









搭建代理服务器
一般情况下高性能服务器为了安全起见,仅仅在内网使用,无法上公网,因此第一步配置代理服务器,让高性能服务器可以上公网。
首选Windows + CCProxy免费版
官网地址:http://www.ccproxy.com/
基本设置。
这个多了点,看情况少选一些。
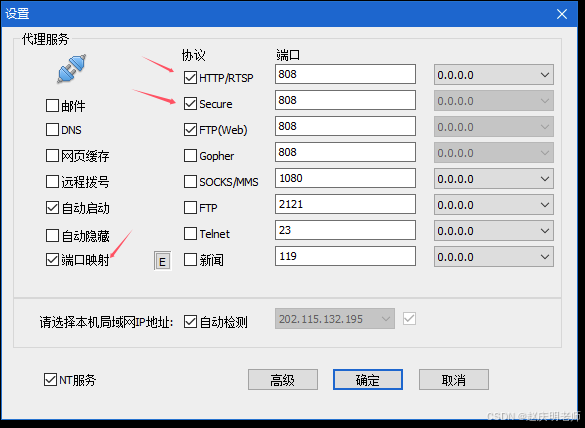
设置Windows防火墙,开放808端口

记下代理服务器地址:
http://代理服务器IP:808
高性能服务器上要用。
下载Ollama程序
在自己电脑上登录Ollama官网
https://ollama.com/download/linux
不建议直接在服务器上下载:原因是文件太大了,容易下载失败。
在你的PC机上使用下载工具下载,更快,更不容易失败。
点击“手动安装指令”
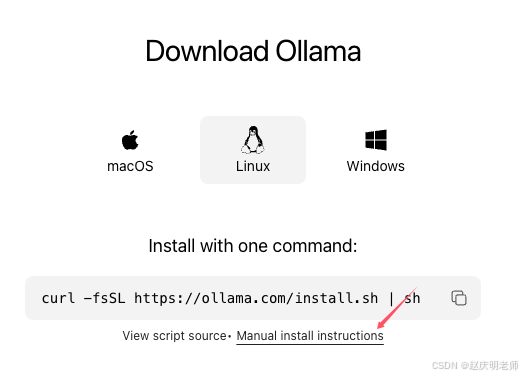
跳转到了github
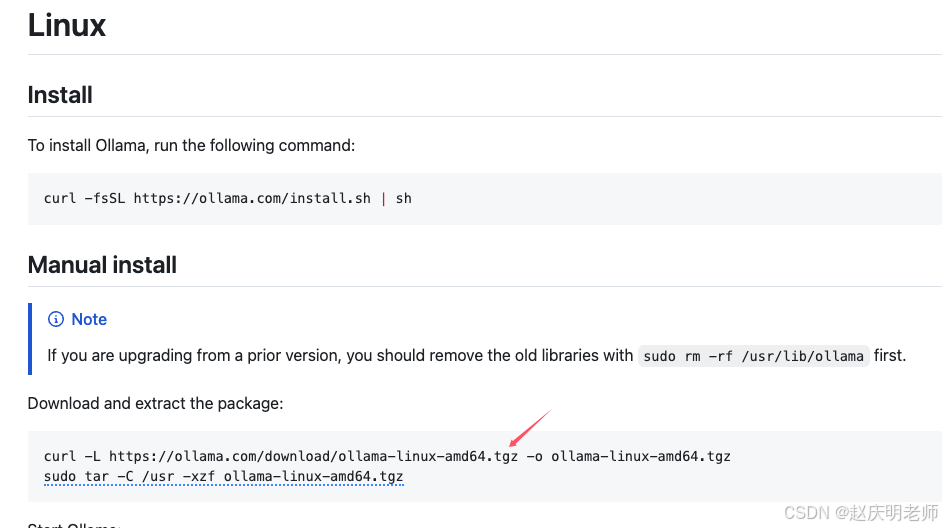
https://github.com/ollama/ollama/blob/main/docs/linux.md
下载这个压缩文件
注意:有可能版本太高,需要升级服务器的glibc(不过,普通用户基本上没权限)
如果不想升级的话,或者无权限升级的话,可以考虑用低版本的。v0.5.12
https://github.com/ollama/ollama/releases
高性能服务器操作
登录
ssh username@用户可登录的linux入口服务器
上载Ollama
通过FileZilla、XFTP等软件,将刚下载的"ollama-linux-amd64.tgz"传到远程服务器集群上。
解压
注意:这里和官网文档不一致。
我将其解压到我的主目录下的.local文件夹内。
mkdir -p ~/.local
tar -C ~/.local -xzvf ollama-linux-amd64.tgz
检查集群服务器
sinfo -o "%10n %10G %10t"
sinfo
[abc@login01 ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
cn up infinite 2 down* cn[15,21]
cn up infinite 5 mix cn[08-10,17,22]
cn up infinite 17 alloc cn[01-07,11-14,16,18-20,23-24]
cn1 up infinite 5 mix cn[31,42,44-46]
cn1 up infinite 17 alloc cn[25-30,32-41,43]
fat up infinite 1 mix fat01
gpu2 up infinite 1 mix gpu02
gpu3 up infinite 1 mix gpu03
gpu4 up infinite 1 down* gpu05
gpu4 up infinite 1 mix gpu04
gpu5 up infinite 1 down* gpu06
