






Spark实例的创建和使用
安装Spark:
解压Spark安装包:tar -zxf /home/sdbadmin/soft/spark-2.4.4-bin-hadoop2.7.tar.gz -C /opt
添加驱动包:
拷贝 SequoiaDB for Spark 的连接器到 Spark 的 jars 目录下:cp /opt/sequoiadb/spark/spark-sequoiadb_2.11-3.4.jar /opt/spark-2.4.4-bin-hadoop2.7/jars/
拷贝 MySQL 驱动到 Spark 的 jars 目录下: cp /home/sdbadmin/soft/mysql-jdbc.jar /opt/spark-2.4.4-bin-hadoop2.7/jars/
拷贝 SequoiaDB 的 JAVA 驱动到 Spark 的 jars 目录下: cp /opt/sequoiadb/java/sequoiadb-driver-3.4.jar /opt/spark-2.4.4-bin-hadoop2.7/jars/
设置免密:
执行 ssh-keygen 生成公钥和密钥,执行后连续回车即可: ssh-keygen -t rsa
执行 ssh-copy-id,把公钥拷贝到本机的 sdbadmin 用户:ssh-copy-id sdbadmin@sdbserver1
配置Spark
设置 spark-env.sh:
从模板中复制一份 spark-env.sh 脚本:cp /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh.template /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh
在 spark-env.sh 中设置 WORKER 的数量和 MASTER 的 IP:
echo "SPARK_WORKER_INSTANCES=2" >> /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh
echo "SPARK_MASTER_IP=127.0.0.1" >> /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh
复制以下代码到实验环境终端执行,用于创建设置元数据信息的数据库配置文件 hive-site.xml:
cat > /opt/spark-2.4.4-bin-hadoop2.7/conf/hive-site.xml << EOF
<configuration>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>metauser</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>metauser</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
