







 本文研究利用脚本刷取网页访问量或关键词搜索频率,仅供学习交流。介绍了以脚本程序重复实现伪装浏览器方式的搜索请求,包括查看请求头、发送请求数据、更改请求参数、获取代理IP等步骤,还给出刷取校园网关键词搜索频次的代码示例。
本文研究利用脚本刷取网页访问量或关键词搜索频率,仅供学习交流。介绍了以脚本程序重复实现伪装浏览器方式的搜索请求,包括查看请求头、发送请求数据、更改请求参数、获取代理IP等步骤,还给出刷取校园网关键词搜索频次的代码示例。
生活中经常会有一些刷票、刷热搜、刷访问量的情况,其原理是怎么实现的呢,本篇研究了利用脚本刷取网页访问量或关键词搜索频率,声明如下:本篇仅供学习交流,作者水平有限如有出入请纠正,请勿恶意使用封号后果自负。
总结一下,我们的目标就是以脚本程序重复实现伪装浏览器方式的搜索请求,并骗过服务器的过滤或者检查。
1.首先打开目标网站,如下图所示:
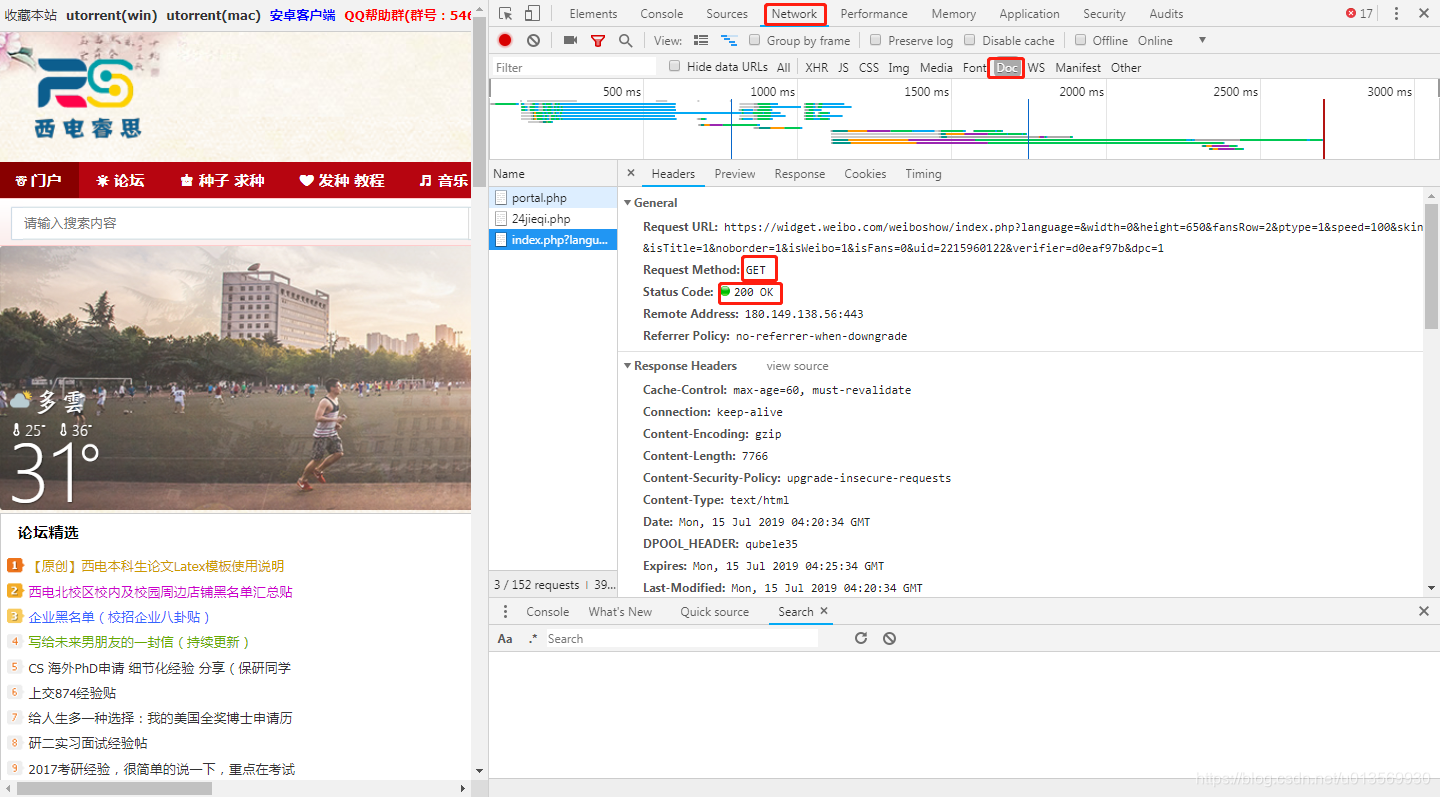
以chorme浏览器为例,打开网页开发者工具(F12),切换到Network ,Doc标签页,查看headers中有数据请求头,以图中为例Request Method声明Get方法,于是我们这里也采用Request.Get()方法,其他的比如POST等,根据需要使用,会有不同的数据头格式。
requests.get(' ')
requests.post(' ')
requests.put(' ')
requests.delete(' ')
requests.head(' ')
requests.options(' ')2.接下来简单讲一下,怎么发送请求数据:
import requests
url ='http://rs.xidian.edu.cn/bt.php?mod=browse&t=all'
r = requests.get(url)
print(r)
r.status_code
print(r.text)
直接使用request.get方法,会返回状态码r:
1.信息提示
0代表本地响应成功
100 - Continue 初始的请求已经接受,客户应当继续发送请求的其余部分
101 - Switching Protocols 服务器将遵从客户的请求转换到另外一种协议
2.请求成功
200 - OK 一切正常,对GET和POST请求的应答文档跟在后面
201 - Created 服务器已经创建了文档,Location头给出了它的URL
202 - Accepted 已经接受请求,但处理尚未完成
203 - Non-Authoritative Information 文档已经正常地返回,但一些应答头可能不正确,因为使用的是文档的拷贝,非权威性信息
204 - No Content 没有新文档,浏览器应该继续显示原来的文档。如果用户定期地刷新页面,而Servlet可以确定用户文档足够新,这个状态代码是很有用的
205 - Reset Content 没有新的内容,但浏览器应该重置它所显示的内容。用来强制浏览器清除表单输入内容
206 - Partial Content 客户发送了一个带有Range头的GET请求,服务器完成了它
3.重定向
300 - Multiple Choices 客户请求的文档可以在多个位置找到,这些位置已经在返回的文档内列出。如果服务器要提出优先选择,则应该在Location应答头指明。
301 - Moved Permanently 客户请求的文档在其他地方,新的URL在Location头中给出,浏览器应该自动地访问新的URL。
302 - Found 类似于301,但新的URL应该被视为临时性的替代,而不是永久性的。注意,在HTTP1.0中对应的状态信息是“Moved Temporatily”。出现该状态代码时,浏览器能够自动访问新的URL,因此它是一个很有用的状态代码。注意这个状态代码有时候可以和301替换使用。例如,如果浏览器错误地请求 http://host/~user (缺少了后面的斜杠),有的服务器返回301,有的则返回302。严格地说,我们只能假定只有当原来的请求是GET时浏览器才会自动重定向。请参见307。
