L^1 \in \mathbb{R}^{n \times d_l}
XL1∈Rn×dl 随后进入一维卷积层(1D Conv),建模 token 之间的关系并下采样特征:
X
C
2
=
σ
(
Conv
(
X
C
1
)
)
=
σ
(
Conv
(
σ
(
Conv
(
X
L
1
)
)
)
)
X_C^2 = \sigma(\text{Conv}(X_C^1)) = \sigma(\text{Conv}(\sigma(\text{Conv}(X_L^1))))
XC2=σ(Conv(XC1))=σ(Conv(σ(Conv(XL1))))
其中:
- σ ( ⋅ ) \sigma(\cdot) σ(⋅) 表示LeakyReLU 非线性激活函数,
- Conv ( ⋅ ) \text{Conv}(\cdot) Conv(⋅) 表示一维卷积操作。
(3) 主题状态表示分支
TS3M 采用 状态空间模型(State Space Model, SSM) 作为核心技术。状态的更新方式如下:
h
(
t
)
=
A
^
h
(
t
−
1
)
+
B
^
x
(
t
)
h(t) = \hat{A} h(t-1) + \hat{B} x(t)
h(t)=A^h(t−1)+B^x(t)
其中:
- h ( t ) h(t) h(t) 为t 时刻的潜在状态,
- x ( t ) x(t) x(t) 为t 时刻的投影指令 token,
-
A
^
\hat{A}
A^ 和
B
^
\hat{B}
B^ 控制状态变化,具体更新方式如下:
A ^ = e Δ t A , B ^ = ( Δ t A ) − 1 ( e Δ t A − I ) ⋅ Δ t B \hat{A} = e^{\Delta t A}, \quad \hat{B} = (\Delta t A)^{-1} (e^{\Delta t A} - I) \cdot \Delta t B A^=eΔtA,B^=(ΔtA)−1(eΔtA−I)⋅ΔtB
(4) 主题层次损失(Topic Hierarchy Loss)
为了保证模型能够生成符合主题层次结构的输出,我们定义了主题层次损失
L
T
H
L_{TH}
LTH:
L
T
H
=
e
−
d
graph
(
T
,
T
^
)
⋅
∑
i
=
1
P
k
i
,
T
log
(
k
^
i
,
T
^
)
L_{TH} = e^{-d_{\text{graph}}(T, \hat{T})} \cdot \sum_{i=1}^{P} k_{i,T} \log(\hat{k}_{i, \hat{T}})
LTH=e−dgraph(T,T^)⋅i=1∑Pki,Tlog(k^i,T^)
其中:
- d graph ( T , T ^ ) d_{\text{graph}}(T, \hat{T}) dgraph(T,T^) 代表真实主题 T T T 与预测主题 T ^ \hat{T} T^ 之间的最短路径距离,
