






 本文详细介绍了Mysql的各个存储引擎,包括InnoDB、MyISAM、MRG_MyISAM、Memory、Blackhole和Archive的特点,以及它们在不同场景下的适用性。InnoDB支持事务和行级锁,适合高并发写操作;MyISAM强调快速读取,适合读多写少的场景。此外,还进行了存储引擎的性能测试,结果显示在SSD上,某些引擎的性能表现可能与预期不同。
本文详细介绍了Mysql的各个存储引擎,包括InnoDB、MyISAM、MRG_MyISAM、Memory、Blackhole和Archive的特点,以及它们在不同场景下的适用性。InnoDB支持事务和行级锁,适合高并发写操作;MyISAM强调快速读取,适合读多写少的场景。此外,还进行了存储引擎的性能测试,结果显示在SSD上,某些引擎的性能表现可能与预期不同。
Mysql为什么要分很多引擎:
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
引擎是真对于表的,在创建表的时候可以直接指定使用的引擎,例如:
也可以通过配置文件里直接修改默认引擎:
加上这条(然后重启服务)
default-storage-engine=InnoDB
之后可以通过 show create table 表名 来查询表使用的引擎
如果本地是docker的话,一件部署安装mysql可以直接用下面命令
docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d -v /tmp/mysqldata/:/var/lib/mysql/ mysql
登陆mysql查看本地支持的引擎:
SHOW ENGINES;
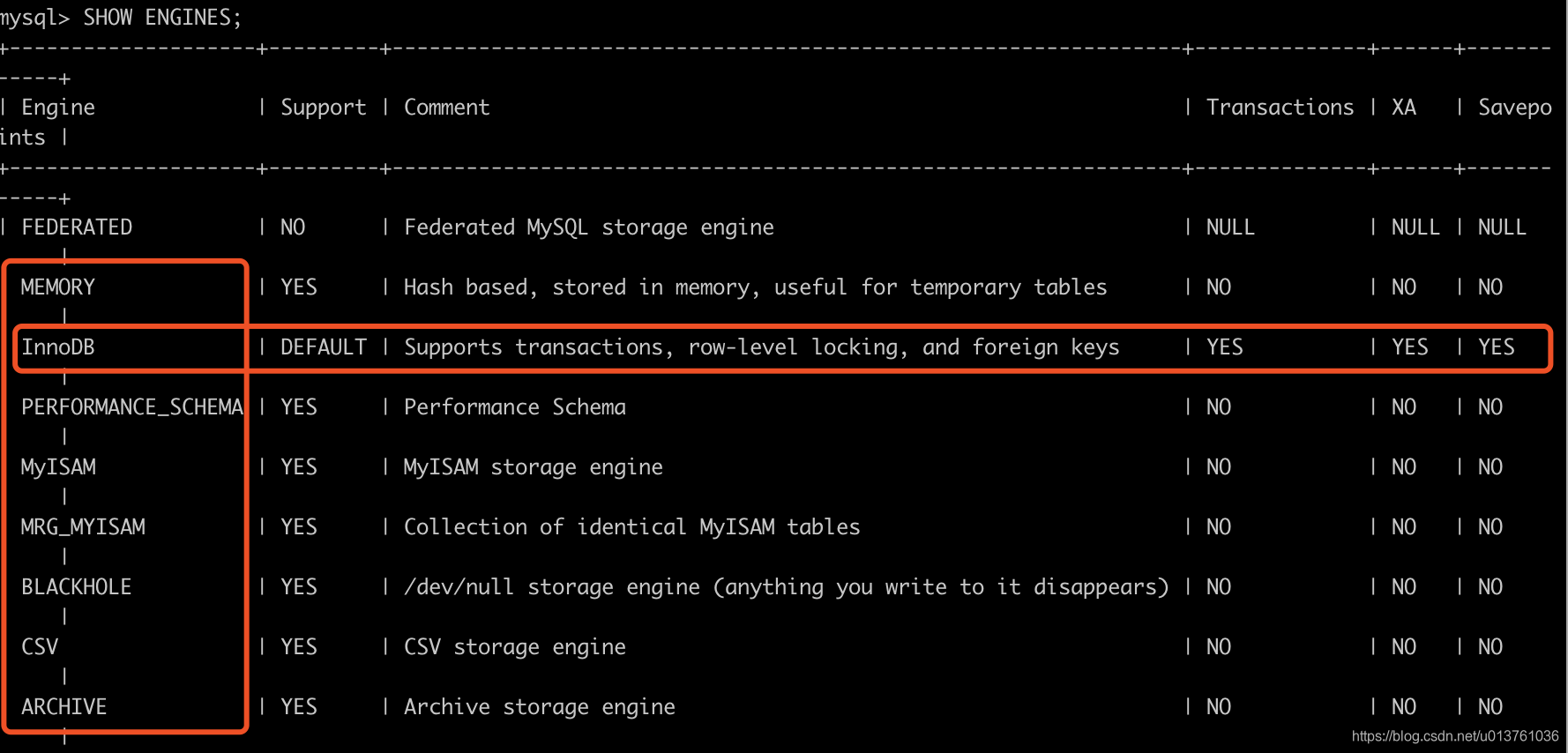
1.InnoDB默认引擎
Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别,关于数据库事务与其隔离级别的内容请见数据库事务与其隔离级别这类型的文章。该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于MySQL后台的完整数据库系统,MySQL运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当SELECT COUNT(*) FROM TABLE时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表,InnoDB给MySQL提供了具有提交、回滚和崩溃恢复能力的事务安全(ACID兼容)存储引擎。
原理:
是B+Treee索引结构。Innodb的索引文件本身就是数据文件,即B+Tree的数据域存储的就是实际的数据,这种索引就是聚集索引。这个索引的key就是数据表的主键,因此InnoDB表数据文件本身就是主索引。InnoDB的辅助索引数据域存储的也是相应记录主键的值而不是地址,所以当以辅助索引查找时,会先根据辅助索引找到主键,再根据主键索引找到实际的数据。所以Innodb不建议使用过长的主键,否则会使辅助索引变得过大。建议使用自增的字段作为主键,这样B+Tree的每一个结点都会被顺序的填满,而不会频繁的分裂调整,会有效的提升插入数据的效率。
2.MyIsam引擎
不支持事务的设计,但是并不代表着有事务操作的项目不能用MyIsam存储引擎,可以在service层进行根据自己的业务需求进行相应的控制,不支持外键的表设计,查询速度很快,如果是多查询,少修改的情况下建议使用,MyISAM极度强调快速读取操作,MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。不能在表损坏后恢复数据。(是不能主动恢复)
原理:
MyISAM索引结构: MyISAM索引用的B+ tree来储存数据,MyISAM索引的指针指向的是键值的地址,地址存储的是数据。B+Tree的数据域存储的内容为实际数据的地址,也就是说它的索引和实际的数据是分开的,只不过是用索引指向了实际的数据,这种索引就是所谓的非聚集索引。
3.Mrg_Myisam引擎
是一个相同的可以被当作一个来用的MyISAM表的集合。“相同”意味着所有表同样的列和索引信息。他将MyIsam引擎的多个表聚合起来,但是他的内部没有数据,真正的数据依然是MyIsam引擎的表中,但是可以直接进行查询、删除更新等操作。
测试代码如下(创建两个user表,然后聚合一下)
CREATE TABLE IF NOT EXISTS user1 (
id int(11) NOT NULL ,
name varchar(50) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
CREATE TABLE IF NOT EXISTS user2 (
id int(11) NOT NULL ,
name varchar(50) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
INSERT INTO user1 (id,name) VALUES(1,'00000');
INSERT INTO user2 (id,name) VALUES(1,'xxxxx');
CREATE TABLE IF NOT EXISTS alluser (
id int(11) NOT NULL ,
name varchar(50) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=MRG_MYISAM
DEFAULT CHARSET=utf8
UNION=(user1,user2) ;
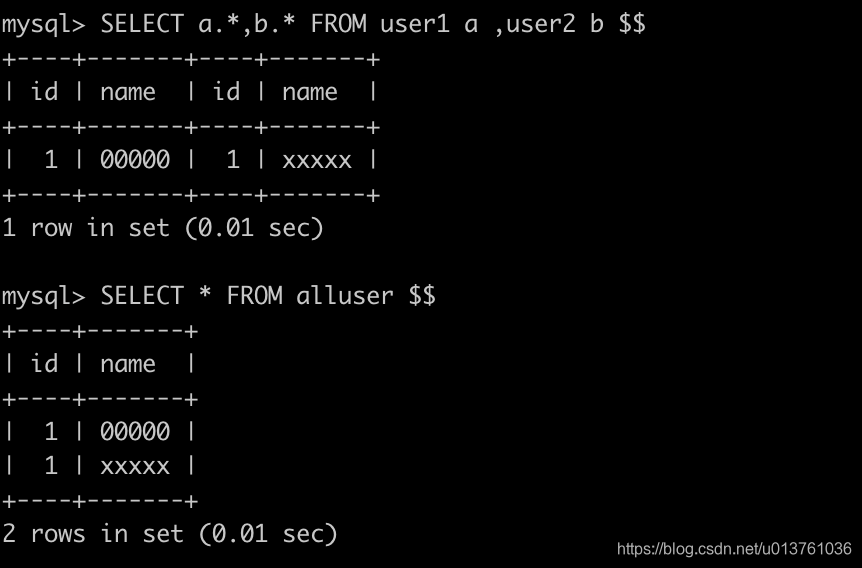
