



ADAPT: Action-aware Driving Caption Transformer
含CSP(Control Signal Prediction)和DCG(Driving Caption Generation)两个部分
1、结构概述
预训练的 Video Swin Transformer (Swin_base_patch244_window877_kinetics400_22k.pth),用于提取图片特征,其参数参与调试;
DCG基本结构由 BertImgModel 和 BertPredictionHeadTransform 构成,实现一个图像识别解释的Bert结构:BertForImageCaptioning;
CSP基本结构由 BertEncoder,线性img_embedding,线性decoder组成,实现图片至控制信号(速度和方向)的预测。
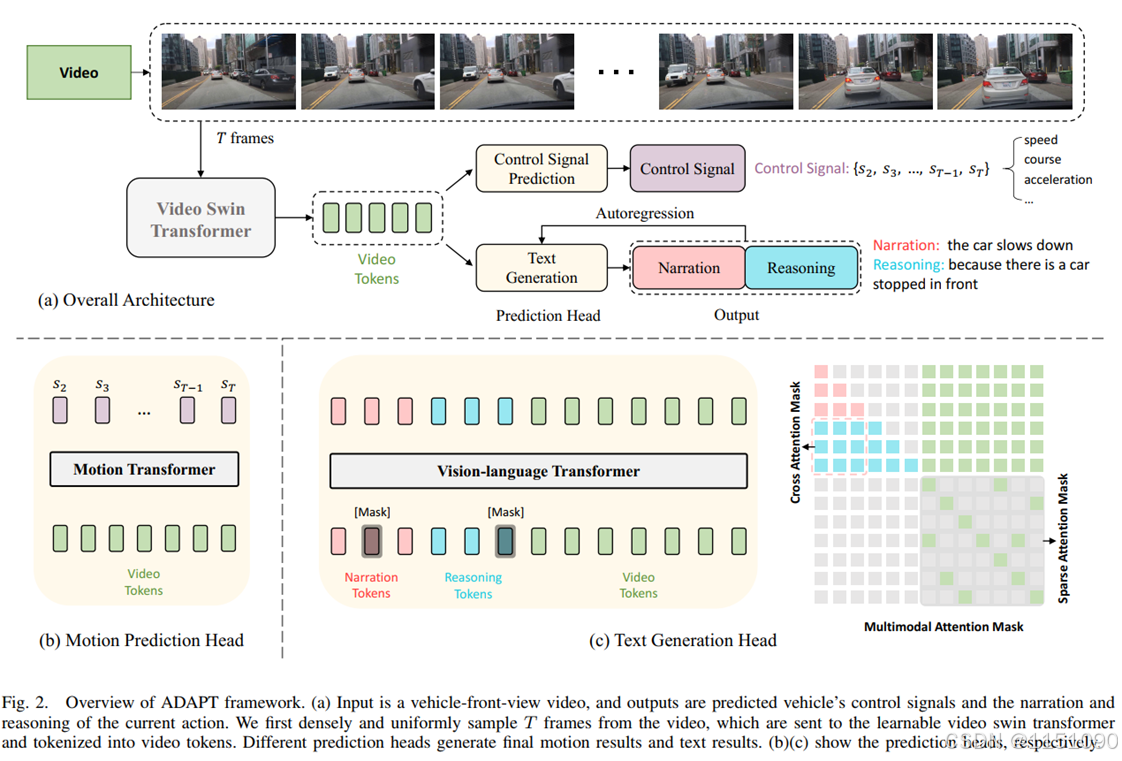
2、DCG(Driving Caption Generation)详解
DCG的流程是:
(1)输入转成32帧的视频、对应的汽车动作和理解,如:"[Action narration:] the car pulls over to the right side of the road, [Reasoning:] because the car is parking"。
(2)导入用于提取图片特征的video transformer模型,如:Swin_base_patch244_window877_kinetics400_22k.pth。
(3)初始化用于文字识别理解的BERT和用于分词的tokenizer,使用随机初始化的bert_base_uncased结构;这里的BERT是一种BertForImageCaptioning模型。
(4)根据video transformer模型、BERT、tokenizer构建视频理解的模型,并训练,video transformer的参数也参与训练,并不冻结。
核心代码1:video transformer模型的导入;BERT、tokenizer模型的初始化
# Get Video Swin backbone
swin_model = get_swin_model(args)
# Get BERT and tokenizer for DCG (Driving Caption Generation)
bert_model, config, tokenizer = get_bert_model(args)
def get_swin_model(args):
if int(args.img_res) == 384:
assert args.vidswin_size == "large"
config_path = 'src/modeling/video_swin/swin_%s_384_patch244_window81212_kinetics%s_22k.py'%(args.vidswin_size, args.kinetics)
model_path = 'models/video_swin_transformer/swin_%s_384_patch244_window81212_kinetics%s_22k.pth'%(args.vidswin_size, args.kinetics)
else:
# in the case that args.img_res == '224'
config_path = 'src/modeling/video_swin/swin_%s_patch244_window877_kinetics%s_22k.py'%(args.vidswin_size, args.kinetics)
model_path = 'models/video_swin_transformer/swin_%s_patch244_window877_kinetics%s_22k.pth'%(args.vidswin_size, args.kinetics)
if args.pretrained_2d:
config_path = 'src/modeling/video_swin/swin_base_patch244_window877_kinetics400_22k.py'
model_path = 'models/swin_transformer/swin_base_patch4_window7_224_22k.pth'
logger.info(f'video swin (config path): {config_path}')
if args.pretrained_checkpoint == '':
logger.info(f'video swin (model path): {model_path}')
cfg = Config.fromfile(config_path)
pretrained_path = model_path if args.pretrained_2d else None
backbone = SwinTransformer3D(
pretrained=pretrained_path,
pretrained2d=args.pretrained_2d,
patch_size=cfg.model['backbone']['patch_size'],
in_chans=3,
embed_dim=cfg.model['backbone']['embed_dim'],
depths=cfg.model['backbone']['depths'],
num_heads=cfg.model['backbone']['num_heads'],
window_size=cfg.model['backbone']['window_size'],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.2,
norm_layer=torch.nn.LayerNorm,
patch_norm=cfg.model['backbone']['patch_norm'],
frozen_stages=-1,
use_checkpoint=False)
video_swin = myVideoSwin(args=args, cfg=cfg, backbone=backbone)
if not args.pretrained_2d:
checkpoint_3d = torch.load(model_path, map_location='cpu')
video_swin.load_state_dict(checkpoint_3d['state_dict'], strict=False)
else:
video_swin.backbone.init_weights()