- k i , T k_{i,T} ki,T 和 k ^ i , T ^ \hat{k}_{i, \hat{T}} k^i,T^ 分别是真实主题和预测主题的概率分布。
4.4 层次化主题检索增强生成(HTRAG)
HTRAG 旨在增强指令微调模型的生成能力,通过在推理过程中整合检索到的信息,为模型提供相关的上下文知识,以提升生成答案的准确性和信息丰富度。
HTRAG 采用多步处理流程,分层检索和整合主题相关信息,这些信息来源于外部知识库,包括:
- 食品百科、
- 食谱数据库、
- 营养信息、
- 烹饪技术 等。
为了提高检索效率,知识库预处理并索引到 FAISS [106] 中,基于 gte-Qwen1.5-7B-instruct 作为嵌入模型,用于语义检索。
(1) HTRAG 工作流程
HTRAG 主要通过以下步骤实现信息检索与融合:
① 主题标识生成
首先,将输入指令 token
X
q
X_q
Xq 通过 基于主题的选择性状态空间模型(TS3M) 处理,以获得主题指示 token
K
K
K。
K
=
TS3M
(
X
q
)
K = \text{TS3M}(X_q)
K=TS3M(Xq)
② 主题相关信息检索
利用 TS3M 生成的主题指示 token K K K 在外部知识库中检索相关信息,检索采用层次化策略:
- 第一层检索:基于输入指令的整体语义进行匹配;
- 第二层检索:结合 TS3M 识别出的具体主题信息进行精细匹配。
在第一步检索中,我们计算
K
K
K 与知识库
D
D
D 中索引内容的余弦相似度:
sim
(
K
,
D
i
)
=
K
⋅
D
i
∥
K
∥
∥
D
i
∥
\text{sim}(K, D_i) = \frac{K \cdot D_i}{\|K\| \|D_i\|}
sim(K,Di)=∥K∥∥Di∥K⋅Di
- 计算相似度后,筛选出最相关的文档或段落,作为初步检索结果。
在第二步精细检索中:
- 对初步检索的文档进行进一步筛选,确保其与 TS3M 识别的主题紧密相关;
- 根据指令主题的权重,调整不同信息的重要性。
③ 信息整合
- 检索到的信息 与 原始指令表示 进行融合,得到增强表示:
- 包含原始指令上下文
- 补充外部知识库检索到的信息
最终,增强后的表示被传递给大语言模型(LLM)
ϕ
ω
ϕω
ϕω,用于生成最终回答:
T
o
=
ϕ
ω
(
Concat
(
X
q
,
R
)
)
T_o = ϕω(\text{Concat}(X_q, R))
To=ϕω(Concat(Xq,R))
其中:
- R R R 表示从检索文档中整合的信息,
- Concat ( ⋅ ) \text{Concat}(·) Concat(⋅) 表示拼接操作。
(2) HTRAG 的优势
- 能够层次化检索和整合食品相关知识,提供更精准的信息支持;
- 增强模型处理食品领域复杂问题的能力,尤其是个性化和复杂查询;
- 结合 TS3M 进行主题引导检索,提高生成内容的上下文相关性。
通过 HTRAG 的检索增强机制,FoodSky 能够更全面地回答食品相关问题,提高对复杂饮食咨询的理解和响应能力。
