






RabbitMQ
消息中间件的概念:
消息中间件独特的优势就是可异步处理.而不需要定时去检查,redis也可以,但需要定时去查,一致性较差.消息队列则不存在,也不是绝对的,消息过多也会积压.
消息中间件随之带来的问题:
如何选择同步和异步处理?
消息安全?丢失重复如何搞?
延迟如何降低
消息的顺序问题
是否重发?如何保证幂等性
消息中间件的使用场景:
流量削峰,分流,限流,缓冲,队列机制,只能保证最终一致性的,消息驱动.
MQ的选择:
开源自己能修复.
行业内流行的技术.社区活跃.问题好解决.bug与稳定性较好.
消息可靠、支持集群、性能要好.
几个MQ的区别与共同点:
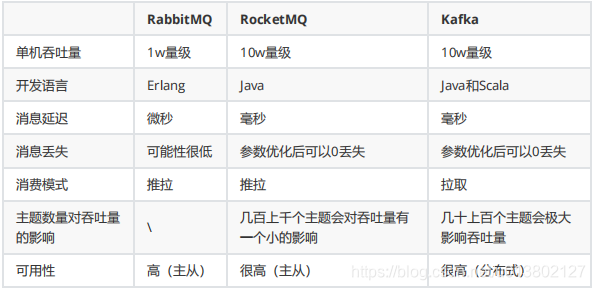
RabbitMQ:
AMQP协议
轻量级、灵活的配置、多种语言支持
无法堆积消息;性能三个中最差;二次开发和拓展较为复杂;erlang是爱立信公司的开发语言.
RocketMQ:借鉴了kafka的设计
JMS规范
只支持java.兼容性还是一般.
Kafka:
可靠性最高,可伸缩、消息持久化、消息分区(666)、副本和容错.
批处理和异步处理设计较好,如果压缩,那么就可以处理2000万级的消息.但是延迟性无发保证哦.
MQ的应用场景:
典型案例:秒杀 秒杀这种高并发的难题,永远是推动技术的关键点.上了缓存,可以避免了数据库崩溃,上了MQ,就可以避免服务器的压力.
高并发,为了减轻后面绝大部分业务的压力,用上MQ,就可以适当减轻.
某勾的B端和C端架构案例:
B端的更新,需要快速的通知到C端,这时定时任务,缓存,都无法达到快速,只能使用通知形式来告知C端,可通知的有zk和mq,zk并不适合大量请求,所以mq就假设在中间
JMS规范和AMQP协议:
JMS java消息服务 java message service
报文头和消息主体,头由官方指定的字段
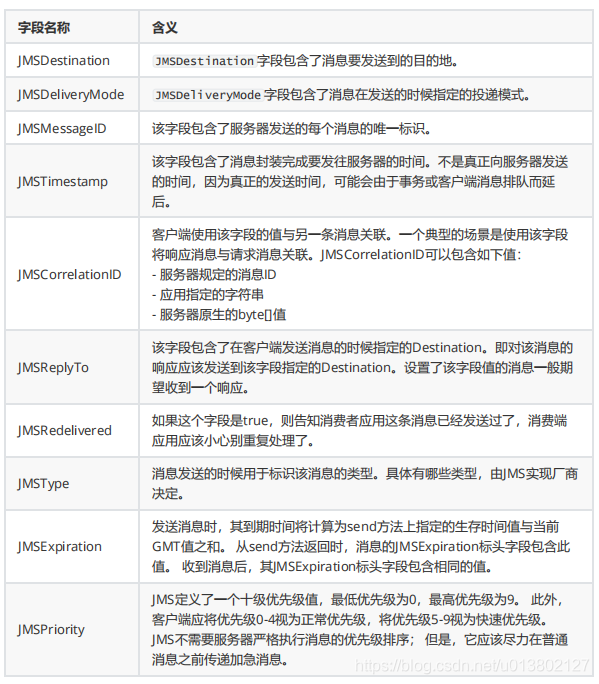
消息体类型:
简单文本
序列化对象
属性集合
字节流
原始值流
无有效负载消息
体系结构:
供应商产品 适配器 适配其他的MQ
clinet
producer
consumer
message
queue
topic
对象模型:
connection factory连接工厂 创建连接
Connection 连接接口
Destination 接口,目标 决定往哪发,主题还是点
Session 会话
MessageConsumer
MessageProducer
Message 具体的消息类型实体对象
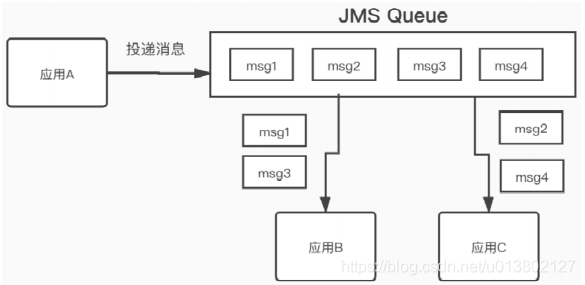
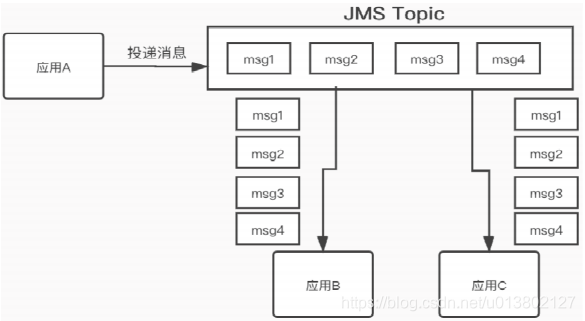
点对点模型:图1
投递消息到JMS queue ,一条消息只能被一个消费者获得.多个消费者轮训获取消息,不会重复获得
发布订阅模式:图2
设置一个主题,生产者向主题里发送消息,订阅了主题的消费者都会得到消息.可重复获得.生产者只管发,如果没消费者收到那么会丢失,但可设置持久化.消费者上线会重发.