return video_swin
#BertForImageCaptioning
class BertForImageCaptioning(BertPreTrainedModel):
r"""
Bert for Image Captioning.
"""
def __init__(self, config):
super(BertForImageCaptioning, self).__init__(config)
self.config = config
self.bert = BertImgModel(config)
self.cls = BertCaptioningHeads(config)
self.loss = BertCaptioningLoss(config)
# cclin
self.cls_img_feat = BertIFPredictionHead(config)
self.loss_img_feat = BertImgFeatureLoss(config)
self.apply(self.init_weights)
self.tie_weights()
self.model_type = getattr(config, 'model_type', 'bert')
if self.model_type == 'TIMM_vit':
self.bert = BertImgModel(config)
#BertImgModel
def __init__(self, config):
super(BertImgModel, self).__init__(config)
self.embeddings = BertEmbeddings(config)
self.encoder = BertEncoder(config)
self.pooler = BertPooler(config)
self.img_dim = config.img_feature_dim #2054 #565
logger.info('BertImgModel Image Dimension: {}'.format(self.img_dim))
self.img_feature_type = config.img_feature_type
try:
self.use_img_layernorm = config.use_img_layernorm
except:
self.use_img_layernorm = None
if config.img_feature_type == 'dis_code':
self.code_embeddings = nn.Embedding(config.code_voc, config.code_dim, padding_idx=0)
self.img_embedding = nn.Linear(config.code_dim, self.config.hidden_size, bias=True)
elif config.img_feature_type == 'dis_code_t': # transpose
self.code_embeddings = nn.Embedding(config.code_voc, config.code_dim, padding_idx=0)
self.img_embedding = nn.Linear(config.code_size, self.config.hidden_size, bias=True)
elif config.img_feature_type == 'dis_code_scale': # scaled
self.input_embeddings = nn.Linear(config.code_dim, config.code_size, bias=True)
self.code_embeddings = nn.Embedding(config.code_voc, config.code_dim, padding_idx=0)
self.img_embedding = nn.Linear(config.code_dim, self.config.hidden_size, bias=True)
else:
self.img_embedding = nn.Linear(self.img_dim, self.config.hidden_size, bias=True)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
if self.use_img_layernorm:
self.LayerNorm = LayerNormClass(config.hidden_size, eps=config.img_layer_norm_eps)
self.apply(self.init_weights)
self.model_type = getattr(config, 'model_type', 'bert')
if self.model_type == 'TIMM_vit':
self.encoder = TIMMVitEncoder(config)
# re-initialize img_embedding weight
# self.img_embedding.weight.data.normal_(mean=0.0, std=config.img_initializer_range)
#BertEncoder
class BertEncoder(nn.Module):
def __init__(self, config):
super(BertEncoder, self).__init__()
self.output_attentions = config.output_attentions
self.output_hidden_states = config.output_hidden_states
self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])
核心代码2:vision-language: VideoTransformer及forward函数
class VideoTransformer(torch.nn.Module):
""" This is the one head module that performs Dirving Caption Generation. """
def __init__(self, args, config, swin, transformer_encoder):
super(VideoTransformer, self).__init__()
""" Initializes the model.