5. 实验
5.1 实验设置
1) 实现细节
为了研究模型规模对性能的影响,我们在两个不同规模的基础模型上进行实验:
- CLLaMA2-7B:7B 参数模型
- CLLaMA2-13B:13B 参数模型
LLaMA-7B 具有 70 亿参数,LLaMA-13B 具有 130 亿参数,从而在学习能力和生成能力上提供更强的表现。在进行食品领域微调后,我们分别将模型称为:
- FoodSky-7B(7B 版本)
- FoodSky-13B(13B 版本)
训练配置如下:
- FoodSky-13B 在 8 张 NVIDIA A100(80GB) GPU 服务器上训练;
- FoodSky-7B 在 8 张 NVIDIA V100(32GB) GPU 服务器上训练;
- 采用 LoRA(低秩适配)参数高效微调 [112];
- 采用 Pytorch 框架,使用 transformers2 和 peft3 库;
- 混合精度训练(fp12),结合 ZeRO-3 和 DeepSpeed5 进行梯度累积,提高训练效率;
- 单次回答最大长度:1500 个 token(包括历史记录);
- 采用 dropout 率 0.1,学习率 1 0 − 5 10^{-5} 10−5,使用 Adam 优化器 [113];
- 采用余弦学习率调度;
- 选择最后收敛的检查点作为最终模型。
2) 基线方法
我们将 FoodSky 与代表性最先进 LLM 进行对比:
- ChatGLM2-6B [114]:6B 参数的中英双语 LLM,优化用于中文 QA 和对话任务,训练数据约 1 万亿 token。
- Mistral-7B [108]:7B 参数 LLM,由 Mistral AI 发布,兼顾效率和高性能,适用于多种任务。
- InternLM2-7B [51]:7B 参数开源 LLM,在 2 万亿高质量 token 预训练数据上训练。
- Vicuna-v1.5-7B / Vicuna-v1.5-13B [109]:[115]:7B 和 13B 参数开源聊天模型,基于 LLaMA 2 进行监督指令微调,训练数据来自 ShareGPT,包含 12.5 万 对话数据。
- Baichuan2-7B [102]:7B 参数多语言 LLM,由 Baichuan Intelligence 发布,在 2.6 万亿 token 高质量语料上训练。
- Qwen-7B [111]:7B 参数阿里巴巴开源 LLM,在 3 万亿 token 训练,覆盖多个领域任务。
- ChatGPT-3.5 [52]:OpenAI 开发的 LLM,采用**强化学习人类反馈(RLHF)**进行训练,基于 GPT-3.5 微调。
- CLLaMA2-7B [110]:7B 参数的中文预训练 LLaMA 版本,通过指令微调增强其理解和生成能力。
3) 评估指标
为了全面评估不同 LLM,我们使用以下指标:
-
CDE Benchmark(Chef and Dietetic Examinations)