<description>creates necessary schema on a startup if one doesn't exist. set this to false, after creating it once</description>
</property>
</configuration>
EOF
配置Spark元数据库:
使用 Linux 命令进入 MySQL Shell:/opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root
创建metauser用户:CREATE USER 'metauser'@'%' IDENTIFIED BY 'metauser';
给 metauser 用户授权: GRANT ALL ON *.* TO 'metauser'@'%';
创建 Spark 元数据库: CREATE DATABASE metastore CHARACTER SET 'latin1' COLLATE 'latin1_bin';
刷新权限:FLUSH PRIVILEGES;
启动Spark服务:
启动 Spark: /opt/spark-2.4.4-bin-hadoop2.7/sbin/start-all.sh
启动 thriftserver 服务: /opt/spark-2.4.4-bin-hadoop2.7/sbin/start-thriftserver.sh
检查进程启动状态: jps
检查端口监听状态: netstat -anp | grep 10000
在 SequoiaDB 建立集合空间和集合:
创建 company_domain 逻辑域: db.createDomain("company_domain", [ "group1", "group2", "group3" ], { AutoSplit: true } );
创建 company 集合空间: db.createCS("company", { Domain: "company_domain" } );
创建 employee 集合: db.company.createCL("employee", { "ShardingKey": { "_id": 1 }, "ShardingType": "hash", "ReplSize": -1, "Compressed": true, "CompressionType": "lzw", "AutoSplit": true, "EnsureShardingIndex": false } );
SparkSQL与SequoiaDB的集合空间和集合关联:
使用 Beeline 客户端工具连接至 thriftserver 服务:/opt/spark-2.4.4-bin-hadoop2.7/bin/beeline -u 'jdbc:hive2://localhost:10000'
创建并切换至 company 数据库: create database company; use company;