SELECT a.*,b.* FROM user1 a ,user2 b;
SELECT * FROM alluser;
4.Memory引擎
所有的数据都是跑在内存里,适合场景是中间数据缓存的情况,读写速度很高。最后性能测试里面有这个。
5.Blackhole引擎
任何写入到此引擎的数据均会被丢弃掉, 不做实际存储;Select语句的内容永远是空。
他会丢弃所有的插入的数据,服务器会记录下Blackhole表的日志,所以可以用于复制数据到备份数据库。
使用场景:
1)验证dump file语法的正确性
2)以使用blackhole引擎来检测binlog功能所需要的额外负载
3)充当日志服务器
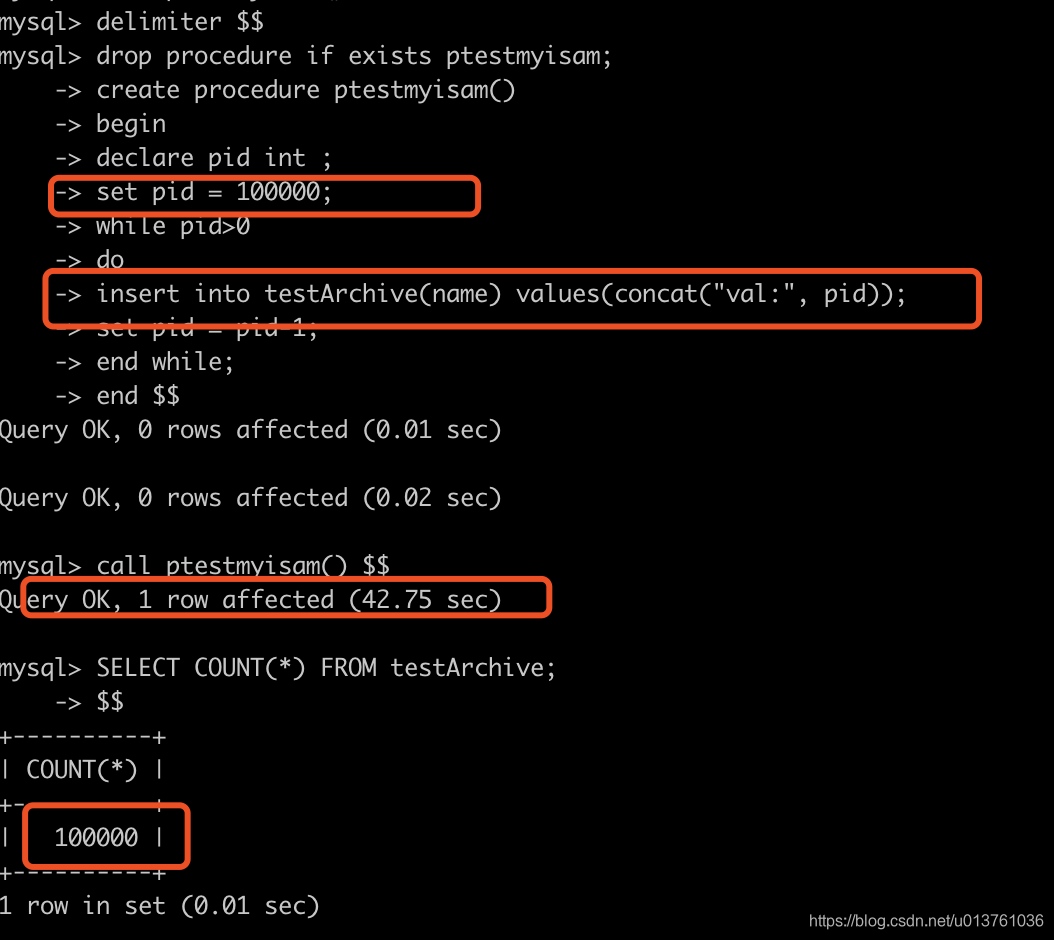
6.Archive引擎
以zlib对表数据进行压缩,磁盘I/O更少,数据存储在ARZ为后缀的文件中。只支持insert和select操作(支持行级所和缓冲区,可以实现高并发的插入)
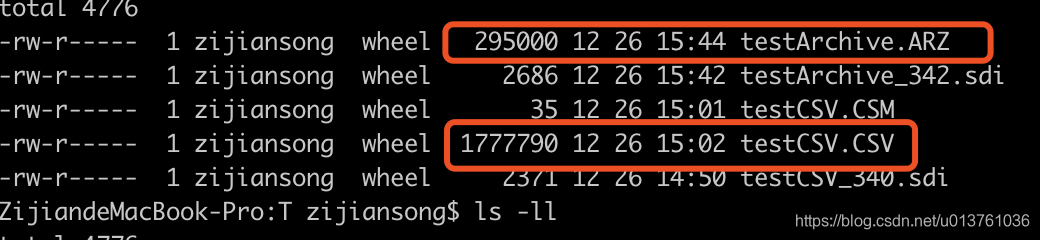
只允许在自增ID列上加索引。Archive表比MyISAM表要小大约75%,比支持事务处理的InnoDB表小大约83%。当数据量非常大的时候Archive的插入性能表现会较MyISAM为佳。下面是速度测试
同样数量级10W,生成的数据库文件大小比较(跟CSV引擎对比)
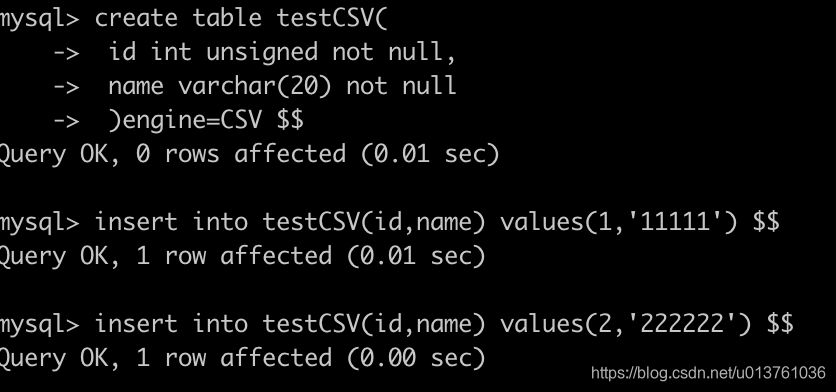
7.CSV引擎
最大亮点,用CSV类型的文件进行存储。
直接上操作
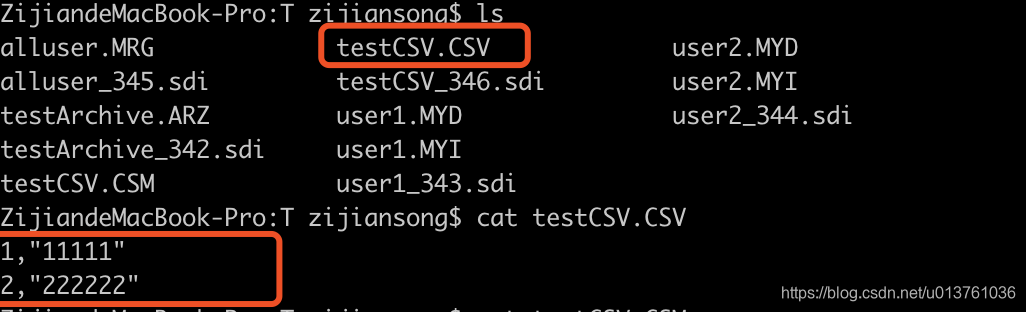
然后去找本地数据库文件看下:
最后对如上7个引擎中的六个进行了同环境下的性能测试(insert),用于对比实际情况下不同引擎的insert操作性能对比,可能结果跟想象的不一样。
我是在相同配置环境下操作的,操作数据10W,但是注意,我磁盘是SDD.