Parameters:
args: basic args of ADAPT, mostly defined in `src/configs/VidSwinBert/BDDX_multi_default.json` and input args
config: config of transformer_encoder, mostly defined in `models/captioning/bert-base-uncased/config.json`
swin: torch module of the backbone to be used. See `src/modeling/load_swin.py`
transformer_encoder: torch module of the transformer architecture. See `src/modeling/load_bert.py`
"""
self.config = config
self.use_checkpoint = args.use_checkpoint and not args.freeze_backbone
if self.use_checkpoint:
self.swin = checkpoint_wrapper(swin, offload_to_cpu=True)
else:
self.swin = swin
self.trans_encoder = transformer_encoder
self.img_feature_dim = int(args.img_feature_dim)
self.use_grid_feat = args.grid_feat
self.latent_feat_size = self.swin.backbone.norm.normalized_shape[0]
self.fc = torch.nn.Linear(self.latent_feat_size, self.img_feature_dim)
self.compute_mask_on_the_fly = False # deprecated
self.mask_prob = args.mask_prob
self.mask_token_id = -1
self.max_img_seq_length = args.max_img_seq_length
self.max_num_frames = getattr(args, 'max_num_frames', 2)
self.expand_car_info = torch.nn.Linear(self.max_num_frames, self.img_feature_dim)
# add sensor information
self.use_car_sensor = getattr(args, 'use_car_sensor', False)
# learn soft attention mask
self.learn_mask_enabled = getattr(args, 'learn_mask_enabled', False)
self.sparse_mask_soft2hard = getattr(args, 'sparse_mask_soft2hard', False)
if self.learn_mask_enabled==True:
self.learn_vid_att = torch.nn.Embedding(args.max_img_seq_length*args.max_img_seq_length,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, *args, **kwargs):
""" The forward process of ADAPT,
Parameters:
input_ids: word tokens of input sentences tokenized by tokenizer
attention_mask: multimodal attention mask in Vision-Language transformer
token_type_ids: typen tokens of input sentences,
0 means it is a narration sentence and 1 means a reasoning sentence, same size with input_ids
img_feats: preprocessed frames of the video
masked_pos: [MASK] position when performing MLM, used to locate the masked words
masked_ids: groung truth of [MASK] when performing MLM
"""
# grad cam can only input a tuple (args, kwargs)
if isinstance(args, tuple) and len(args) != 0:
kwargs = args[0]
args= ()
images = kwargs['img_feats']
B, S, C, H, W = images.shape # batch, segment, chanel, hight, width
# (B x S x C x H x W) --> (B x C x S x H x W)
images = images.permute(0, 2, 1, 3, 4)
vid_feats = self.swin(images)
# tokenize video features to video tokens
if self.use_grid_feat==True:
vid_feats = vid_feats.permute(0, 2, 3, 4, 1)
vid_feats = vid_feats.view(B, -1, self.latent_feat_size)
# use an mlp to transform video token dimension
vid_feats = self.fc(vid_feats)
# use video features to predict car tensor
if self.use_car_sensor:
car_infos = kwargs['car_info']
car_infos = self.expand_car_info(car_infos)
vid_feats = torch.cat((vid_feats, car_infos), dim=1)
# prepare VL transformer inputs
kwargs['img_feats'] = vid_feats
# disable bert attention outputs to avoid some bugs
if self.trans_encoder.bert.encoder.output_attentions:
self.trans_encoder.bert.encoder.set_output_attentions(False)
# learn soft attention mask
if self.learn_mask_enabled:
kwargs['attention_mask'] = kwargs['attention_mask'].float()
vid_att_len = self.max_img_seq_length
learn_att = self.learn_vid_att.weight.reshape(vid_att_len,vid_att_len)