创建 employee 表,并且与 SequoiaDB 中的集合 employee 进行关联:
CREATE TABLE employee
(
empno INT,
ename STRING,
age INT
)
USING com.sequoiadb.spark OPTIONS
(
host 'localhost:11810',
collectionspace 'company',
collection 'employee'
);
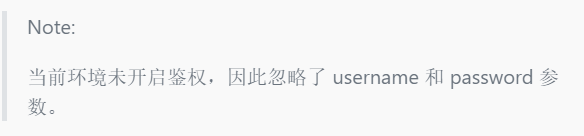
在 SparkSQL 中关联 SequoiaDB 集合空间和集合的 SQL 语法如下:
CREATE <[TEMPORARY] TABLE | TEMPORARY VIEW> <tableName> [(SCHEMA)]
USING com.sequoiadb.spark OPTIONS (<option>, <option>, ...);


在Beeline中进行数据操作:
写入数据:
INSERT INTO employee VALUES ( 10001, 'Georgi', 48 );
INSERT INTO employee VALUES ( 10002, 'Bezalel', 21 );
INSERT INTO employee VALUES ( 10003, 'Parto', 33 );
INSERT INTO employee VALUES ( 10004, 'Chirstian', 40 );
通过连接器自动生成 SCHEMA 来创建 employee_auto_schema 表:
CREATE TABLE employee_auto_schema USING com.sequoiadb.spark OPTIONS
(
host 'localhost:11810',
collectionspace 'company',
collection 'employee'
);

通过 SQL 结果集创建表:
通过已有表 employee 创建表 employee_bak,并将表中的数据存放到指定域和集合空间中:
CREATE TABLE employee_bak USING com.sequoiadb.spark OPTIONS
(
host 'localhost:11810',
domain 'company_domain',
collectionspace 'company',
collection 'employee_bak',
autosplit true,
shardingkey '{_id:1}',
shardingtype 'hash',
compressiontype 'lzw'
) AS SELECT * FROM employee;
退出 Beeline Shell: !quit
图形化报表工具对接:
解压 Pentaho 安装包:unzip -q /home/sdbadmin/pentaho-server-ce-7.0.0.0-25.zip -d /opt