gpu5 up infinite 1 alloc gpu08
gpu6* up infinite 1 alloc gpu07
找一个可用的、带GPU显卡的服务器,比如 “gpu3 up infinite 1 mix gpu03”,登录
登录Slurm 集群
srun -w gpu03 -p gpu3 -n 1 --pty bash
检查NVIDA GPU
nvidia-smi
nvidia-smi -L
设置环境参数
export OLLAMA_GPU_LAYER=cuda
# 模型加载后,不自动卸载
export OLLAMA_KEEP_ALIVE=-1
# 添加Ollama程序的路径
export PATH="$HOME/.local/bin:$PATH"
# 设置开放端口
export OLLAMA_HOST="0.0.0.0:8081"
# 允许跨域访问
export OLLAMA_ORIGINS="*"
# 设置代理服务器
export HTTPS_PROXY="http://代理服务器IP:808"
# 立即生效
source ~/.bashrc
启动Ollama
启动ollama 很快
ollama serve &> /dev/null &
加载模型很慢
这一步下载并运行模型,需要你的高性能服务器能上网
如果不能上网,则需要配置代理服务器
export HTTPS_PROXY=“http://代理服务器IP:808”
如果模型已经下载,就不需要再下载,但加载模型的时间也比较长,5-10分钟
ollama run deepseek-r1:32b
接下来就可以在这里聊天了。
访问
本地访问
curl http://127.0.0.1:8081
输出内容:Ollama is running
远程访问
curl http://高性能服务器IP地址:8081
输出内容:Ollama is running
对话
curl http://高性能服务器IP地址:8081/api/generate -d '{
"model": "deepseek-r1:32b",
"prompt":"Why is the sky blue?"
}'
加载模型
如果不能再高性能服务器上操作的话,可以通过远程加载大模型。
记住,这里每一步都很耗费时间。不要着急。
这里拉取 deepseek-r1:70b 模型
curl http://高性能服务器IP地址:8081/api/pull -d '{"model":"deepseek-r1:70b"}'
这里加载 deepseek-r1:70b 模型
curl http://高性能服务器IP地址:8081/api/chat -d '{
"model": "deepseek-r1:70b",
"messages": []
}'
然后对话 deepseek-r1:70b 模型
curl http://高性能服务器IP地址:8081/api/generate -d '{
"model": "deepseek-r1:70b",
"prompt":"Why is the sky blue?"
}'




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