learn_att = self.sigmoid(learn_att)
diag_mask = torch.diag(torch.ones(vid_att_len)).cuda()
video_attention = (1. - diag_mask)*learn_att
learn_att = diag_mask + video_attention
if self.sparse_mask_soft2hard:
learn_att = (learn_att>=0.5)*1.0
learn_att = learn_att.cuda()
learn_att.requires_grad = False
kwargs['attention_mask'][:, -vid_att_len::, -vid_att_len::] = learn_att
# Driving Caption Generation head
outputs = self.trans_encoder(*args, **kwargs)
# sparse attention mask loss
if self.learn_mask_enabled:
loss_sparsity = self.get_loss_sparsity(video_attention)
outputs = outputs + (loss_sparsity, )
return outputs
#trans_encoder的forward函数
def forward(self, input_ids, token_type_ids=None, attention_mask=None,
position_ids=None, head_mask=None, img_feats=None,
encoder_history_states=None):
if attention_mask is None:
if img_feats is not None:
attention_mask = torch.ones((input_ids.shape[0], input_ids.shape[1] + img_feats.shape[1]), device=input_ids.device)
else:
attention_mask = torch.ones_like(input_ids)
#if img_feats is not None: attention_mask = torch.ones_like((input_ids.shape[0], input_ids.shape[1]+img_feats.shape[1]))
#else: attention_mask = torch.ones_like(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
# We create a 3D attention mask from a 2D tensor mask.
# Sizes are [batch_size, 1, 1, to_seq_length]
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
# this attention mask is more simple than the triangular masking of causal attention
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
if attention_mask.dim() == 2:
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
elif attention_mask.dim() == 3:
extended_attention_mask = attention_mask.unsqueeze(1)
else:
raise NotImplementedError
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
if head_mask is not None:
if head_mask.dim() == 1:
head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
head_mask = head_mask.expand(self.config.num_hidden_layers, -1, -1, -1, -1)
elif head_mask.dim() == 2:
head_mask = head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1) # We can specify head_mask for each layer
head_mask = head_mask.to(dtype=next(self.parameters()).dtype) # switch to fload if need + fp16 compatibility
else:
head_mask = [None] * self.config.num_hidden_layers
embedding_output = self.embeddings(input_ids, position_ids=position_ids,
token_type_ids=token_type_ids)
# add img_embedding_output and sum with embedding_output
#logger.info('embedding_output: %s' % str(embedding_output.shape))
if encoder_history_states is not None:
if encoder_history_states[0].shape[1] != 0:
assert img_feats is None or img_feats.shape[1]==0, "Cannot take image features while using encoder history states"
if img_feats is not None:
if self.img_feature_type == 'dis_code':
code_emb = self.code_embeddings(img_feats)
img_embedding_output = self.img_embedding(code_emb)
elif self.img_feature_type == 'dis_code_t': # transpose
code_emb = self.code_embeddings(img_feats)
code_emb = code_emb.permute(0, 2, 1)
img_embedding_output = self.img_embedding(code_emb)
elif self.img_feature_type == 'dis_code_scale': # left scaled
code_emb = self.code_embeddings(img_feats)
#scale_output =
# add scale ouput
img_embedding_output = self.img_embedding(code_emb)
elif self.img_feature_type == 'e2e' and self.model_type == 'TIMM_vit':
img_embedding_output = img_feats
else:
if torch._C._get_tracing_state():
