










Ref
续接上一篇
文本介绍Model Executor的创建过程。
文中使用的版本是VLLM 0.7.2 V1版本的离线推理过程,模型为Qwen2.5-1.5B-Instruct。
Model Executor相关类成员和函数关系
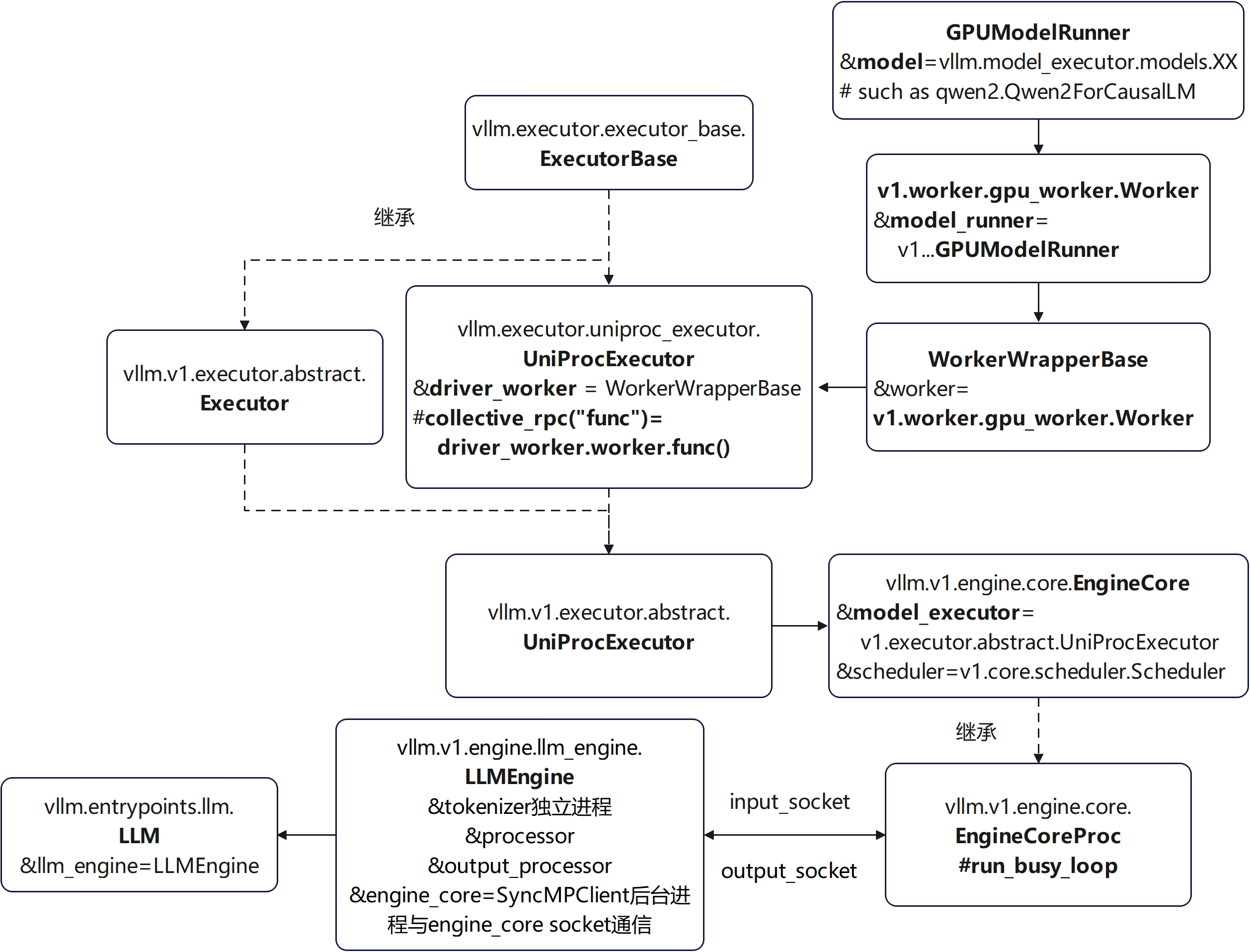
对于EngineCore.model_executor的一个函数调用,例如execute_model等等,基本调用流程如下,最终会调用到worker的这个函数:
EngineCore.model_executor.function()->
vllm.v1.executor.abstract.Executor.function()->
vllm.executor.uniproc_executor.UniProcExecutor.collective_rpc("function")->
run_method(UniProcExecutor.driver_worker, method, args, kwargs)->
UniProcExecutor.driver_worker.worker.function()->
vllm.v1.worker.gpu_worker.Worker.function()
进一步调用vllm.v1.worker.gpu_model_runner.GPUModelRunner的相关方法。
这里面大量使用了collective_rpc方法,对于UniProcExecutor而言,其直接通过run_method调用UniProcExecutor.driver_worker.worker的类方法,而不是远程调用。
Model Executor创建和加载
vllm.v1.engine.core.EngineCore里面创建了model_executor对象:
self.model_executor = executor_class(vllm_config) # UniProcExecutor for offline infer对于离线推理model_executor是vllm.v1.executor.abstract.UniProcExecutor。