- 主要度量:准确率(Accuracy),用于评估 LLM 在标准厨师和营养师考试中的表现。
-
自动评测指标(用于自然语言生成任务):
- BLEU-1, BLEU-2, BLEU-3, BLEU-4 [116]:评估n-gram 重叠情况,衡量生成内容与参考答案的匹配度。
- ROUGE-1, ROUGE-2, ROUGE-L [117]:评估unigram、bigram、最长公共子序列(LCS) 的匹配程度。
- GLEU [118]:BLEU 的变体,更符合人工评测标准。
- Distinct-1/2 [119]:计算生成答案中不重复的 unigram/bigram 比例,衡量文本多样性。
-
人工评测指标:
- 使用 GPT-4 作为评审员,评估 FoodQA 数据集的回答质量,包括:
- 流畅度(Fluency)
- 逻辑性(Logic Correctness)
- 专业性(Professionality)
- 信息丰富度(Information Density)
- 使用 GPT-4 作为评审员,评估 FoodQA 数据集的回答质量,包括:
5.2 评测数据集
我们在以下三个数据集上测试基线模型和 FoodSky:
- CDE Benchmark
- Food Long Conversation (FoodLongConv) Benchmark
- Food Question and Answer (FoodQA) Benchmark
(1) CDE Benchmark
-
该基准数据集包含:
- 628 道 中国厨师考试(Chinese Chef Examination) 选择题;
- 111 道 中国营养师考试(Chinese Dietetic Examination) 选择题。
-
目的:测试 LLM 在食品与营养领域的客观问答能力。
-
主要评测指标:准确率(Accuracy),判断 LLM 生成的答案是否正确。
(2) FoodLongConv Benchmark
- 22 道长文本回答题(从中国厨师考试和中国营养师考试抽取)。
- 评测模型对长篇问答的生成能力,使用 BLEU、ROUGE 等指标。
(3) FoodQA Benchmark
-
25 道 食品相关的 短问答+长问答题,涵盖:
- 食材识别
- 营养评估
- 健康饮食建议
- 烹饪技巧
-
采用 GPT-4 评分,评估 流畅度、逻辑性、专业性、信息丰富度。
4)评测标准
- CDE 主要考察 LLM 在标准化考试中的准确率,是最客观的指标;
- FoodLongConv 关注 LLM 对复杂食品问题的长文本生成能力;
- FoodQA 侧重 LLM 在食品问答中的知识深度和表达能力。
通过上述实验,我们全面比较了 FoodSky 与现有最先进 LLM 的性能,并验证了 FoodSky 在食品领域的优势。
5.3 与基线方法的比较
1) CDE 基准测试对比
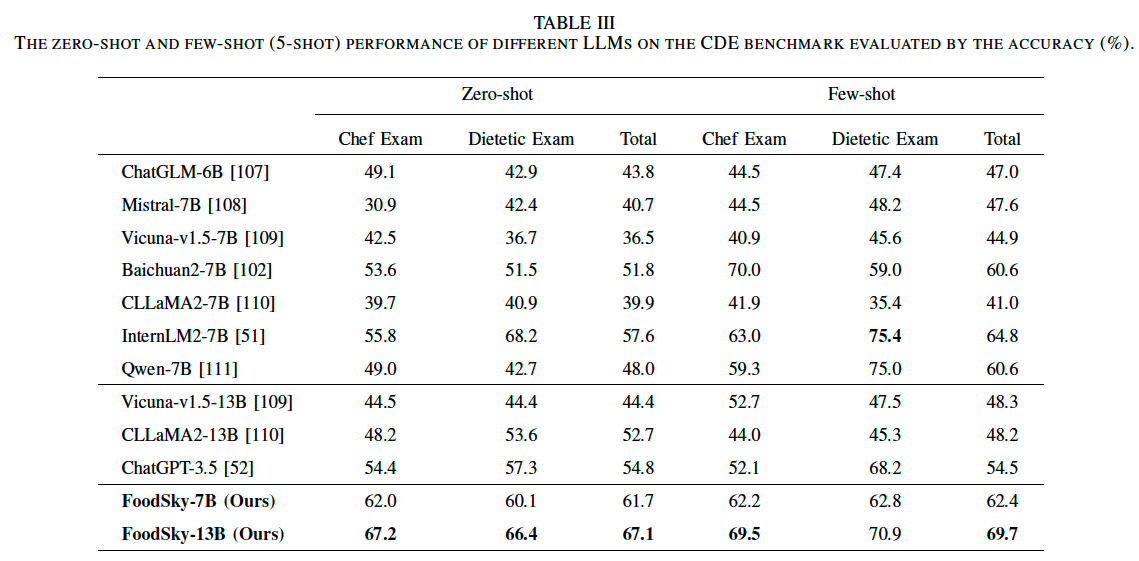