Pentaho 对接 SequoiaDB + SparkSQL:
Pentaho 在默认情况下,并不能直接和 SparkSQL 进行通信,但是它支持 Hadoop Hive2 的 JDBC 访问接口,将相关的开发驱动拷贝到 Pentaho 的指定目录即可使用。
配置 SparkSQL 驱动:
将 SparkSQL 的开发驱动拷贝一份到 Pentaho 解压目录下的 tomcat\lib 目录中:
cp /opt/spark/jars/hadoop-common-2.7.3.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/hive-exec-1.2.1.spark2.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/hive-jdbc-1.2.1.spark2.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/hive-metastore-1.2.1.spark2.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/httpclient-4.5.6.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/httpcore-4.4.10.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/libthrift-0.9.3.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/log4j-1.2.17.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/slf4j-api-1.7.16.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/slf4j-log4j12-1.7.16.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/spark-hive-thriftserver_2.11-2.4.5.jar /opt/pentaho-server/tomcat/lib/
cp /opt/spark/jars/spark-network-common_2.11-2.4.5.jar /opt/pentaho-server/tomcat/lib/
修改 Pentaho 配置:
Pentaho 依赖 Tomcat 提供服务,默认端口号为 8080,与 SparkSQL 服务页面端口冲突,因此需要修改端口号,这里修改为 8180: sed -i 's/<Connector URIEncoding="UTF-8" port="8080"/<Connector URIEncoding="UTF-8" port="8180"/g' /opt/pentaho-server/tomcat/conf/server.xml