模型创建和加载
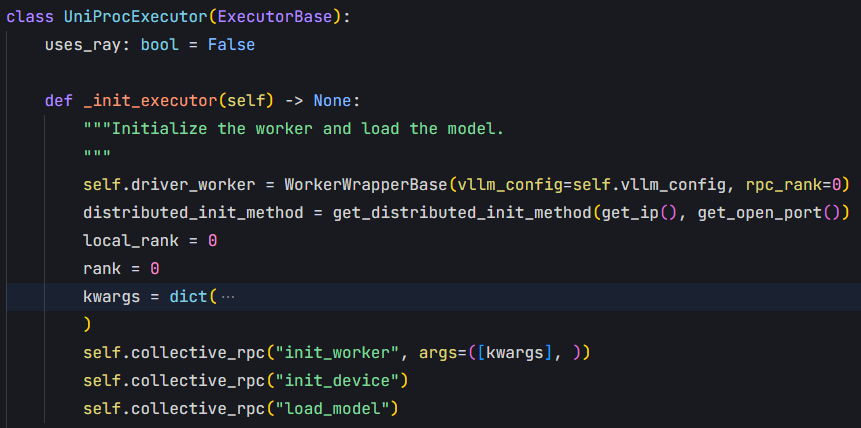
vllm.v1.engine.core.EngineCore.model_executor = vllm.executor.uniproc_executor.UniProcExecutor(vllm_config)->
UniProcExecutor.driver_worker = WorkerWrapperBase(vllm_config=self.vllm_config, rpc_rank=0)
UniProcExecutor.collective_rpc("init_worker", args=([kwargs], ))->
WorkerWrapperBase.worker = worker_class(**kwargs) # vllm.v1.worker.gpu_worker.Worker
UniProcExecutor.collective_rpc("init_device")->
vllm.v1.worker.gpu_worker.Worker.init_device()->
Worker.model_runner = vllm.v1.worker.gpu_model_runner.GPUModelRunner(self.vllm_config, self.device)->
UniProcExecutor.collective_rpc("load_model")->
vllm.v1.worker.gpu_worker.Worker.load_model()->
Worker.model_runner.load_model()->
model_runner.model = get_model(vllm_config=self.vllm_config)
整个过程确实比较繁琐,一环套一环。
创建driver_worker时只创建了这个对象本身,然后init_device时创建driver_worker的对象。然后load_model才真正创建模型和加载权重。
问题:包装这么多层次的必要性和优缺点?跟sglang的设计对比。每个层次干的活的特殊性?