传递方式:
默认不持久化消息,需要设置.
供应商:
一些主流的开源MQ和商业的MQ.
JMS的问题:
点对点集群没有问题,但是主题情况下的集群,那么就会出现问题.多应用集群下,单个应用集群就会出现重复消费.要不就用queue多个,要不就在分布式上锁或者hash负载
JMS的特性:
需要供应商桥接.
只能支持java
没有AMQP灵活
AMQP不需要桥接
AMQP 高级消息队列协议:
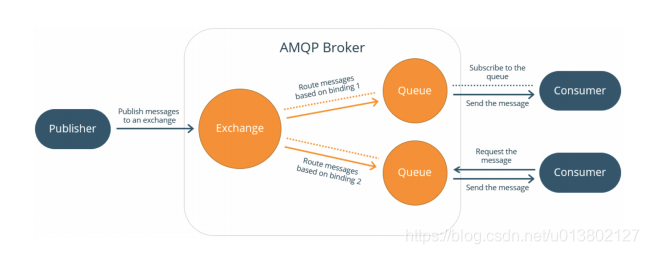
只要遵守该协议的语言,都可以使用rabbit MQ.不管多么冷门.
一些概念:
publisher发送者
consumer消费者
server 服务实例 broker
virtual host 虚机
exchange 交换器
routing key路由键
bindings绑定关系
message queue 消息容器
传输层架构:
一个长的消息,会切为很多个小块,称之为负载,前头称之为帧头,最后成为帧尾
数据类型:
协议协商:
先握手协商,三次握手那些,添加一些选项和要求,客户端回复才能开始正式的通信.这样可以提前约定好一些配置,防止传输数显问题.
数据帧界定:
1:每个连接发一个帧,简单但是慢
2:添加边界,简单但是解析慢
3:计算数据大小,发送前加上该数据帧的大小,这样解析很快AMQP使用该种
AMQP实现JMS客户端:
有一些局限性:
JMS不支持服务器会话
XA事物支持接口没有实现
队列选择器未实现
支持SSL和桃姐选项,但使用RabbitMQ客户端提供的SSL协议
RabbitMQ不支持JMS的Noloacl订阅功能,禁止消费者接收通过自身的连接发布的消息,可以调用包含no local的方法,但该方法将被忽略
RabbitMQ架构:
较为热门的一个MQ,高可靠、易拓展、高可用、功能丰富,语言种类支持丰富,冷门语言都可支持.遵循AMQP协议,Erlang开发.插件支持MQTT其他协议.MQTT是互联网使用较多的协议.报文简洁;
整体架构:
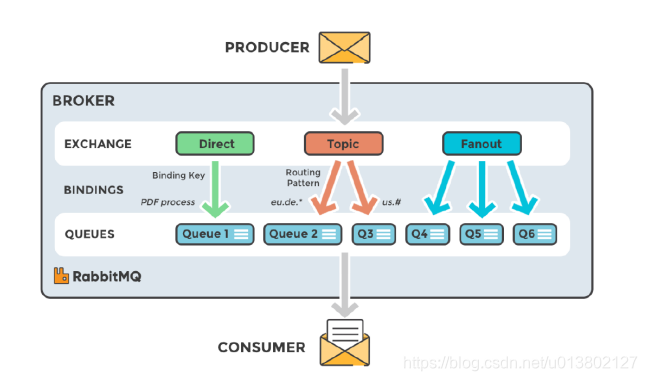
Exchange交换器类型:
fanout:
把消息发送到与它绑定的消息队列,广播形式,多个队列都会收到,消息发出没有客户端在线就丢失
direct:
消息会routingkey 和 binding key都匹配的队列,也可多个队列.但一条消息只能发到给一个队列.bk是生产者去指定的.
topic:
通过通配符,发送到匹配的队列,rk为具体的字符串,bk为通配模式,rk匹配了多个bk的队列,可广播.
header:
根据头信息进行匹配,性能较差,不咋用.
数据存储机制:
持久化的消息内存和磁盘都会保存,内存不够的话内存中的会清除
非持久化一般都在内存,内存压力大进行刷盘减轻内存压力
存储分为两部分,队列索引和消息存储
索引文件存储 .idx 存储路径、是否被消费、是否被消费ack
文件名从0开始,每个文件存储默认16384条信息,再就另起一个文件.
数据存储为rdq文件,也有一个容量,超出就会再起一个文件,和索引文件一样.
消息通过queue_index_embed_msgs_below决定存储在索引还是数据文件,默认4096B,大于就是数据文件存储,小于就是索引文件.rebbitmq.conf可设置该参数
读取消息时通过msg_id找到对应存储文件.还有锁的机制,store去请求锁
删除消息,当文件中的消息被消费确认了后,消费确认率达到一定数值后,就会进行锁定文件合并,后面文件写入到前面,删除后面的文件.