配置好 Pentaho 后,用户只需要启动 Pentaho 即可正常使用: /opt/pentaho-server/start-pentaho.sh
Spark服务启动:
启动Spark服务:
启动 Spark: /opt/spark-2.4.4-bin-hadoop2.7/sbin/start-all.sh
启动 thriftserver 服务: /opt/spark-2.4.4-bin-hadoop2.7/sbin/start-thriftserver.sh
检查进程启动状态: jps
检查端口监听状态: netstat -anp | grep 10000
在SparkSQL中创建数据库:
登录 Beeline 客户端连接 SparkSQL 实例:/opt/spark/bin/beeline -u 'jdbc:hive2://localhost:10000'
在 SparkSQL 中创建 company 数据库,用于连接测试: CREATE DATABASE company;
退出Beeline客户端:!quit
制作一个简单的折线图:
创建 company_domain 逻辑域: db.createDomain("company_domain", [ "group1", "group2", "group3" ], { AutoSplit: true } );
创建 company 集合空间: db.createCS("company", { Domain: "company_domain" } );
创建 employee 集合: db.company.createCL("employee", { "ShardingKey": { "_id": 1 }, "ShardingType": "hash", "ReplSize": -1, "Compressed": true, "CompressionType": "lzw", "AutoSplit": true, "EnsureShardingIndex": false } );
登录Beeline客户端连接SparkSQL实例:/opt/spark/bin/beeline -u 'jdbc:hive2://localhost:10000'
创建 employee 表,并且与 SequoiaDB 中的集合 company.employee 进行关联:
CREATE TABLE company.employee
(
empno INT,
ename STRING,
age INT
)
USING com.sequoiadb.spark OPTIONS
(
host 'localhost:11810',
collectionspace 'company',
collection 'employee'
);
像employee表中插入数据:
INSERT INTO company.employee VALUES
( 10001, 'Georgi', 48 ),