表 III 展示了不同 LLM 在 CDE 基准测试中的 零样本(zero-shot) 和 少样本(5-shot) 设定下的性能表现,其中报告了在厨师考试和营养师考试上的准确率,以及整体平均准确率。
(1) 零样本设定
-
FoodSky-7B 和 FoodSky-13B 在 厨师考试(Chef Exam) 和 营养师考试(Dietetic Exam) 上均取得了最高准确率,超越所有其他基线模型:
- FoodSky-7B:
- 厨师考试准确率:62.0%
- 营养师考试准确率:60.1%
- 总体准确率:60.2%
- FoodSky-13B(更大模型):
- 厨师考试准确率:67.2%
- 营养师考试准确率:66.4%
- 总体准确率:67.1%
- FoodSky-7B:
-
基线模型表现:
- InternLM2-7B 和 ChatGPT-3.5 的表现较优,准确率分别为 57.6% 和 54.8%。
- Baichuan2-7B(51.8%)、CLLaMA2-13B(52.7%)等模型的表现较弱。
(2) 少样本设定(5-shot)
-
所有模型的表现均有所提升,受益于额外的上下文信息:
- FoodSky-13B:
- 厨师考试:69.5%
- 营养师考试:70.9%
- 总体准确率:69.7%(继续保持领先)
- FoodSky-7B:
- 总体准确率:61.8%
- 其他模型表现:
- InternLM2-7B(64.8%)
- ChatGPT-3.5(54.5%)
- Baichuan2-7B(60.6%)
- CLLaMA2-13B(48.2%)
- FoodSky-13B:
-
FoodSky 模型优异表现的关键因素:
- 训练过程中大规模食品与营养数据集的微调,使模型对领域相关概念和原理有更深入的理解和推理能力。
- 能够通过中国厨师考试和营养师考试,成为食品与营养领域的首个可用的专用 LLM。
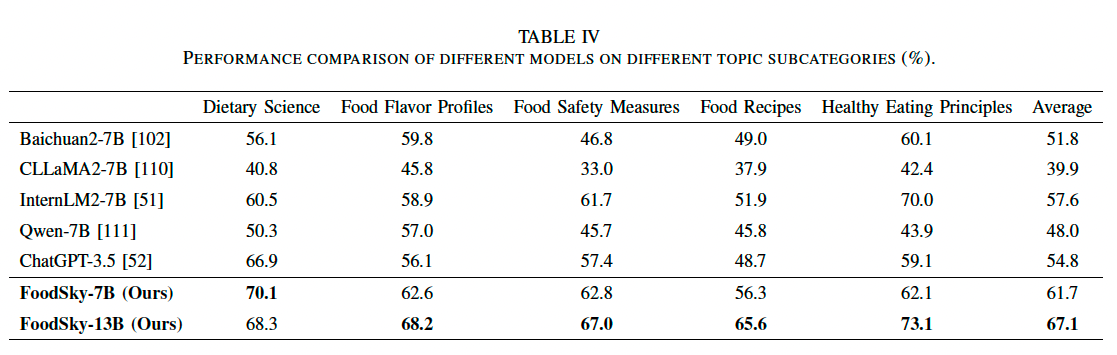
2) 不同主题类别上的对比
我们使用 CDE 数据集(包含厨师和营养师考试的选择题),来评估不同方法在 不同主题类别 上的表现。具体而言,我们将CDE 题目分为五个主要类别:
- 膳食科学(Dietary Science)
- 食物风味特征(Food Flavor Profiles)
- 食品安全措施(Food Safety Measures)
- 食谱与烹饪(Food Recipes)
- 健康饮食原则(Healthy Eating Principles)
(1) FoodSky-13B 在所有类别中均取得最高准确率
- 膳食科学:68.3%
- 食物风味特征:68.2%
- 食品安全措施:67.0%
- 食谱与烹饪:65.6%
- 健康饮食原则:73.1%
- 总体平均准确率:67.1%
(2) FoodSky-7B 亦表现优秀
- 膳食科学:70.1%
- 食物风味特征:62.6%
- 食品安全措施:62.8%
- 食谱与烹饪:56.3%
- 健康饮食原则:62.1%
- 总体平均准确率:61.7%
(3) 其他基线模型的表现