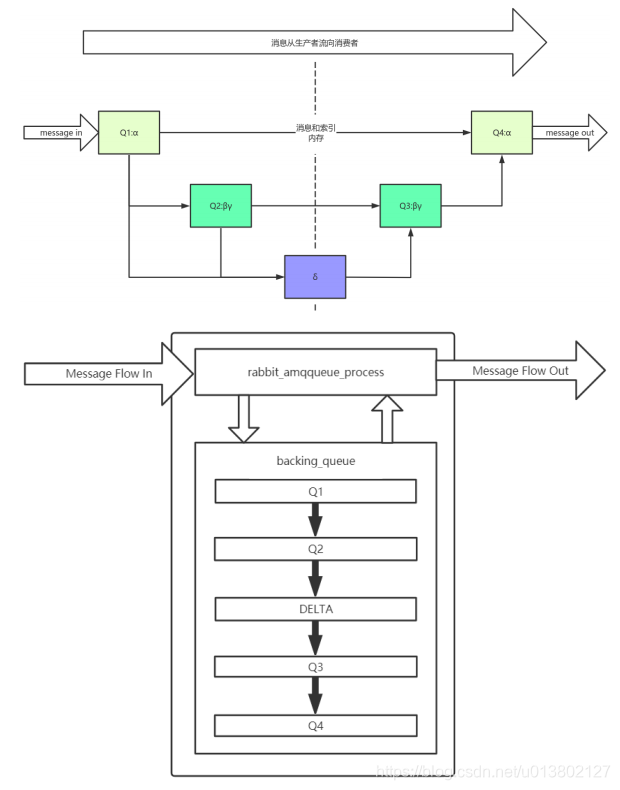
队列结构:
alpha 消息和索引都在内存
beta 索引在内存, 消息在硬盘
gama 部分索引和消息在硬盘, 另一部分在内存
derta 索引和消息都在硬盘
获取消息:
1. 首先会从Q4中获取消息,如果获取成功则返回。
2. 如果Q4为空,则尝试从Q3中获取消息,系统首先会判断Q3是否为空,如果为空则返回队列为空,即此时队列中无消息。
3. 如果Q3不为空,则取出Q3中的消息;进而再判断此时Q3和Delta中的长度,如果都为空,则可以认为 Q2、Delta、 Q3、Q4 全部为空,此时将Q1中的消息直接转移至Q4,下次直接从Q4 中获取消息。
4. 如果Q3为空,Delta不为空,则将Delta的消息转移至Q3中,下次可以直接从Q3中获取消息。在将消息从Delta转移到Q3的过程中,是按照索引分段读取的,首先读取某一段,然后判断读取的消息的个数与Delta中消息的个数是否相等,如果相等,则可以判定此时Delta中己无消息,则直接将Q2和刚读取到的消息一并放入到Q3中,如果不相等,仅将此次读取到的消息转移到Q3。
消息堆积为什么会性能下降?
不断堆积消息,占用内存,内存吃紧就会开始对磁盘进行IO,后期拿消息就会在磁盘中IO读取,这样大大降低性能.
安装和配置RabbitMQ:
需要安装Erlang23.0.2-1
Rabbit3.8.4
MQ还依赖Linux中的socat yum一下
一些部署的命令:
启用RabbitMQ的管理插件
rabbitmq-plugins enable rabbitmq_management
开启RabbitMQ
systemctl start rabbitmq-server 或者 rabbitmq-server
后台启动
rabbitmq-server -detached
添加用户
rabbitmqctl add_user root 123456
给用户添加权限 给root用户在虚拟主机"/"上的配置、写、读的权限
rabbitmqctl set_permissions root -p / ".*" ".*" ".*"
给用户设置标签
rabbitmqctl set_user_tags root administrator
用户的标签和权限:

RabbitMQ常用命令:
前台启动Erlang VM和RabbitMQ :rabbitmq-server
后台启动 :rabbitmq-server -detached
停止RabbitMQ和Erlang VM :rabbitmqctl stop
查看所有队列 :rabbitmqctl list_queues
查看所有虚拟主机 :rabbitmqctl list_vhosts
在Erlang VM运行的情况下启动RabbitMQ应用 :rabbitmqctl start_app rabbitmqctl stop_app
查看节点状态 :rabbitmqctl status
查看所有可用的插件 :rabbitmq-plugins list
启用插件 :rabbitmq-plugins enable <plugin-name>
停用插件 :rabbitmq-plugins disable <plugin-name>
添加用户 :rabbitmqctl add_user username password
列出所有用户: rabbitmqctl list_users
删除用户: rabbitmqctl delete_user username
清除用户权限: rabbitmqctl clear_permissions -p vhostpath username
列出用户权限: rabbitmqctl list_user_permissions username
修改密码: rabbitmqctl change_password username newpassword
设置用户权限: rabbitmqctl set_permissions -p vhostpath username ".*" ".*" ".*"
创建虚拟主机: rabbitmqctl add_vhost vhostpath
列出所以虚拟主机: rabbitmqctl list_vhosts
列出虚拟主机上的所有权限: rabbitmqctl list_permissions -p vhostpath
删除虚拟主机: rabbitmqctl delete_vhost vhost vhostpath
移除所有数据,要在 rabbitmqctl stop_app 之后使用: rabbitmqctl reset
-*kill 掉rabbitmq时会出现一个epmd进程,负责通信(4369)集群之间和端口映射的守护进程
设置权限的允许拒绝代码:^$拒绝,*.允许
RabbitMQ工作流程:
生产者:
1:建立TCP连接,建立通道
2:声明交换器,检查mq的交换器是否匹配,是否持久化
3:声明一个消息队列,检查与mq的队列是否一致,检查其中的属性
4:交换器与队列进行绑定.
