




 复制算法由M.L.Minsky提出,用于解决垃圾收集效率问题。该算法将内存分为两部分,每次只使用一半,垃圾回收时将存活对象复制到未使用的区域并清空原区域。优点是实现简单、运行高效且避免了碎片问题,但需要双倍内存空间。适用于年轻代回收,尤其在垃圾对象多、存活对象少的场景,如新生代的Survivor区。
复制算法由M.L.Minsky提出,用于解决垃圾收集效率问题。该算法将内存分为两部分,每次只使用一半,垃圾回收时将存活对象复制到未使用的区域并清空原区域。优点是实现简单、运行高效且避免了碎片问题,但需要双倍内存空间。适用于年轻代回收,尤其在垃圾对象多、存活对象少的场景,如新生代的Survivor区。
垃圾清除阶段算法之复制算法
复制( Copying )算法
背景:
为了解决标记-清除算法在垃圾收集效率方面的缺陷,M. L. Minsky于1963年发表了著名的论文,“ 使用双存储区的Li sp语言垃圾收集器CA LISP Garbage Collector Algorithm Using Serial Secondary Storage )’”。M.L.Minsky 在该论文中描述的算法被人们称为复制(Copying) 算法,它也被M. L.Minsky本人成功地引入到了Lisp语言的一个实现版本中。
核心思想:
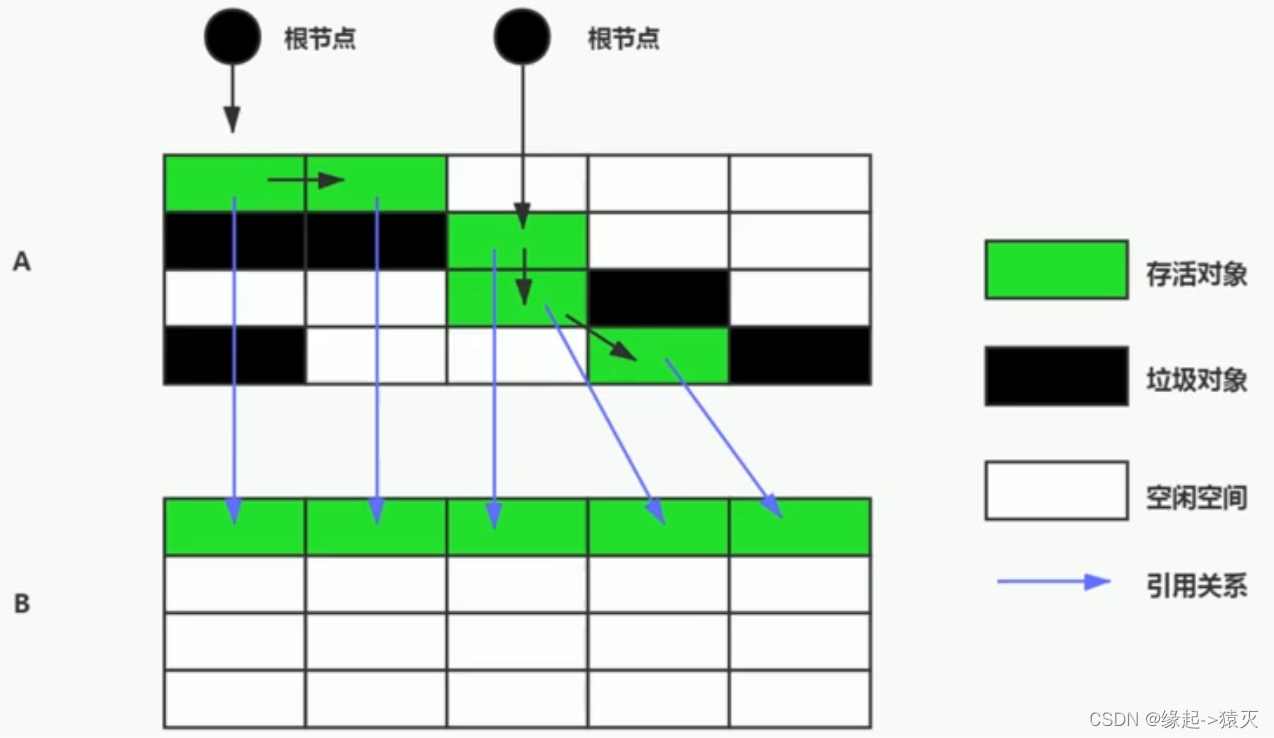