模型初始化
模型创建后,在EngineCore里面还进行了一次_initialize_kv_caches操作,这里面调用了
EngineCore.model_executor.initialize(kv_cache_config)->
model_executor.collective_rpc("initialize_cache", args=(kv_cache_config, ))
model_executor.collective_rpc("compile_or_warm_up_model")->
Worker.compile_or_warm_up_model()vllm.v1.worker.gpu_worker.Worker.compile_or_warm_up_model,进行warmup和Graph capturing。
def compile_or_warm_up_model(self) -> None:
# warm up sizes that are not in cudagraph capture sizes,
# but users still want to compile for better performance,
# e.g. for the max-num-batched token size in chunked prefill.
warmup_sizes = self.vllm_config.compilation_config.compile_sizes.copy()
if not self.model_config.enforce_eager:
warmup_sizes = [
x for x in warmup_sizes if x not in
self.vllm_config.compilation_config.cudagraph_capture_sizes
]
for size in sorted(warmup_sizes, reverse=True):
logger.info("Compile and warming up model for size %d", size)
self.model_runner._dummy_run(size)
if not self.model_config.enforce_eager:
self.model_runner.capture_model()
# Reset the seed to ensure that the random state is not affected by
# the model initialization and profiling.
set_random_seed(self.model_config.seed)
Graph capturing
可以参考下面的博客获取详细内容:
VLLM V1 graph capture图捕获-优快云博客
graph capture可以参考:
https://docs.vllm.ai/en/latest/design/v1/torch_compile.html
vllm 为什么没在 prefill 阶段支持 cuda graph?
GPUModelRunner.capture_model:
def capture_model(self) -> None:
start_time = time.perf_counter()
start_free_gpu_memory = torch.cuda.mem_get_info()[0]
# Trigger CUDA graph capture for specific shapes.
# Capture the large shapes first so that the smaller shapes
# can reuse the memory pool allocated for the large shapes.
with graph_capture(device=self.device):
for num_tokens in reversed(self.cudagraph_batch_sizes):
for _ in range(self.vllm_config.compilation_config.cudagraph_num_of_warmups):
self._dummy_run(num_tokens)
self._dummy_run(num_tokens)
end_time = time.perf_counter()
end_free_gpu_memory = torch.cuda.mem_get_info()[0]
elapsed_time = end_time - start_time
cuda_graph_size = start_free_gpu_memory - end_free_gpu_memory
# This usually takes 5~20 seconds.
logger.info("Graph capturing finished in %.0f secs, took %.2f GiB", elapsed_time, cuda_graph_size / (1 << 30))
@contextmanager
def graph_capture(device: torch.device):
"""
`graph_capture` is a context manager which should surround the code that
is capturing the CUDA graph. Its main purpose is to ensure that the
some operations will be run after the graph is captured, before the graph
is replayed. It returns a `GraphCaptureContext` object which contains the
necessary data for the graph capture. Currently, it only contains the
stream that the graph capture is running on. This stream is set to the
current CUDA stream when the context manager is entered and reset to the
default stream when the context manager is exited. This is to ensure that
the graph capture is running on a separate stream from the default stream,
in order to explicitly distinguish the kernels to capture
from other kernels possibly launched on background in the default stream.
"""
context = GraphCaptureContext(torch.cuda.Stream(device=device))
with get_tp_group().graph_capture(context), get_pp_group().graph_capture(context):
yield context
实际cudagraph_num_of_warmups=1,graph capture时这个warmup有何用?
捕获的graph num_tokens数量为cudagraph_batch_sizes,在vllm.config.VllmConfig._set_cudagraph_sizes里面设置:
batch_size_capture_list = []
if self.model_config is not None and not self.model_config.enforce_eager:
batch_size_capture_list = [1, 2, 4] + [i for i in range(8, 513, 8)]
Model Executor执行
EngineCore.step函数中调用了model_executor进行执行
scheduler_output = self.scheduler.schedule()
output = self.model_executor.execute_model(scheduler_output)

















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