( 10002, 'Bezalel', 21 ),
( 10003, 'Parto', 33 ),
( 10004, 'Chirstian', 40 ),
( 10005, 'Kyoichi', 23 ),
( 10006, 'Anneke', 19 ),
( 10007, 'Ileana', 28 ),
( 10008, 'Liz', 38 ),
( 10009, 'Parish', 31 ),
( 10010, 'Odette', 23 );
统计口径展示
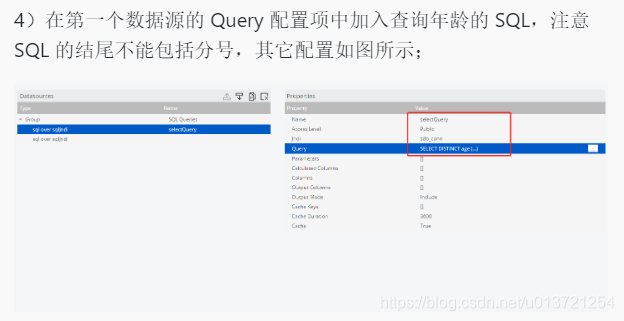
查询所有人员的年龄作为纵坐标: SELECT DISTINCT age FROM company.employee ORDER BY age
查询所有人员的名字、年龄数据,并将名字作为横坐标: SELECT ename, age FROM company.employee ORDER BY empno
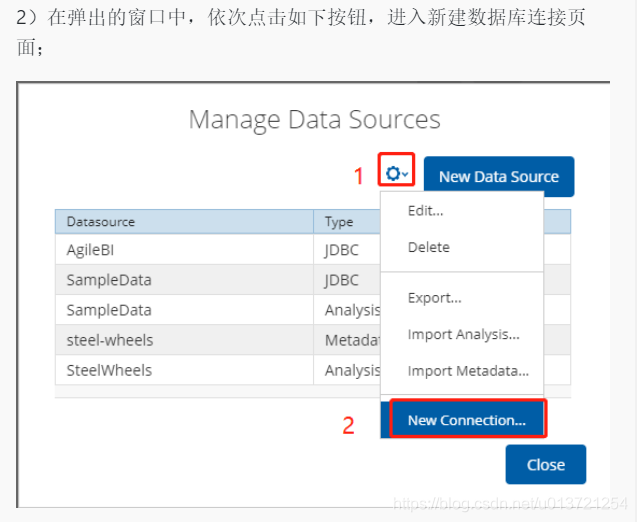
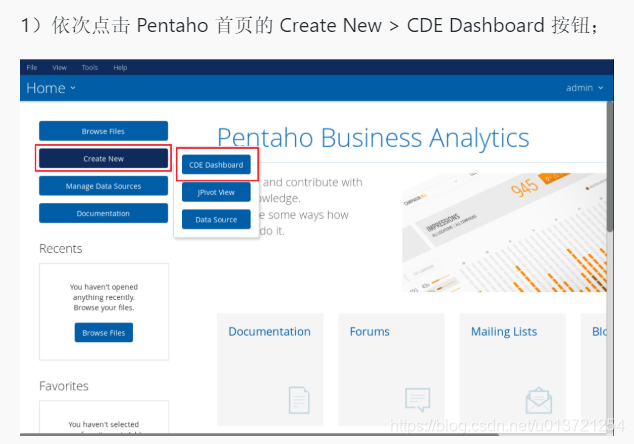
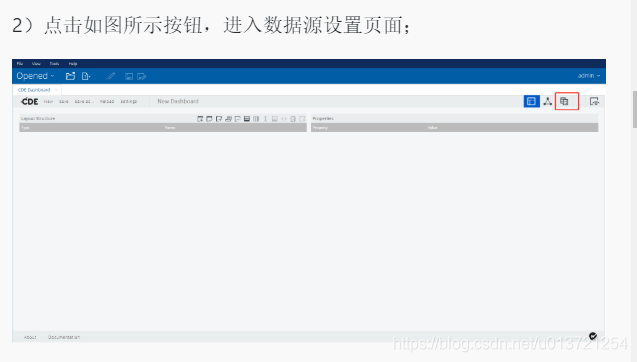
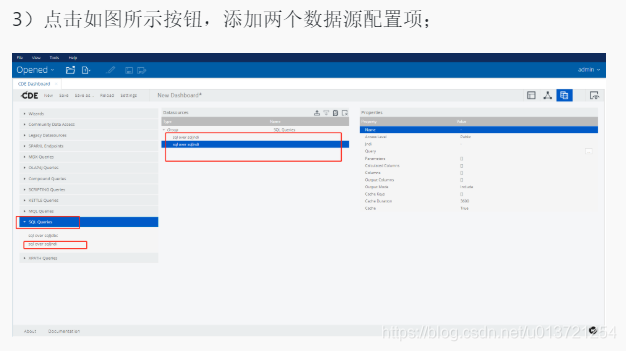
创建数据源:
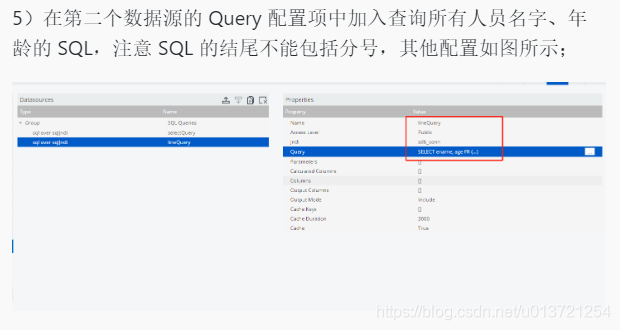
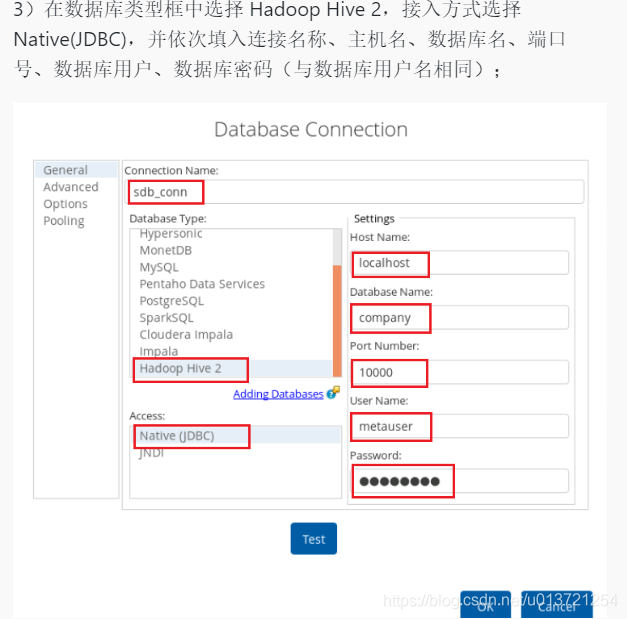
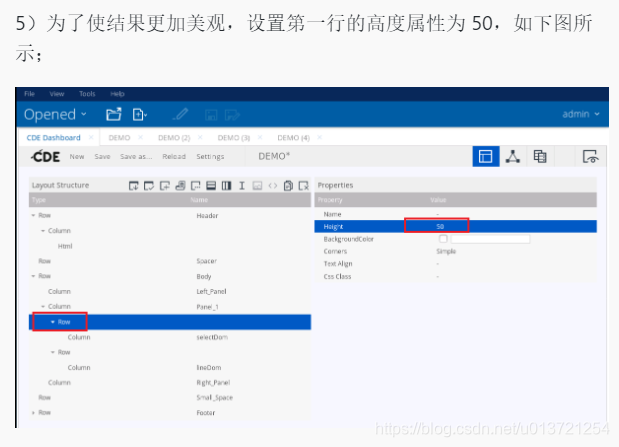
 调整布局:
调整布局:
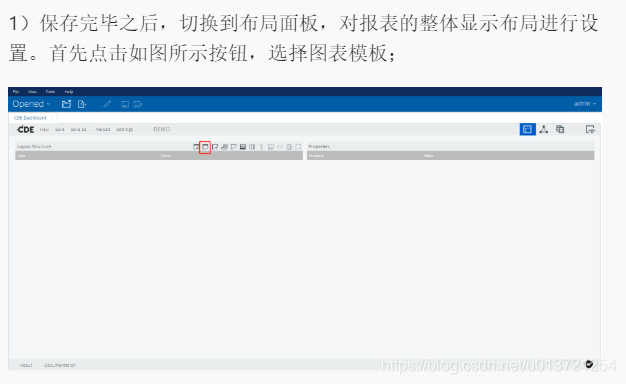
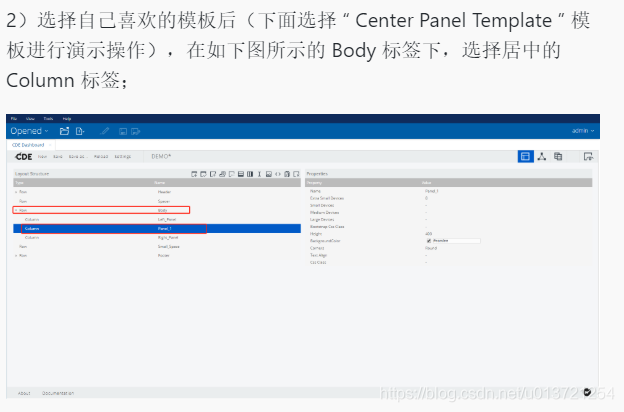
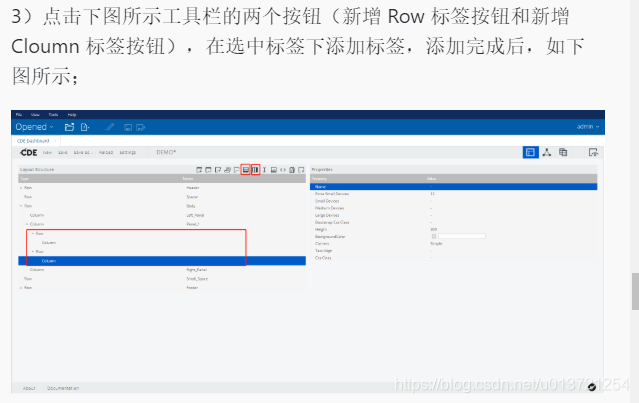
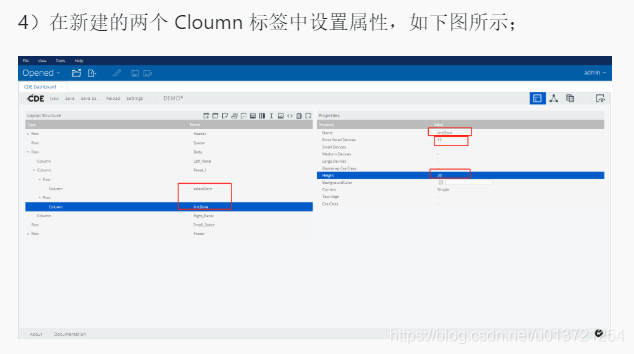
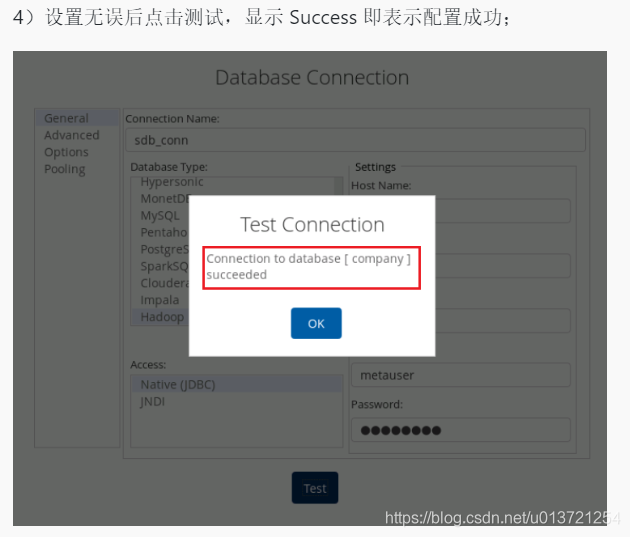
 添加组件:
添加组件:
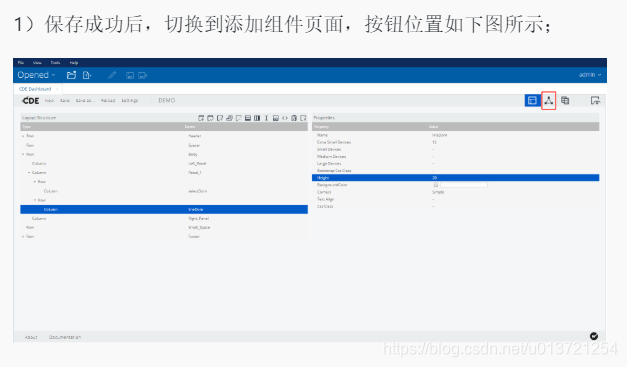
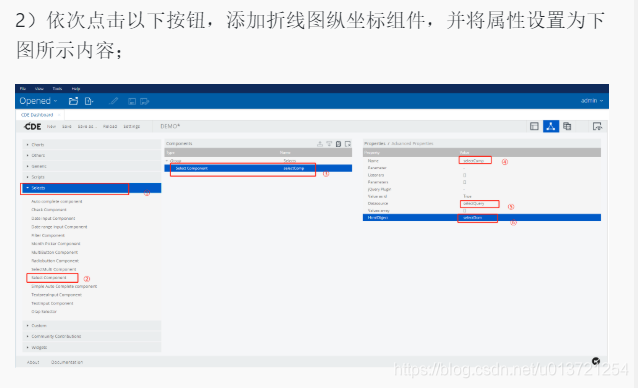
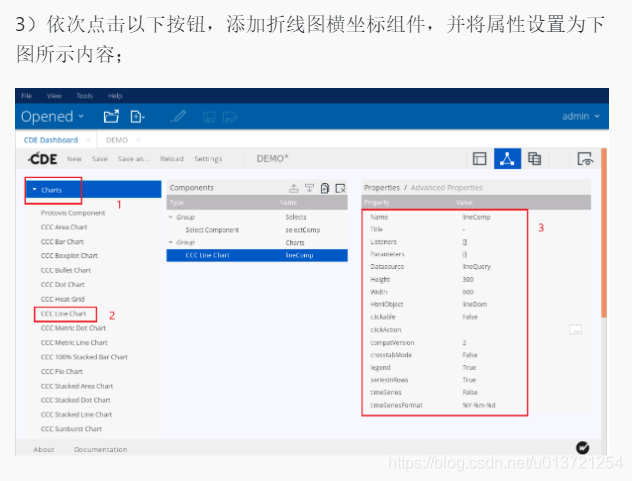
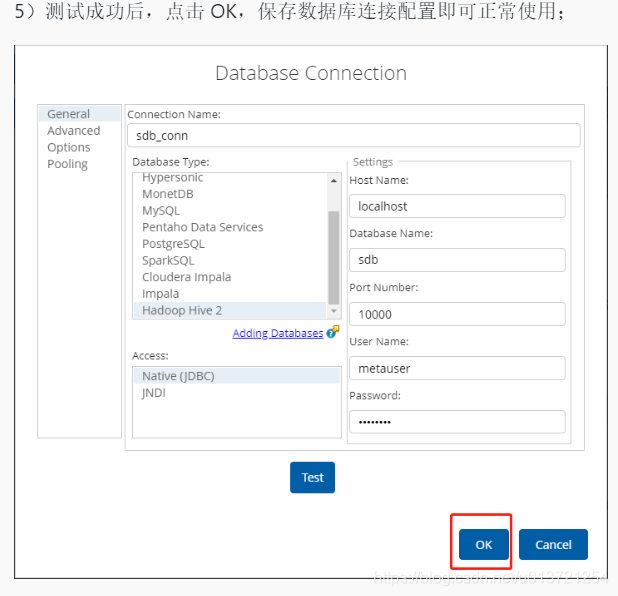
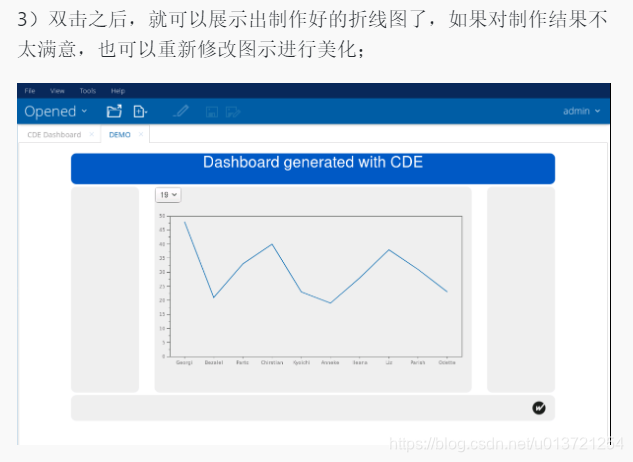
查看折线图:
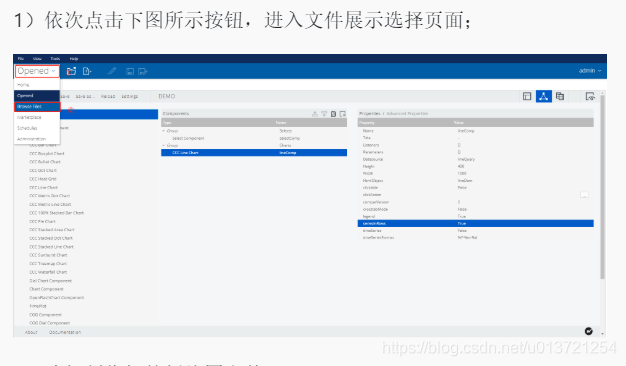
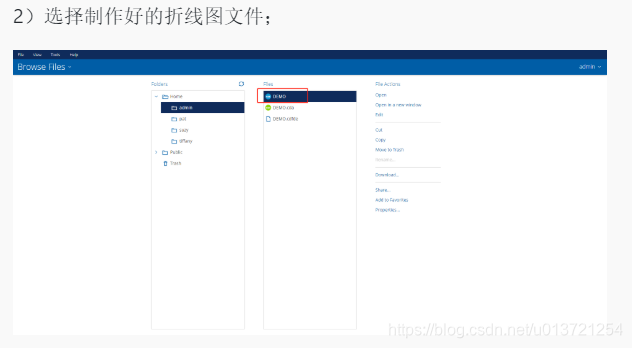
对在线联机业务零干扰进行后台统计分析
初始化数据:
连接SQL:/opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root
创建company数据库:create database company;
切换到company数据库:use company;
创建 employee 表,将同步在 SequoiaDB 巨杉数据引擎中创建分区表:
CREATE TABLE employee
(
empno INT AUTO_INCREMENT PRIMARY KEY,
ename VARCHAR(128),
age INT
);
向 employee 表中写入数据:
INSERT INTO employee VALUES
( 10001, 'Georgi', 48 ),
( 10002, 'Bezalel', 21 ),
( 10003, 'Parto', 33 ),
( 10004, 'Chirstian', 40 ),
( 10005, 'Kyoichi', 23 ),
( 10006, 'Anneke', 19 ),
( 10007, 'Ileana', 28 ),
( 10008, 'Liz', 38 ),
( 10009, 'Parish', 31 ),
( 10010, 'Odette', 23 );
查看当前集群中的协调节点: sdblist -l | grep -E "Name|coord"
查看 MySQL 实例使用的协调节点: /opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P 3306 -u root -e "SHOW VARIABLES LIKE 'sequoiadb_conn%';"
在SparkSQL中建表:
查看 Spark 的 Worker 和 Master 是否已经启动:jps
登录 Beeline 连接到 SparkSQL 实例:/opt/spark/bin/beeline -u 'jdbc:hive2://localhost:10000'
创建并切换至 company 数据库: CREATE DATABASE company;USE company;
创建 employee 表,并且与 SequoiaDB 中的集合 company.employee 进行关联:
CREATE TABLE employee
(
empno INT,
ename STRING,
age INT
)
USING com.sequoiadb.spark OPTIONS
(
host 'localhost:21810',
collectionspace 'company',
collection 'employee',
preferredinstance 'S',
preferredinstancemode 'random',
preferredinstancestrict true
);
 验证联机业务与统计分析的相互隔离:
验证联机业务与统计分析的相互隔离:
用嵌入命令模式连接 SequoiaDB 巨杉数据库协调节点: sdb 'db = new Sdb("localhost", 11810)'