303 - See Other 类似于301/302,不同之处在于,如果原来的请求是POST,Location头指定的重定向目标文档应该通过GET提取(HTTP 1.1新)。
304 - Not Modified 客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档)。服务器告诉客户,原来缓冲的文档还可以继续使用。
305 - Use Proxy 客户请求的文档应该通过Location头所指明的代理服务器提取
4.客户端错误
400 - Bad Request 请求出现语法错误。
401 - Unauthorized 访问被拒绝,客户试图未经授权访问受密码保护的页面。应答中会包含一个WWW-Authenticate头,浏览器据此显示用户名字/密码对话框,然后在填写合适的Authorization头后再次发出请求。IIS 定义了许多不同的 401 错误,它们指明更为具体的错误原因。这些具体的错误代码在浏览器中显示,但不在 IIS 日志中显示:
403 - Forbidden 资源不可用。服务器理解客户的请求,但拒绝处理它。通常由于服务器上文件或目录的权限设置导致。禁止访问:IIS 定义了许多不同的 403 错误,它们指明更为具体的错误原因:
参考:https://blog.youkuaiyun.com/l_mloveforever/article/details/82892292
返回200即请求发送成功。
3.根据需要更改,get()命令的参数,参考API:https://2.python-requests.org//en/master/api/

根据自己需要选择需要更改的参数加入。
4.获取代理IP,伪装IP以及请求头中的浏览器标识,防止服务器过滤,大家好像都用的西刺代理:http://www.xicidaili.com/
import urllib2
import time
from multiprocessing import Pool#多进程
import random
from lxml import etree #解析
def GetUserAgent():
'''
功能:随机获取HTTP_User_Agent
'''
user_agents=[
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)"
]
user_agent = random.choice(user_agents)
return user_agent
def getProxies():
'''
功能:爬取西刺高匿IP构造原始代理IP池
'''
init_proxies = []
##爬取前十页
for i in range(1,11):
print("####")
print("####爬取第"+str(i)+"页####")
print("####")
print("IP地址\t\t\t端口\t存活时间\t\t验证时间")
url = "http://www.xicidaili.com/nn/"+str(i)
user_agent = GetUserAgent()
headers=("User-Agent",user_agent)
opener = urllib2.build_opener()
opener.addheaders = [headers]
try:
data = opener.open(url,timeout=5).read()
except Exception as er:
print("爬取的时候发生错误,具体如下:")
print(er)
selector=etree.HTML(data)