将活着的内存空间分为两块,每次只使用其中一块,在垃圾回收时将正在使用的内存中的存活对象复制到未被使用的内存块中,之后清除正在使用的内存块中的所有对象,交换两个内存的角色,最后完成垃圾回收。
优点:
没有标记和清除过程,实现简单,运行高效
复制过去以后保证空间的连续性,不会出现“碎片”问题。
缺点:
此算法的缺点也是很明显的,就是需要两倍的内存空间。
对于G1这种分拆成为大量region的GC,复制而不是移动,意味着GC需要维护region之间对象引用关系,不管是内存占用或者时间开销也不小。
特别的:
如果系统中的垃圾对象很多,复制算法需要复制的存活对象数量并不会太大,或者说非常低才行。
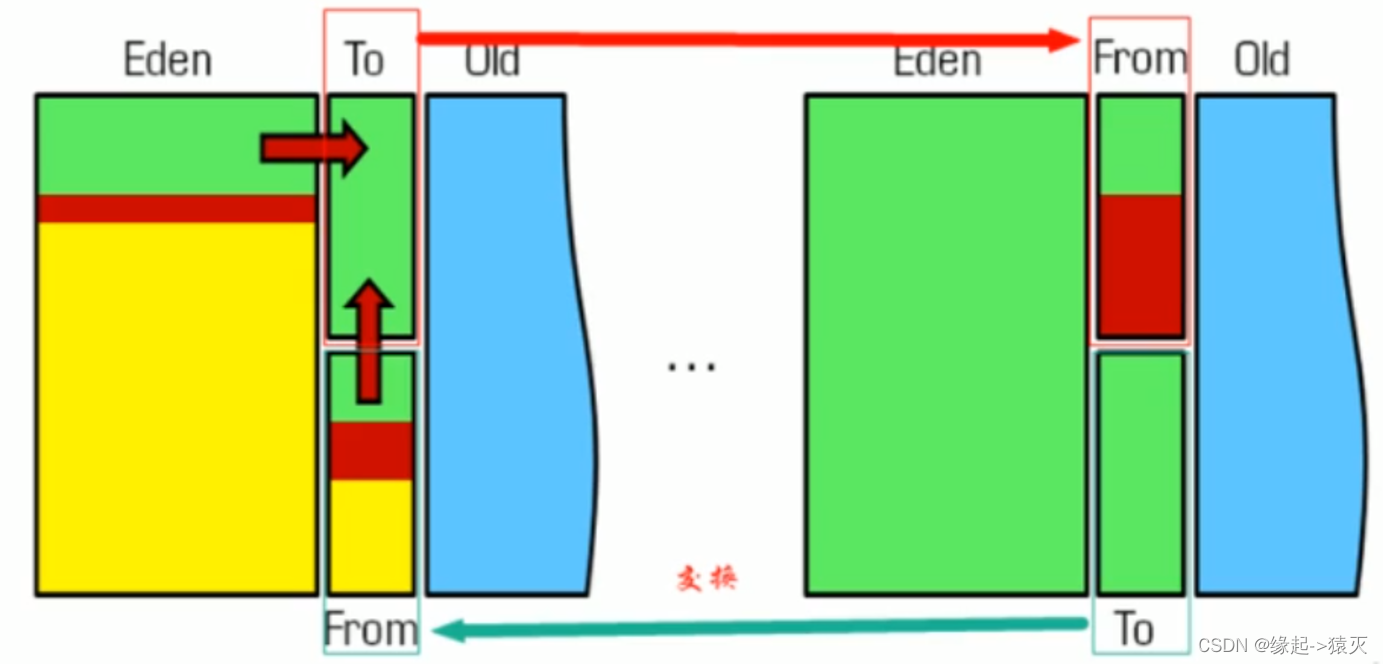
即特别适合垃圾对象很多,存活对象很少的场景;例如: Young区的Survivor0和Survivor1区
应用场景:
在新生代,对常规应用的垃圾回收,一次通常可以回收70号- 99的内存空间。回收性价比很高。所以现在的商业虚拟机都是用这种收集算法回收新生代。
比很高。所以现在的商业虚拟机都是用这种收集算法回收新生代。

















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