# Ugly workaround to make this work for ONNX.
# It is also valid for PyTorch bu I keep this path separate to remove once fixed in ONNX
img_embedding_output = self.img_embedding(img_feats.squeeze(0)).unsqueeze(0)
else:
img_embedding_output = self.img_embedding(img_feats)
#logger.info('img_embedding_output: %s' % str(img_embedding_output.shape))
if self.use_img_layernorm:
img_embedding_output = self.LayerNorm(img_embedding_output)
# add dropout on image embedding
img_embedding_output = self.dropout(img_embedding_output)
# sum two embeddings
#padding_matrix = torch.zeros((embedding_output.shape[0], embedding_output.shape[1]-img_embedding_output.shape[1], embedding_output.shape[2])).cuda()
#img_embedding_output = torch.cat((padding_matrix, img_embedding_output), 1)
#embedding_output = embedding_output + img_embedding_output
# concatenate two embeddings
embedding_output = torch.cat((embedding_output, img_embedding_output), 1)
encoder_outputs = self.encoder(embedding_output,
extended_attention_mask, head_mask=head_mask,
encoder_history_states=encoder_history_states)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output)
outputs = (sequence_output, pooled_output,) + encoder_outputs[1:] # add hidden_states and attentions if they are here
return outputs # sequence_o
3、CSP(Control Signal Prediction)详解
CSP的图片特征提取的部分与DCG一致,不同的是控制信号建模预测的部分,给出核心代码如下:
CSP核心代码:
class Sensor_Pred_Head(torch.nn.Module):
""" This is the Control Signal Prediction head that performs sensor regression """
def __init__(self, args):
""" Initializes the prediction head.
A simple transformer that performs sensor regression.
We simply use a transformer to regress the whole signals of a video, which is superficial and could be optimized to a large extent.
"""
super(Sensor_Pred_Head, self).__init__()
self.img_feature_dim = int(args.img_feature_dim)
self.use_grid_feat = args.grid_feat
# Motion Transformer implemented by bert
self.config = BertConfig.from_pretrained(args.config_name if args.config_name else \
args.model_name_or_path, num_labels=2, finetuning_task='image_captioning')
self.encoder = BertEncoder(self.config)
# type number of control signals to be used
# TODO: Set this variable as an argument, corresponging to the control signal in dataloader
self.sensor_dim = len(args.signal_types)
self.sensor_embedding = torch.nn.Linear(self.sensor_dim, self.config.hidden_size)
self.sensor_dropout = nn.Dropout(self.config.hidden_dropout_prob)
# a mlp to transform the dimension of video feature
self.img_dim = self.img_feature_dim
self.img_embedding = nn.Linear(self.img_dim, self.config.hidden_size, bias=True)
self.img_dropout = nn.Dropout(self.config.hidden_dropout_prob)
# a sample regression decoder
self.decoder = nn.Linear(self.config.hidden_size, self.sensor_dim)
def forward(self, *args, **kwargs):
"""The forward process.
Parameters:
img_feats: video features extracted by video swin
car_info: ground truth of control signals
"""
vid_feats = kwargs['img_feats']
car_info = kwargs['car_info']
car_info = car_info.permute(0, 2, 1)
B, S, C = car_info.shape
assert C == self.sensor_dim, f"{C}, {self.sensor_dim}"
frame_num = S
img_embedding_output = self.img_embedding(vid_feats)
img_embedding_output = self.img_dropout(img_embedding_output)
extended_attention_mask = self.get_attn_mask(img_embedding_output)
encoder_outputs = self.encoder(img_embedding_output,
extended_attention_mask)
sequence_output = encoder_outputs[0][:, :frame_num, :]
pred_tensor = self.decoder(sequence_output)
loss = self.get_l2_loss(pred_tensor, car_info)
return loss, pred_tensor
4、分析
(1)控制信号预测的Sensor_Pred_Head虽然建立了sensor_embedding的部分,但是在forward函数中并未使用;
(2)BDD数据集除汽车动作文字理解外,还有车道、物体的标注信息,可用于物体的识别、分类;本文没有给出详细的物体识别、可行驶轨迹预测等信息;
(3)BERT结构不仅用于文字理解,也用于时序信息建模,模型实现理论基础是:emdedding、mask、多层注意力机制。
(4)改进方案:添加sensor_embedding查看效果;添加更多物体识别、轨迹预测的功能;当前语义理解、语库都比较小,相当于建立了一个专用的两句话描述汽车当前行动和原因的语言模型;再找点文章或者专利对比一下,想几个前沿可行方案吧


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