- ChatGPT-3.5:
- 膳食科学:66.9%
- 健康饮食原则:59.1%
- 其他基线模型在不同类别上的表现参差不齐。
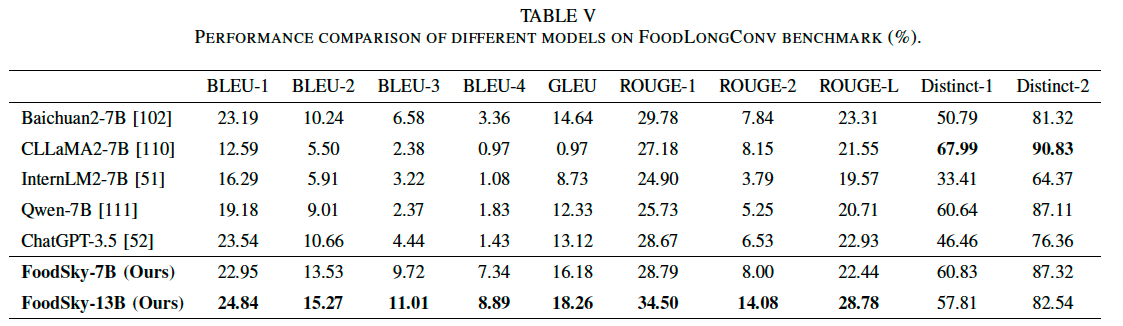
3) 问答任务对比(FoodQA Benchmark)
我们使用 FoodQA 评估不同模型在食品与营养领域的问答任务上的表现,采用 BLEU、GLEU、ROUGE、Distinct 作为度量指标。
(1) FoodSky-13B 在大多数指标上优于所有模型
- BLEU-1:24.84%
- BLEU-2:15.27%
- BLEU-3:11.01%
- BLEU-4:8.89%
- GLEU:18.26%
- ROUGE-1:34.50%
- ROUGE-2:14.08%
- ROUGE-L:28.78%
(2) FoodSky-7B 也表现强劲
- BLEU-4:7.34%
- GLEU:16.18%
(3) 其他基线模型的表现
- CLLaMA2-7B:
- 在 Distinct-1 和 Distinct-2 上得分最高,但准确率低(输出不受控)。
- 由于缺乏食品领域知识,无法回答多个问题,导致生成的回答更加随机。
- Baichuan2-7B:
- ROUGE-1(29.78%),ROUGE-L(23.31%),在上下文信息捕捉方面表现较好。
(4) 结论
- FoodSky-13B 在问答任务上展现出更强的语言丰富性和准确度。
- 相比其他通用模型,FoodSky 的生成内容更具专业性,且在多个指标上均领先。
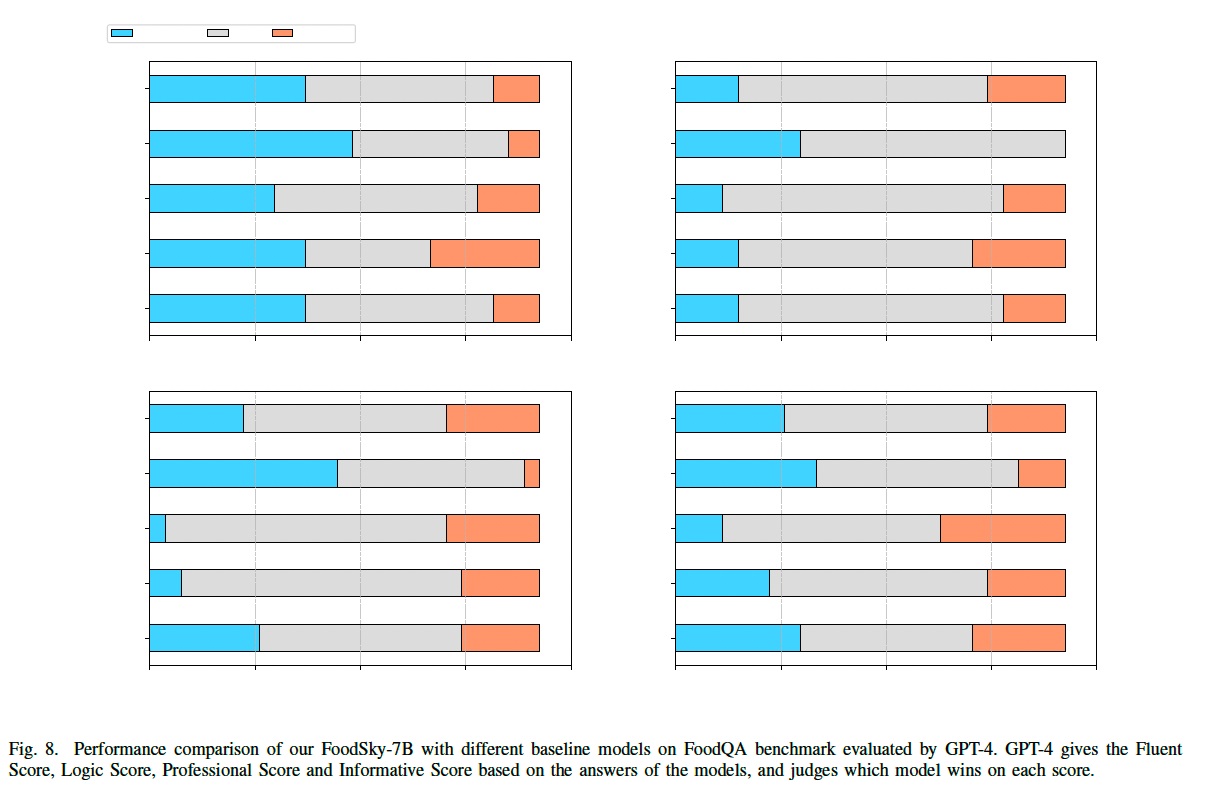
4) GPT-4 评分评测
我们还使用 GPT-4 作为评审员,主观评估不同模型的回答质量,考察 流畅性(fluency)、逻辑性(logic correctness)、专业性(professionality)和信息丰富度(informative)。
(1) FoodSky-7B 在流畅性得分最高
- 流畅性(Fluency):40 分
- 逻辑性、专业性和信息丰富度也表现突出
(2) 其他模型的表现
- InternLM2-7B 和 Qwen-7B:
- 逻辑性、专业性和信息丰富度得分在 20%-35% 之间,表现较强。
- ChatGPT-3.5 和 Baichuan2-7B:
- 逻辑性、专业性和信息丰富度得分在 20%-30% 之间。
- CLLaMA2-7B:
- 四个指标得分均较低,仅为 0%-20%。
(3) 结论
- FoodSky 生成的答案在 GPT-4 评测下表现优越。
- 基线模型在多选题回答上表现较差,但 GPT-4 仍然认为它们的回答是合理的。
- 未来可通过强化学习(RLHF)进一步优化 FoodSky 的问答能力。
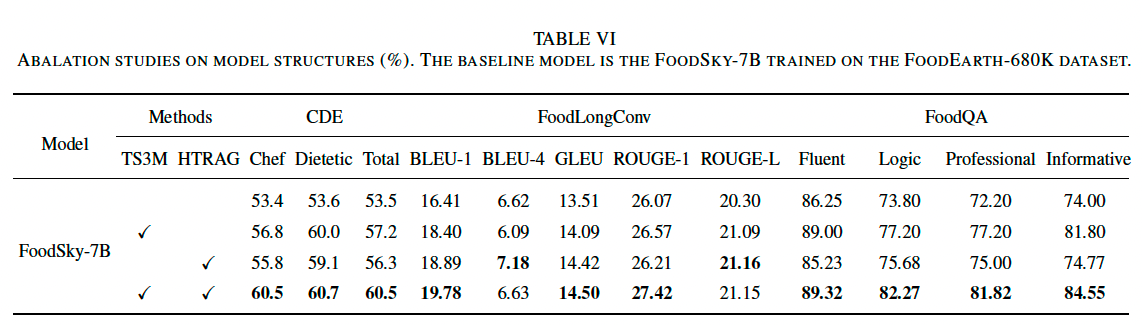
5.4 消融实验
为了研究 FoodSky 不同组件的影响,我们进行了消融实验,通过去除关键组件并在 CDE、FoodLongConv 和 FoodQA 基准测试上评估性能。