5:通过通道开始发送消息到broker,包含RK、BK等信息.
6:MQ的交换器根据RK和BK进行查找相应的队列,找到就存储到队列中
7:找不到就选择丢弃还是退回给生产者
8:关闭通道和连接
消费者:
1:与MQ连接,建立通道
2:一种主动拉取,一种被动等待推送.
3:拿到消息开始处理
4:处理完毕给MQ ack确认,也可自动确认,收到消息就给MQ ack
相关代码:
生产者:
添加依赖 rabbitmq
获取ConnectionFactory
setHost("hostname")
setVHost("/");
setUsername();
setPassword();
setPort(5672);
Connection初始化 factory.new
Channel初始化 connection.create
channel通道创建队列.queue
参数:
队列名
是否持久化 durable
是否排他 exclusive
是否自动清除 auto-delete
队列属性, null表默认.
channel创建交换器.exchange
参数:
交换器名称
交换器类型
是否持久化 durable
是否自动清除 auto-delete
交换器属性 null代表默认
channel交换器队列绑定queueBind
队列名
交换器名
routing key自定义一个rk
channel发送消息basicpublish
交换器名
rk
消息属性对象BasicProperties
消息的字节流
channel关闭
connection关闭
消费者:
主动拉取:
工厂创建 ConnectionFactory factory = new ConnectionFactory();
setUri("amqp://root:123456@host:5672/vhost的uri代码")
获取连接 Connection conn = factory.newConnection();
创建通道 Channel channel = conn.createChannel();
保险一下主动创建队列 channel.queueDeclare(QUEUE_NAME, false, false, false, null);
channel.basicGet() 获取消息
获取队列名
是否自动ack
getBody()获取消息具体内容
关闭通道
等待推送:
工厂创建
setUri("amqp://root:123456@host:5672/vhost的uri代码")
获取连接
创建通道
保险一下主动创建队列
channel.basicConsume()
队列名
有消息的处理方法
关闭通道.
关闭连接.
连接和通道的关系:
线程对应一个通道,多个通道可使用一个复用的TCP连接.提高效率,减少消耗.
rabbitMQ的源码 都参照着AMQP协议的架构进行的拓展.大部分的方法都是AMQP提供的方法
RabbitMQ的连接工厂生产的连接底层是AMQP协议的模型,AMQP协议TCP连接底层使用javaNIO模型,并使用selector机制进行多通道复用一个TCP连接进行通信.
RabbitMQ工作模式:
工作模式中一些知识点:
临时队列:
当生产者无法确定哪些队列接收这些消息,也就是没有明确队列时,AMQP就会随机建立一个队列与交换器绑定,然后发送给该队列中的消费者,但是该消费者得绑定生产者的交换器.
绑定:
队列与交换器绑定了,交换器不会去匹配rk,直接发送给绑定的队列中.
默认交换器:
不声明交换器.直接声明一个队列,然后就发送消息
工作队列:direct类型交换器
一堆消息均衡的发送到每个节点,而不是广播形式.分布式应用常用的模式.
发布订阅模式:fanout类型交换器
消息发送到交换器,交换器将消息发送到匹配的主题中,消费者订阅了匹配的主题就可接收到消息,属于广播,主要匹配的主题都可以收到,订阅主题的消费者也都能收到适合日志型的消息发送.操作记录,通知类等等.
路由模式:(多消费者)
生产者发送多种类型的消息,每种携带不同的RK,消费者订阅时,根据自己需要的消息生成队列,与交换器绑定,交换器根据生产者发消息携带的RK路由到匹配的队列,消费者就能收到消息了
主题模式:(多生产者)
不同的消息生产者,发送有略微区别的消息,但又一些共同点,比如类型相同,地点不同,或者地点相同类型不同.这时候就主要topic主题模式来根据消息的BK进行通配过滤,符合BK的就接收,否则不接收.
通配符规则:
.负责区分间隔
*:1个单词 a.* a.c可以,a.b.c不行了就
#:0或多个 a.# a.b.c可以了
queueBind(队列,交换器,RK)方法设置通配规则,就是绑定队列的方法,只不过把RK换成了通配.
Spring整合MQ:
Spring-amqp AMQP的封装
spring-rabbit rabbit的封装
添加后者就行;
配置文件xml:
rabbit:connection-actory
rabbit:admin 交换器队列等工具类
rabbit:template 消息模板类
rabbit:queue 队列声明
rabbit:direct-exchange 交换器声明
rabbit:bindings
rabbit:binding key="bk" exchange="可以绑定其他交换器" queue="队列名"
RabbitTemplate对象负责对消息进行管理
MessagePropertiesBuilder负责消息的属性
MessageBuider对象负责创建消息
推送模式:
配置文件:
rabbit:listener-container
rabbit:listener ref="实现了ChannelAwareMeesageListener或MessageListener监听器的bean Id" queue="队列名"
注解整合:
创建工厂bean,new一个工厂别给定uri
创建rabbitTemplate,把工厂给进去
创建rabbitAdmin工具类,把工厂给进去
创建队列 QueueBuilder创建
创建交换器 四个类型交换器都有相关的实体对象.