为什么会产生上面那样的数据?我的理解是,很多引擎的针对不同情况的优化都是针对磁盘的,这个磁盘是机械硬盘,主要处理频繁随机读写导致的磁盘寻道。但是SSD上并不存在寻道的概念,这回让很多算法展示出尴尬的一面,甚至导致因为操作过于高端(去处理寻道问题),导致反而浪费了很多时间。
下面附上面提到的所有相关代码(包括压力测试):
----InnoDB性能测试相关-----
create table testInnoDB(
id int unsigned primary key auto_increment,
name varchar(20) not null
)engine=innodb ;
delimiter $$
drop procedure if exists ptestmyisam;
create procedure ptestmyisam()
begin
declare pid int ;
set pid = 100000;
while pid>0
do
insert into testInnoDB(name) values(concat("val:", pid));
set pid = pid-1;
end while;
end $$
call ptestmyisam() $$
delimiter ;
----MyIsam性能测试相关-----
create testMyIsam(
id int unsigned primary key auto_increment,
name varchar(20) not null
)engine=myisam ;
delimiter $$
drop procedure if exists ptestmyisam;
create procedure ptestmyisam()
begin
declare pid int ;
set pid = 100000;
while pid>0
do
insert into testMyIsam(name) values(concat("val:", pid));
set pid = pid-1;
end while;
end $$
call ptestmyisam() $$
delimiter ;
----Memory性能测试相关-----
create table testMemory(
id int unsigned primary key auto_increment,
name varchar(20) not null
)engine=memory ;
delimiter $$
drop procedure if exists ptestmyisam;
create procedure ptestmyisam()
begin
declare pid int ;
set pid = 100000;
while pid>0
do
insert into testMemory(name) values(concat("val:", pid));
set pid = pid-1;
end while;
end $$
call ptestmyisam() $$
delimiter ;
----Blackhole性能测试相关-----
create table testBlackhole(
id int unsigned primary key auto_increment,
name varchar(20) not null
)engine=blackhole ;
delimiter $$
drop procedure if exists ptestmyisam;
create procedure ptestmyisam()
begin
declare pid int ;
set pid = 100000;
while pid>0
do
insert into testBlackhole(name) values(concat("val:", pid));
set pid = pid-1;
end while;
end $$
call ptestmyisam() $$
delimiter ;
----CSV性能测试相关-----
create table testCSV(
id int unsigned not null,
name varchar(20) not null
)engine=CSV ;
delimiter $$
drop procedure if exists ptestmyisam;
create procedure ptestmyisam()
begin
declare pid int ;
set pid = 100000;
while pid>0
do
insert into testCSV(id,name) values(pid,concat("val:", pid));
set pid = pid-1;
end while;
end $$
call ptestmyisam() $$
delimiter ;
----Archive性能测试相关-----
create table testArchive(
id int unsigned primary key auto_increment,
name varchar(20) not null
)engine=Archive ;
delimiter $$
drop procedure if exists ptestmyisam;
create procedure ptestmyisam()
begin
declare pid int ;
set pid = 100000;
while pid>0
do
insert into testArchive(name) values(concat("val:", pid));
set pid = pid-1;
end while;
end $$
call ptestmyisam() $$
delimiter ;
----Mrg_Myisam相关-----
CREATE TABLE IF NOT EXISTS user1 (
id int(11) NOT NULL ,
name varchar(50) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
CREATE TABLE IF NOT EXISTS user2 (
id int(11) NOT NULL ,
name varchar(50) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
INSERT INTO user1 (id,name) VALUES(1,'00000');
INSERT INTO user2 (id,name) VALUES(1,'xxxxx');
CREATE TABLE IF NOT EXISTS alluser (
id int(11) NOT NULL ,
name varchar(50) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=MRG_MYISAM
DEFAULT CHARSET=utf8
UNION=(user1,user2) ;
SELECT a.*,b.* FROM user1 a ,user2 b;
SELECT * FROM alluser;

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