为了在数据构建的早期阶段快速验证所提出方法的有效性,我们使用了 FoodEarth-680K(一个包含 68 万条指令数据的高质量子集)来训练 FoodSky。
表 VI 展示了不同模型结构的消融实验结果。
- FoodSky-7B 基准模型(未添加任何额外组件)在 CDE 基准测试中平均准确率为 53.5%。
- 加入 TS3M 后,准确率提升至 57.2%(提升 3.7%),表明其在主题理解上的关键作用。
- 加入 HTRAG 后,准确率提升至 56.3%(提升 2.8%),表明其利用外部知识提供上下文相关答案的能力。
- 同时加入 TS3M 和 HTRAG 后,准确率提升至 60.5%,在 FoodQA 数据集中也表现最佳:
- BLEU-1:19.78%
- BLEU-4:6.63%
- GLEU:14.50%
- ROUGE-L:21.15%
实验结论:
- TS3M 和 HTRAG 组合使用时,FoodSky-7B 的性能显著提升,能够生成更准确、更相关的答案。
- 这表明 TS3M 和 HTRAG 共同作用,能有效提升模型的语义理解能力和响应质量。
5.5 训练数据数量对性能的影响
为了评估训练数据集大小对 FoodSky 运行效果的影响,我们对 FoodSky-7B 和 FoodSky-13B 进行了消融实验,分别使用 FoodEarth-680K 数据集中不同规模的指令数据进行训练。
实验结果如图 9 所示,展示了数据量变化如何影响模型的准确率和语言学指标。
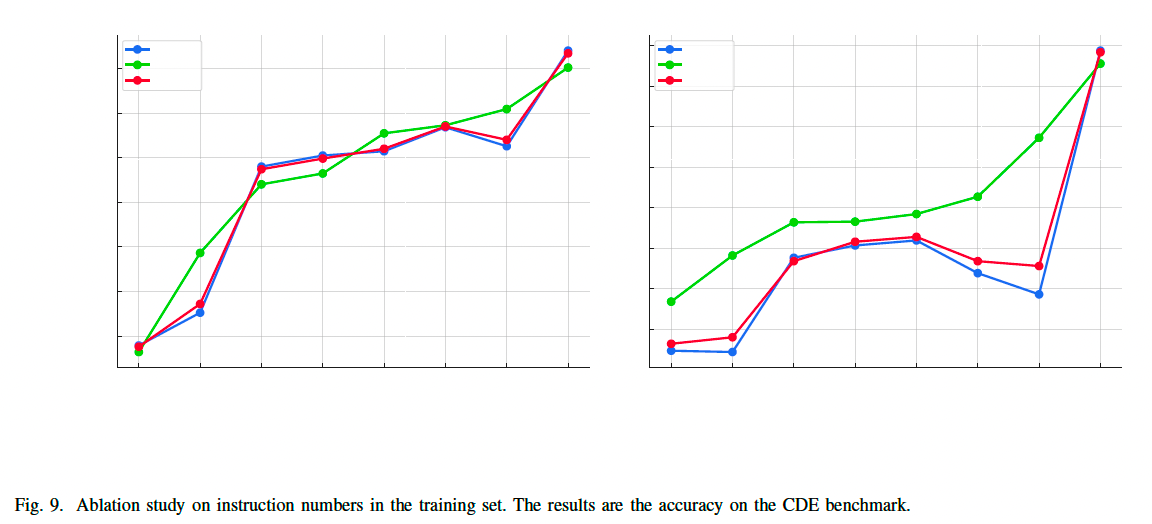
-
FoodSky-7B
- 200K 样本:CDE 基准测试总准确率 28.8%
- 811K 样本:准确率 61.7%
- 整体表现随着数据规模增加稳定提升
-
FoodSky-13B
- 600K 样本:
- 厨师考试准确率:48.67%
- CDE 总体准确率:49.1%
- 811K 样本:
- 厨师考试准确率:67.2%
- CDE 总体准确率:67.1%
- 600K 样本:
数据质量的重要性
- 当数据量增加到 780K 时,FoodSky-7B 和 FoodSky-13B 的准确率反而下降。
- 原因:从 680K 扩展到 800K 时,额外的数据来源于 公共教学数据集,未经过严格的数据质量检查。
- 这表明:
- 数据质量比数据量更重要,低质量或重复数据可能会影响模型性能。
- 最终版本 FoodEarth 经过严格筛选,保留了 811K 高质量样本,提升了模型的准确率。
结论
- 扩大训练数据集规模对 FoodSky-13B 影响更大,其较大的模型容量能够更有效地利用额外数据,超越 FoodSky-7B。
- 最终,FoodSky-13B 在 811K 训练数据下达到最佳性能:
- 厨师考试准确率:67.2%
- 营养师考试准确率:66.4%
- CDE 总体准确率:67.1%
- 这表明随着训练数据的增加,模型能够生成更准确、信息量更丰富的回答。
