




 探讨了使用LSTM搭建的问答机器人在处理未见过的输入时出现语法错误的原因,并提出解决方案,包括限定问答范围、关键词提取及改进输出策略。
探讨了使用LSTM搭建的问答机器人在处理未见过的输入时出现语法错误的原因,并提出解决方案,包括限定问答范围、关键词提取及改进输出策略。
>存在的问题
使用LSTM搭建问答(QA)机器人,训练语料集2000组对话,训练了300轮,测试精准度为98%。模型方框图如下:
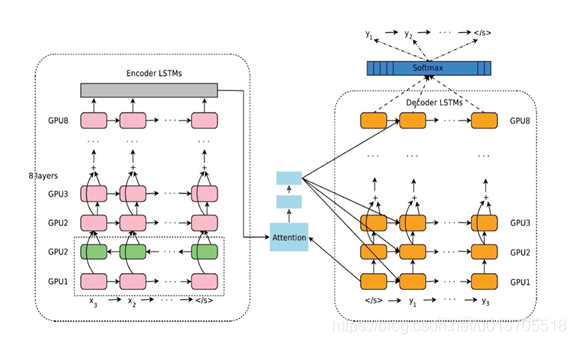
实测聊天发现,当输入的问题与训练集中一样时,模型输出很好,当输入与训练集有点差异,比如删除一部分,模型输出存在明显的语法错误,如下图所示。


>原因分析
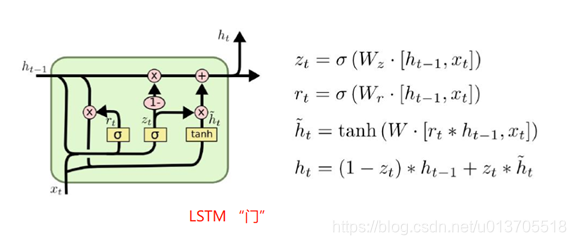
LSTM网络本质是在输入与输出之间建立映射关系,训练时通过迭代找到合适的长短记忆“门”权重,把输入映射到输出,当模型训练好了,LSTM网络的Wz,Wr,W权重就会固定下来,预测时把输入与权重进行线性计算,再经过激活函数计算,得到输出,相当于把输入经过计算映射到输出。注意,对于语料集所有的提问的embedding字符,任意的排列组合,都是LSTM网络的合法输入,经过计算,都会有一个映射输出。不幸的是,训练语料集的对话组是众多合法输入排列组合中的一个,而且仅仅是训练语料集的对话组才有意义,其他的排列组合输入的映射输出是没有意义的,会有明显的语法错误。比如对话组提问:“光驱读不出空盘读得出已写的光盘怎么回事”,回答:“你的光驱可以刻录吗?如果不可以的话就不能读”,合法的提问输入有很多,“光驱读不出空盘读得出已写的光盘”、 “光驱读不出空盘”、“空盘读不出 已写的光盘读得出 怎么回事”、“回事怎么读得出已写的光盘光驱读不出空盘”等非常多的符合语法或不符合语法的排列组合,都是LSTM网络的合法输入,对于LSTM网络来说,这些输入是不同的输入,会映射到不同的输出,显然,这些输入/输出组是没有经过训练的,不能指望它们刚好是有意义的,符合语法的。
>解决方法
对于问答机器人,语义上有2条基本要求,首先要符合自然语言的语法,其次要符合逻辑,不要答非所问。要满足这两条要求,一种方法是把问答的范围局限在训练语料集范畴,对于超出训练语料集的提问,做规则处理,返回固定的提示语句。当然,对于超出训练语料集的用户提问,更好的处理方法是,提取用户提问的关键词,输入到提问模块,得到提问语句,输出给用户,与用户进行交互,本文主要是阐述输出语法错误的解决方法,该方法在这里不做展开。把问答的范围局限在训练语料集范畴,相应的,问答机器人的覆盖范围受到训练语料集限制,这个限制可以通过扩展语料集对话数目解决。为了让LSTM网络输出限制在训练语料集范畴,需要做2点改进。首先,语料集中的回答语句整句做one-hot编码,不再划分字、词,这样LSTM网络输出必然是语料集中完整的语句,不会有语法错误。其次,把预测输出的语句与输入的用户提问语句组成一组对话,计算置信度,通过置信度判断用户提问是否在训练语料集范畴(详见另一篇博文《一种评估LSTM模型置信度方法》)。
>语料集回答语句整句编码python代码
class WordSequenceDecode(object):
PAD_TAG = '<pad>'
UNK_TAG = '<unk>'
START_TAG = '<s>'
END_TAG = '</s>'
PAD = 0
UNK = 1
START = 2
END = 3
def __init__(self):
self.dict = {
WordSequenceDecode.PAD_TAG: WordSequenceDecode.PAD,
WordSequenceDecode.UNK_TAG: WordSequenceDecode.UNK,
WordSequenceDecode.START_TAG: WordSequenceDecode.START,
WordSequenceDecode.END_TAG: WordSequenceDecode.END
}
self.fited = False
def to_index(self, word):
assert self.fited, "WordSequenceDecode 尚未进行 fit 操作"
if word in self.dict:
return self.dict[word]
return WordSequenceDecode.UNK
def to_word(self, index):
assert self.fited, "WordSequenceDecode 尚未进行 fit 操作"
for k, v in self.dict.items():
if v == index:
return k
return WordSequenceDecode.UNK_TAG
def size(self):
assert self.fited, "WordSequenceDecode 尚未进行 fit 操作"
return len(self.dict) + 1
def __len__(self):
return self.size()
def fit(self, sentences):
assert not self.fited, 'WordSequenceDecode 只能fit一次'
sentence_set = set()
for sentence in sentences:
arr = ''.join(sentence)
sentence_set.add(arr)
for sent in sentence_set:
self.dict[sent] = len(self.dict)
print("word sequence decode size:", len(self.dict))
self.fited = True
def transform(self, sentence, max_len=None):
assert self.fited, "WordSequenceDecode 尚未进行 fit 操作"
r = []
r.append(self.to_index(''.join(sentence)))
r.append(WordSequenceDecode.PAD)
return np.array(r)
def inverse_transform(self, indices,ignore_pad=True,
ignore_unk=True,ignore_start=True, igonre_end=True):
word = self.to_word(indices[0])
return word

















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