创建绑定 BindingBuilder 来绑定
发消息用的对象:
RabbitTemplate对象负责对消息进行管理
MessagePropertiesBuilder负责消息的属性
MessageBuider对象负责创建消息
注解的推送模式:
配置类:
多出的配置
SimpleRabbitListenerContainerFactory(还有其他交换器类型的工厂类)
注入连接
注入确认模式setAcknowledgeMode(自动、常规、不确认)
注入消费者数量(最小多少并发)setConcurrentConsumers
注入最大消费者数量(最大并发)setMaxConcurrentConsumers
注入批次消费信息数量setBatchSize
@EnableRabbit 开启监听模式
创建监听类,创建一个方法添加注解@RabbitListener(队列名)
方法中的可选参数:
@Payload String str 消息内容
Message 消息对象
MessageProperties
@Header 具体头信息的属性
@Headers 头全部信息
SpringBoot整合RabbitMQ
依赖start-amqp
不需要创建工厂什么的了,只需要创建队列、交换器和绑定对象就行
配置:
host、vhost、username、password、port
可以使用AmqpTemplate,和RabbitTemplate一样
Rabbit高级特性:
消息可靠性:
消息一致性:分布式锁和消息队列
消息队列的做法:
生产消费端异常处理
异常处理重发spring yml可配置retry
MQ事务机制
一发一确认为一个事物,可回滚,但不建议使用.性能消耗太大
生产者确认机制
MQ收到消息并存储到内存或硬盘时,返回ack确认,ack会携带收到消息的编号,以回应生产者发送的哪条消息成功接收了
代码实现:
//标记为ack确认通道
channel.confirmSelect();
Spring boot:
配置文件新增:
spring.rabbitmq.publisher-confirm-type=correlated
spring.rabbitmq.publisher-returns=true
代码:
rabbitTemplate.setConfirmCallback()发送确认函数
批处理解决同步等待的性能问题:
攒几个等待一次,但也不是最佳
异步处理.攒几个启动线程
消费者确认机制
持久化消息
broker的集群
消费端限流
消息幂等性(处理多少次结果都一直)
持久化存储机制:
交换器持久化:创建时设置durable
队列持久化:创建时设置durable
消息持久化:
BasicProperties 里deliveryMode设置为2,
AMQP.BasicProperties.builder()来创建,发送消息方法时,将properties传入
数据存储位置:粘贴文档.太长了.
消费者确认机制:
确认模式:
none自行捕获异常
auto:不主动捕获异常.
manual:手动ack模式,处理完业务需要手动设置ack;
代码实现:
推送模式下basicConsume方法时,设置autoAck为false,该方法的第二个参数,使用该多态方法有个回调函数需要实现.在该方法进行处理.
确认方法:channel.basicack(消息标识,是否批量确认)
批量驳回:channel.basicNack(消息标识,,是否回列)
单条驳回:channel.basicReject(消息标识,是否回列)
springboot模式:
支持的配置:
#最大重试次数 spring.rabbitmq.listener.simple.retry.max-attempts=5
#是否开启消费者重试(为false时关闭消费者重试,意思不是“不重试”,而是一直收到消息直到jack 确认或者一直到超时) spring.rabbitmq.listener.simple.retry.enabled=true
#重试间隔时间(单位毫秒) spring.rabbitmq.listener.simple.retry.initial-interval=5000
# 重试超过最大次数后是否拒绝 spring.rabbitmq.listener.simple.default-requeue-rejected=false
#ack模式 spring.rabbitmq.listener.simple.acknowledge-mode=manual
RabbitListener注解中添加ackMode:确认模式
拉取模式:
rabbitTemplate.execute()消费确认方法
消费端限流:
对生产者端进行限制,不再发送新的消息到MQ, MQ设置阻断,拦截,暂停发布消息的连接,从而达到限流的目的
配置文件设置:
rabbitmq.conf中配置:
默认credit flow的流控机制,监控队列、通道、连接,
QoS保证机制.限制通道中接收却未被ack的消息数量,只针对推送模式有效,主动拉取不行,只能是ack型的消息,当达到设置的阈值后,MQ就停止向消费端发送消息.确认一条,MQ就再发送一条,始终保持你有设置阈值内的消息等待ack
代码实现:
channel.basicQoS((可选)未确认的消息大小(rabbit没有实现),(必须)最大等待ACK消息条数,(可选)手否通道内所有消费者生效,)
总结-消息可靠性保障:
1:最多一次
消息会丢失.因为不会重发,不持久化.适合非关键性的一些消息.
2:最少一次
开启事务机制和确认机制
消息、队列持久化
交换器备份
手动确认
3:恰好一次:
无法保障该情况.
可能会因为网络错误导致重发
消费端设置消息幂等性,比如批次号,时间流水号.保证每条消息都是处理一次,再次处理不影响最终结果.
支付宝铁律:一锁二判三操作
数据库索引唯一性,插入冲突.
可靠性分析:
firehose组件,可靠性分析,将正常生产出的消息复制发送到2个单独的队列,1个记录生产出的消息记录,1个记录消费的消息记录.
开启firehose: ctl trace_on [-p vhost]
关闭:ctl trace_off
rabbit tracing: 分析插件
比firehose相比对了日志,更清晰的查看消息内容.需要在management进行配置.
通过插件开启
TTL机制:
rabbitTTL机制可以设置消息过期:
代码:创建队列的argment Map里扔
x-message-ttl:队列中消息过期时间
x-expries:没有消费者情况下,也没有被使用的队列过期的时间.