ip_addrs = selector.xpath('//tr[@class="odd"]/td[2]/text()') #IP地址
port = selector.xpath('//tr[@class="odd"]/td[3]/text()') #端口
sur_time = selector.xpath('//tr[@class="odd"]/td[9]/text()') #存活时间
ver_time = selector.xpath('//tr[@class="odd"]/td[10]/text()') #验证时间
for j in range(len(ip_addrs)):
ip = ip_addrs[j]+":"+port[j]
init_proxies.append(ip)
#输出爬取数据
print(ip_addrs[j]+"\t\t"+port[j]+"\t\t"+sur_time[j]+"\t"+ver_time[j])
return init_proxies
def testProxy(curr_ip):
'''
功能:验证IP有效性
@curr_ip:当前被验证的IP
'''
tmp_proxies = []
#socket.setdefaulttimeout(10) #设置全局超时时间
tarURL = "http://www.baidu.com/"
user_agent = GetUserAgent()
proxy_support = urllib2.ProxyHandler({"http":curr_ip})
opener = urllib2.build_opener(proxy_support)
opener.addheaders=[("User-Agent",user_agent)]
urllib2.install_opener(opener)
try:
res = urllib2.urlopen(tarURL,timeout=5).read()
if len(res)!=0:
tmp_proxies.append(curr_ip)
except urllib.error.URLError as er2:
if hasattr(er2,"code"):
print("验证代理IP("+curr_ip+")时发生错误(错误代码):"+str(er2.code))
if hasattr(er2,"reason"):
print("验证代理IP("+curr_ip+")时发生错误(错误原因):"+str(er2.reason))
except Exception as er:
print("验证代理IP("+curr_ip+")时发生如下错误):")
print(er)
time.sleep(2)
return tmp_proxies
def mulTestProxies(init_proxies):
'''
功能:多进程验证IP有效性
@init_proxies:原始未验证代理IP池
'''
pool = Pool(processes=7)
fl_proxies = pool.map(testProxy,init_proxies)
pool.close()
pool.join() #等待进程池中的worker进程执行完毕
return fl_proxies
if __name__ == '__main__':
#---(1)获取代理IP池
init_proxies = getProxies() #获取原始代理IP
tmp_proxies = mulTestProxies(init_proxies) #多进程测试原始代理IP
proxy_addrs = []
for tmp_proxy in tmp_proxies:
if len(tmp_proxy)!=0:
proxy_addrs.append(tmp_proxy)
4.刷取访问,以下是我刷取校园网上某一关键词的搜索频次的代码,因为校园网仅限内部IP访问,故没有采用IP代理.