5.6 质性分析*
图 11 展示了不同 LLM 在食谱推荐任务上的表现,突出了各模型在预测能力上的优势和不足。

- FoodSky 在第一个示例中正确识别出 “如何让鸡胸肉更美味” 的关键信息:
- 这反映出 FoodSky 在理解烹饪艺术基本原理方面具有较强的能力。
- 基线模型 Intern 和 ChatGPT:
- 在捕捉细粒度的烹饪知识上表现不佳。
- Intern 未能理解 “节省时间和精力” 的核心需求,表明其在处理复杂烹饪指令和食材交互方面存在不足。
图 10 进一步展示了青少年膳食教育的质性实验结果:
- FoodSky:
- 最深入地分析了 “垃圾食品对青少年的健康影响”。
- 强调适量消费,并提供可行的健康饮食建议。
- Intern:
- 回答过长,涉及太多细节性健康影响和广泛的饮食建议,容易导致信息冗余。
- ChatGPT:
- 在 “适量食用快餐” 和 “健康饮食习惯” 之间提供了较为平衡的视角。

结论
- FoodSky 能快速识别高热量、高脂肪饮食的健康风险,并提供可执行的健康饮食建议。
- 与其他基线模型相比,FoodSky 能够在短时间内提炼关键信息,使其在食品与营养领域的应用价值更高。
6. 结论
FoodSky 作为强大的食品领域 LLM,开创了未来食品研究和应用的新方向。
为了确保 FoodSky 的成功,我们采取了以下策略:
- 构建大规模、高质量的食品语料库,涵盖各类食品相关指令数据,为模型训练提供坚实基础。
- 提出了 Topic-Based Selective State Space Model (TS3M) 和 Hierarchical Topic Retrieval-Enhanced Generation (HTRAG):
- TS3M 提升了 FoodSky 在食品相关内容上的理解能力。
- HTRAG 通过外部知识增强了 FoodSky 的生成能力。
- 通过广泛的实验,FoodSky 在理解和生成食品相关内容方面表现卓越,超越了现有通用 LLM:
- 在 厨师和营养师考试 中表现最佳,证明其在食品领域的专业性。
未来展望
FoodSky 未来可在多个方向上拓展:
- 强化学习 + 人类反馈(RLHF):
- 结合强化学习,使 FoodSky 持续优化其理解和生成能力。
- 多模态 LLM(MLLM)扩展:
- 例如,通过食材图片生成食谱建议,或基于菜品营养分析预测未来体重变化。
- 引入更多食品行业数据,构建专门针对食品行业的 LLM:
- 赋能食品产业的智能化升级,助力食品设计、食品安全、供应链管理等关键领域。
FoodSky 不仅提供了一个高效的食品知识平台,还为食品计算领域的智能化发展奠定了基础。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 “Stay Hungry, Stay Foolish” —— 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