命令行:
ctl set_policy 策略名 ".*" '{"策略名":策略值}' --apply-to queues
可持续添加表更新
springboot:
创建队列bean时 在queue new时添加arg集合
在发消息时设置过期时间properties
死信队列:
如果一个队列消息过期了,那么我们可以将它转到另一个队列里,由该队列的消费者来处理.这就是死信队列
死信交换器DLX,消息过期后被转发的DLX,与DLX绑定的队列就为死信队列DLQ;
死信队列需要的属性:
x-meesage-ttl:消息过期时间
x-dead-letter-exchange:指定死信队列
x-dead-letter-routing-key:指定死信的RK
延迟队列:
消息发到队列后,设置不立即被消费.间隔一段时间或者设置固定时间再消费该消息.
1:通过死信队列来实现延迟队列,死信队列为正常的业务队列,发消息的队列就成为了延迟队列.但会出现问题,消息过期从队列尾部拿取,而前面的队列早已过期,失去延迟队列的意义
2:rabbitmq_delayed_message_exchange插件实现,缓存到延迟交换机中,根据TTL机制等待到期后根据RK发送到指定队列,再被该队列的消费者消费.这样的话就不会被队列的特性所影响,是在交换机上做过期处理.
下载该插件,安装:
把.ez的插件放到rabbit目录下的plugins中即可,rabbit自动搞嘛.
代码:
添加属性:x-delayed-type:交换器类型
创建交换器时交换器的类型设置为了x-delayed-message,交换器真实的类型被扔到了属性里.
设置过期时间的属性被自定义为:x-delay
RabbitMQ集群:
主备兔子窝模式:
备份节点不提供服务,主节点故障进行转移.主备通过共享存储进行共享存储.
铲子模式shovel:
在生产节点创建了备份队列,生产者发消息时也会发到备份队列一份,或者生产者生产队列已满时直接发送给备份队列.被shovel消费,再作为生产者转发到另一个MQ的队列中.
集群模式cluster:
所有节点彼此备份节点数据:
队列元数据、交换器明能属性、绑定关系元数据、vhost内队列、交换器和绑定提供命名空间和属性
镜像复制:
ALL主节点会将镜像队列复制到所有从节点上,其他节点的队列也会把队列复制到其他节点上,避免交叉浪费.
联邦模式 插件:
交换器federation plugin 队列federation plugin
节点消息同步插件.
通过单相连接,从交换器或者队列同步到从节点交换器或队列中.
异地多活:
可伸缩、异地伸缩
容灾性能好.网络影响大
成本有效利用
单机多实例搭建:
rabbitmq_node_port文件用于设置MQ的服务发现,对外端口
rabbitmq_nodename文件用于设置rabbitMQ节点名称
环境变量:
RABBITMQ_NODE_IP_ADDRESS:将RabbitMQ绑定到一个网络接口。 如果要绑定多个网络接口,可以在配置文件中配置。 默认值:空字串。表示绑定到所有的网络接口。
RABBITMQ_NODE_PORT:默认值:5672
RABBITMQ_DIST_PORT:RabbitMQ节点之间通信以及节点和CLI工具通信用到的端口。 如果在配置文件中配置了kernel.inet_dist_listen_min 或者kernel.inet_dist_listen_max,则忽略该配置。 默认值:$RABBITMQ_NODE_PORT + 20000
ERL_EPMD_ADDRESS:epmd 使用的网络接口, epmd 用于节点之间以及节点和CLI之间的通信。 默认值:所有网络接口,包括和IPv4。
ERL_EPMD_PORT:epmd 使用的端口。 默认值:4369。
RABBITMQ_DISTRIBUTION_BUFFER_SIZE:节点之间通信连接使用的发送数据缓冲区大小限制, 单位是KB。推荐使用小于64MB的值。 默认值:128000
RABBITMQ_IO_THREAD_POOL_SIZE:Erlang运行时的 I/O 用到的线程数。不推荐小于32的值。 默认值:128(Linux),64(Windows)
RABBITMQ_NODENAME:RabbitMQ的节点名称。对于Erlang节点和机器,此名称应该唯一。 通过设置此值,可以在一台机器上多个RabbitMQ节点。 默认值:rabbit@$HOSTNAME(Unix-like),rabbit@%COMPUTERNAME%(Windows)。
RABBITMQ_CONFIG_FILE:RabbitMQ主要配置文件的路径。例如 /etc/rabbitmq/rabbitmq.conf 或 者 /data/configuration/rabbitmq.conf 是新格式的配置文件。 如果是老格式的配置文件,扩展名是 .config 或者不写。 默认值: 对于Unix: $RABBITMQ_HOME/etc/rabbitmq/rabbitmq Debian:/etc/rabbitmq/rabbitmq RPM: /etc/rabbitmq/rabbitmq MacOS(Homebrew): ${install_prefix}/etc/rabbitmq/rabbitmq , Homebrew的前缀通常是: /usr/local/ Windo%APPDATA%\RabbitMQ\rabbitmq
RABBITMQ_ADVANCED_CONFIG_FILE:RabbitMQ带 .config 的高级配置文件路径(基于Erlang配置)。例如, /data/rabbitmq/advanced.config 。默认值:Unix: $RABBITMQ_HOME/etc/rabbitmq/advancedDebian: /etc/rabbitmq/advancedRPM: /etc/rabbitmq/advancedMacOS(Homebrew): ${install_prefix}/etc/rabbitmq/advanced , 其中Homebrew前缀通常是 /etc/local/Windows: %APPDATA%\RabbitMQ\advanced 。
RABBITMQ_CONF_ENV_FILE:包含了环境变量定义的文件的目录(不使用 RABBITMQ_ 前缀)。 Windows上的文件名称与其他操作系同。 默认值: UNIX: $RABBITMQ_HOME/etc/rabbitmq/rabbitmq-env.conf Ubuntu和Debian: /etc/rabbitmq/rabbitmq-env.conf RPM: /etc/rabbitmq/rabbitmq-env.conf Mac(Homebrew): ${install_prefix}/etc/rabbitmq/rabbitmq-env.conf ,Homebrew的前缀一般是 /usr/local Windows: %APPDATA%\RabbitMQ\rabbitmq-env-conf.bat