import requests
import time
import random
import os
urlGroup = ["http://rs.xidian.edu.cn/bt.php?w=%E6%9A%91%E5%81%87%E5%BF%AB%E4%B9%90%EF%BC%81&c=&t=all",
"http://rs.xidian.edu.cn/bt.php?w=%E9%98%BF%E4%B8%BD%E5%A1%94&c=&t=all",
"http://rs.xidian.edu.cn/forum.php"]
AgentGroup = ["Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"]
# 自定义代理ip,此处的ip需要自行更换,只需要将ip和port按格式拼接即可,可以去网上免费代理中寻找:http://www.xicidaili.com/nn
#proxies = {"https": "https://192.168.0.94:8080", "http": "http://127.0.0.1:1080"}
for i in range(5000):
start_url = random.choice(urlGroup)
UserAgent = random.choice(AgentGroup)
headers = {"Cookie": " ",
"Host": "rs.xidian.edu.cn",
"Referer": "http://rs.xidian.edu.cn/bt.php?mod=browse&t=all",
"User-Agent": UserAgent,
"X-Requested-With": "XMLHttpRequest"
}
response = requests.get(url=start_url, headers=headers)#, proxies=proxies
print(response,i) # 返回值:<Response [200]>
delay_time = random.uniform(0,4)
time.sleep(delay_time)
print('Done')
#os.system('shutdown -s -t 3')
#os.system('shutdown -a')
参照代码做一些解释:
首先是访问目标地址,我做了一些随机切换,以避免长时间单一关键词搜索造成服务器过滤;
其次是请求头,如下图所示:
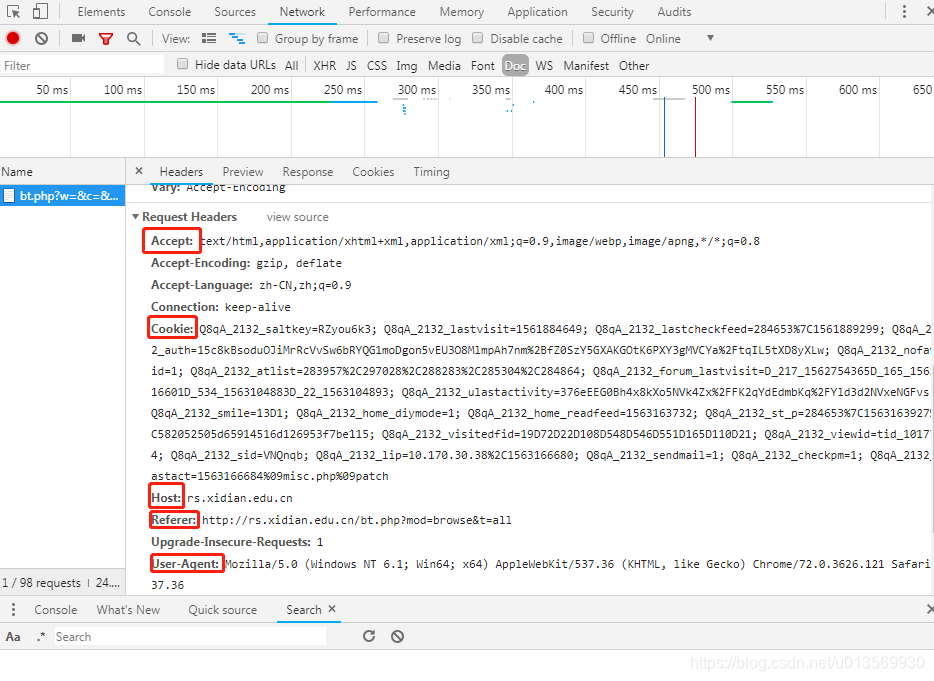
参考浏览器使用的请求方式,将cookie,Host,Referer(上一个目标地址),User-Agent等引入程序的请求头,并做了浏览器标识的随机切换,再加上随机延时,都是为了伪装防止服务器过滤。
然后是IP,这里没有做,可以考虑再加入多个请求IP的随机切换,能够达到更好的伪装效果。
刷取热搜关键词搜索频次效果如下图所示:


















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