使用 snapshot ( SDB_LIST_COLLECTIONS ) 查询集合 company.employee 在数据组 group1 各数据节点的数据读取量:
sdb 'db.snapshot( SDB_LIST_COLLECTIONS , { Name: "company.employee" } )' | grep -E "NodeName|TotalDataRead|GroupName"
执行计划分析
创建 company_domain 逻辑域: db.createDomain("company_domain", [ "group1", "group2", "group3" ], { AutoSplit: true } );
创建 company 集合空间: db.createCS("company", { Domain: "company_domain" } );
创建 employee 集合: db.company.createCL("employee", { "ShardingKey": { "_id": 1 }, "ShardingType": "hash", "ReplSize": -1, "Compressed": true, "CompressionType": "lzw", "AutoSplit": true, "EnsureShardingIndex": false } );
使用 Beeline 客户端工具连接至 thriftserver 服务:/opt/spark-2.4.4-bin-hadoop2.7/bin/beeline -u 'jdbc:hive2://localhost:10000'
创建并切换至 company 数据库: create database company; use company;
创建 employee 表,并且与 SequoiaDB 中的集合 employee 进行关联:
CREATE TABLE employee
(
empno INT,
ename STRING,
age INT
)
USING com.sequoiadb.spark OPTIONS
(
host 'localhost:11810',
collectionspace 'company',
collection 'employee'
);
在 SparkSQL 中插入数据:
INSERT INTO employee VALUES ( 10001, 'Georgi', 48 );
INSERT INTO employee VALUES ( 10002, 'Bezalel', 21 );
INSERT INTO employee VALUES ( 10003, 'Parto', 33 );
INSERT INTO employee VALUES ( 10004, 'Chirstian', 40 );

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