RABBITMQ_MNESIA_BASE:
包含了RabbitMQ服务器的节点数据库、消息存储以及 集群状态文件子目录的根目录。除非显式设置了RABBITMQ_MNESIA_DIR 的值。需要确保RabbitMQ用户 在该目录拥有读、写和创建文件以及子目录的该变量一般不要覆盖。一般覆盖 RABBITMQ_MNESIA_DIR 变量。 默认值: Unix: $RABBITMQ_HOME/var/lib/rabbitmq/mnesia Ubuntu和Debian: /var/lib/rabbitmq/mnesia/RPM: /var/lib/rabbitmq/plugins MacOS(Homebrew):${install_prefix}/var/lib/rabbitmq/mnesia , 其中Homebrew的前缀一般是 /usr/localWindows: %APPDATA%\RabbitMQ
RABBITMQ_MNESIA_DIR:RabbitMQ节点存储数据的目录。该目录中包含了数据库、 消息存储、集群成员信息以及节点其他的持状态。 默认值: 通用UNIX包: $RABBITMQ_MNESIA_BASE/$RABBITMQ_NODENAME Ubuntu和Debia$RABBITMQ_MNESIA_BASE/$RABBITMQ_NODENAME RPM: $RABBITMQ_MNESIA_BASE/$RABBITMQ_NOMacOS (Homebrew): ${install_prefix}/var/lib/rabbitmq/mnesia/$RABBITMQ_NODENAME ,Homebrew的前缀一般是 /usr/local Windows: %APPDATA%\RabbitMQ\$RABBITMQ_NODENAME
RABBITMQ_PLUGINS_DIR:存放插件压缩文件的目录。RabbitMQ从此目录解压插件。 跟PATH变量语法类似,多个路径之间使用统的分隔符分隔 (Unix是 : ,Windows是';')。插件可以安装到该变量指定的任何目录。 路径不要有符。 默认值: 通用UNIX包: $RABBITMQ_HOME/plugins Ubuntu和Debian包: /var/lib/rabbitmq/plugins RPM: /var/lib/rabbitmq/plugins MacOS (Homebrew): ${install_prefix}/Cellar/rabbitmq/${version}/plugins , Homebrew的前缀一般是 /usr/lWindows: %RABBITMQ_HOME%\plugins
RABBITMQ_PLUGINS_EXPAND_DIR:节点解压插件的目录,并将该目录添加到代码路径。该路径不要包含特殊字符。 默认值: UNIX: $RABBITMQ_MNESIA_BASE/$RABBITMQ_NODENAME-plugins-expand Ubuntu和Debian packages: $RABBITMQ_MNESIA_BASE/$RABBITMQ_NODENAME-plugins-expand RPM: $RABBITMQ_MNESIA_BASE/$RABBITMQ_NODENAME-plugins-expand MacOS (Homebrew): ${install_prefix}/var/lib/rabbitmq/mnesia/$RABBITMQ_NODENAME-plugins-expand Window%APPDATA%\RabbitMQ\$RABBITMQ_NODENAME-plugins-expand
RABBITMQ_USE_LONGNAME:当设置为 true 的时候,RabbitMQ会使用全限定主机名标记节点。 在使用全限定域名的环境中使用。重置节点, 不能在全限定主机名和短名之间切换。 默认值: false 。
RABBITMQ_SERVER_CODE_PATH:当启用运行时的时候指定的外部代码路径(目录)。 当节点启动的时候,这个是值传给 erl 的命令行默认值:(none)
RABBITMQ_CTL_ERL_ARGS:当调用 rabbitmqctl 的时候传给 erl 的命令行参数。 可以给Erlang设置使用端口的范围: -kernel inet_dist_listen_min 35672 -kernel inet_dist_listen_max 35680 默认值:(none)
RABBITMQ_SERVER_ERL_ARGS:当调用RabbitMQ服务器的时候 erl 的标准命令行参数。 仅用于测试目的。使用该环境变量会覆盖默认默认值: Unix*: +P 1048576 +t 5000000 + stbt db +zdbbl 128000 Windows:没有
RABBITMQ_SERVER_ADDITIONAL_ERL_ARGS:调用RabbitMQ服务器的时候传递给 erl 命令的额外参数。 该变量指定的变量追加到默认参数列表( RABBITMQ_SERVER_ERL_ARGS )。 默认值: Unix*: 没有 Windows: 没有
RABBITMQ_SERVER_START_ARGS:调用RabbitMQ服务器的时候传给 erl 命令的额外参数。该变量不覆盖 RABBITMQ_SERVER_ERL_ARGS默认值:没有
RABBITMQ_ENABLED_PLUGINS_FILE:用于指定 enabled_plugins 文件所在的位置。默认: /etc/rabbitmq/enabled_plugins
启动命令:
1:环境变量启动:
export RABBITMQ_NODE_PORT=5673
export RABBITMQ_NODENAME=rabbit1
rabbit-server
2:配置文件启动:
修改存放配置文件目录的权限,安装rabbitMQ后会自动给创建一个rabbitmq的用户,chown :rabbitmq -R 目录名来修改权限,创建配置文件后也需要chown :rabbitmq 文件名来修改权限
配置文件内容:
management插件集群下端口修改:rabbitmq.conf:management.tcp.port=port
远程登录配置:
loopback_users.guest=true(false就可远程登录)
RABBITMQ_NODENAME=nodename
RABBITMQ_NODE_PORT=port
RABBITMQ_CONFIG_FILE=配置文件
rabbitmq-server
集群搭建:
将元数据拷贝一下:scp命令, 远程复制 文件路径 root@hostname:拷贝路径
stop_app停止mq应用保持erlang
reset清空信息
join_cluster rabbit@节点
踢出节点:
先stop_app该节点
然后forget_cluster该节点
添加节点:
reset一下
join_cluster 节点名称
集群下创建用户为集群用户,都可以使用.
镜像集群配置:
生产消息时,不论发到哪个节点,都会被转发到master节点上,再由master转发给其他镜像节点;
可随意更改,因为镜像集群是落到队列或交换器的,所以随时可以更改某个队列或交换器是否为镜像集群模式.
故障转移:
找一个版本最新的从节点,进行升主,这时有新消息就会丢失.
出现故障转移时,如果消费者申请了故障转移通知,将会收到通知.已发送出去等待ack的消息将会重新排队.
消费消息时主挂了而没有得到ack确认,那么这个消息会被重新消费,这时消费端需要注意重复消费问题.
发送消息时,发送到从节点,从节点转发时master挂掉,这个消息不会丢失,新master上来后会继续转发到新的master中,
生产者只要是与镜像节点进行交互时,是感知不到镜像与非镜像队列的区别的.
选举策略:
以运行时间为依据,谁长谁当主
配置参数:
ha-mode:
exactly设置副本队列的个数.下面那个参数.设置数量(包括主)
all:集群内所有都复制.
nodes:指定节点,下面参数设置具体节点名称.
ha-params: 配合上面模式对应的参数
配置方式:
ctl set_policy ha-halfmore "队列名" '{"ha-mode":"exactly","ha-params":2}' 配置过半 复制镜像队列
再用这个命令改成1就取消了镜像复制模式;
HAProxy负载均衡:
代理,对镜像复制进行负载.
安装gcc
解压haproxy
make targer=linux-glibc
make install
也可以yum安装.
授权:
groupadd -r -g 149 haproxy
添加用户:
useradd -g haproxy -r -s /sbin/nologin 看文档....
配置文件:
globallog 127.0.0.1 local0 info # 服务器最大并发连接数;如果请求的连接数高于此值,将其放入请求队列,等待其它连接被释 放;
maxconn 5120 # chroot /tmp # 指定用户
uid 149 # 指定组
gid 149 # 让haproxy以守护进程的方式工作于后台,其等同于“-D”选项的功能
# 当然,也可以在命令行中以“-db”选项将其禁用;
daemon # debug参数
quiet # 指定启动的haproxy进程的个数,只能用于守护进程模式的haproxy;
# 默认只启动一个进程,
# 鉴于调试困难等多方面的原因,在单进程仅能打开少数文件描述符的场景中才使用多进程模式;
# nbproc 20
nbproc 1
pidfile /var/run/haproxy.pid
defaults
log global
# tcp:实例运行于纯TCP模式,第4层代理模式,在客户端和服务器端之间将建立一个全双工的 连接,
# 且不会对7层报文做任何类型的检查;
# 通常用于SSL、SSH、SMTP等应用;
mode tcp
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
# contimeout 5s
timeout connect 5s
# 客户端空闲超时时间为60秒则HA 发起重连机制
timeout client 60000
# 服务器端链接超时时间为15秒则HA 发起重连机制
timeout server 15000
listen rabbitmq_cluster
# VIP,反向代理到下面定义的三台Real Server
bind 192.168.100.101:5672
#配置TCP模式 mode tcp
#简单的轮询 balance roundrobin
# rabbitmq集群节点配置
# inter 每隔五秒对mq集群做健康检查,2次正确证明服务器可用,2次失败证明服务器不可用, 并且配置主备机制
server rabbitmqNode1 192.168.100.102:5672 check inter 5000 rise 2 fall 2
server rabbitmqNode2 192.168.100.103:5672 check inter 5000 rise 2 fall 2
server rabbitmqNode3 192.168.100.104:5672 check inter 5000 rise 2 fall 2
#配置haproxy web监控,查看统计信息
listen stats bind 192.168.100.101:9000
mode http
option httplog
# 启用基于程序编译时默认设置的统计报告
stats enable
#设置haproxy监控地址为http://node1:9000/rabbitmq-stats
stats uri /rabbitmq-stats
# 每5s刷新一次页面
stats refresh 5s
启动:
haproxy -f /etc/haproxy/haproxy.cfg
代码接入haproxy:
与正常访问没有区别;
rabbit监控平台:
prometheus监控平台,redis、rabbit都支持.grafana页面美观
源码相关:
idea安装erlang插件

















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









