







导图
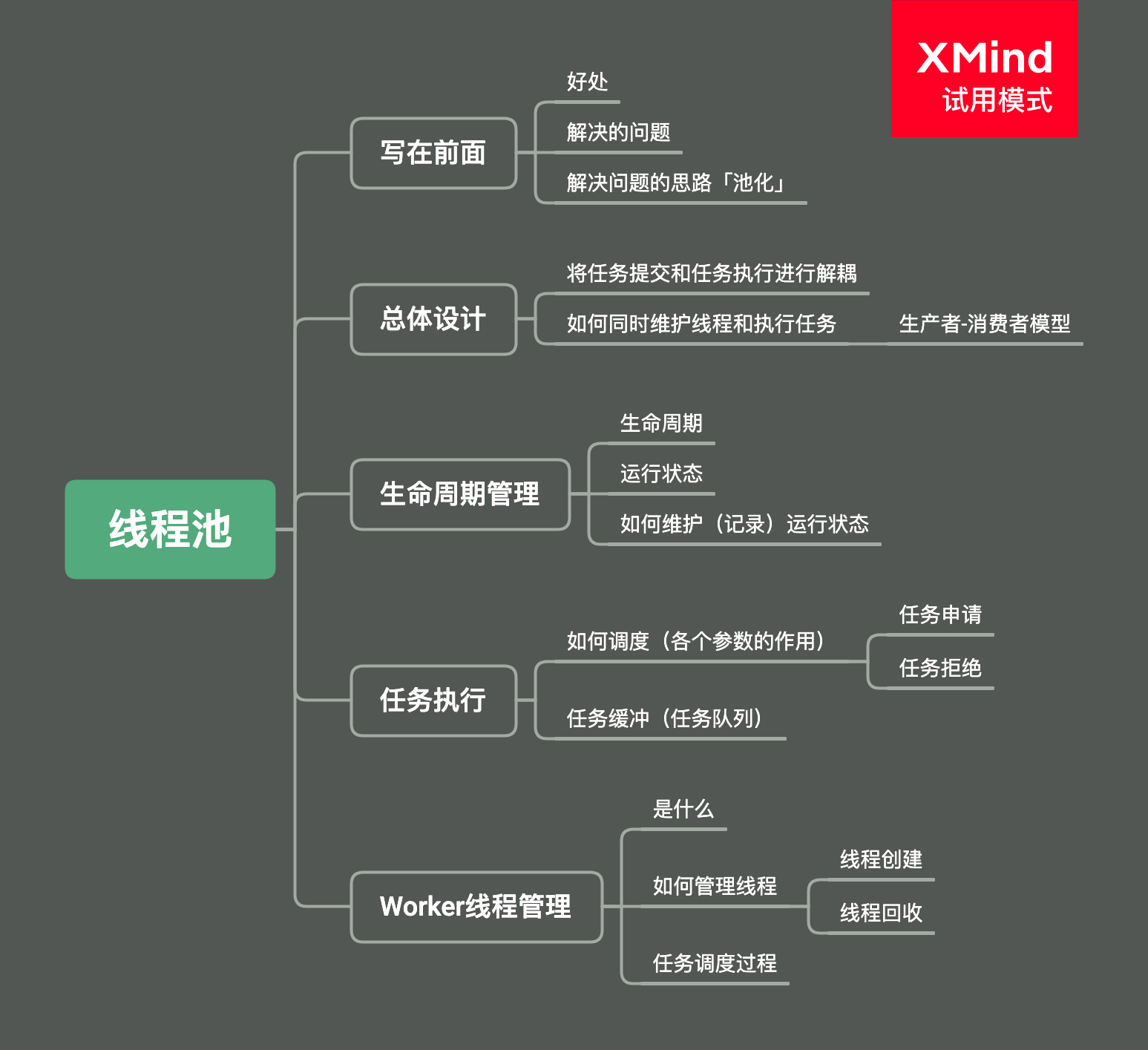
写在前面
线程池是基于「池化」思想锁设计的线程管理和任务调度工具
好处
- 降低资源消耗:重复利用已创建(池化)的线程,降低线程创建和销毁造成的性能损耗。
- 如果 创建与销毁消耗的时间 > 任务执行时间,是很低效的。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。
- 根据jvm规范,一个线程默认最大栈大小1M,这个栈空间是需要从系统内存中分配的。线程越多,消耗内存就越多。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
池化思想
池化思想在计算机领域中的表现为:统一管理服务器、存储、和网络资源等等。
比较典型的几种使用:
- 内存池(Memory Pooling):预先申请内存,提升申请内存速度,减少内存碎片。
- 实例池(Object Pooling):循环使用对象,减少资源在初始化和释放时的昂贵损耗。
- 连接池(Connection Pooling):预先申请数据库连接,提升申请连接的速度,降低系统的开销。
解决的问题
解决的核心问题是资源管理问题。系统并不能确定任意时刻,需要多少线程执行多少任务。
- 无法统一的管控资源(线程):可能使系统资源耗尽。
- 频繁的申请和销毁资源:带来额外的时间损耗。
- 无法系统的管理资源分配:没有统一的入口管理资源和任务。
总体设计
设计
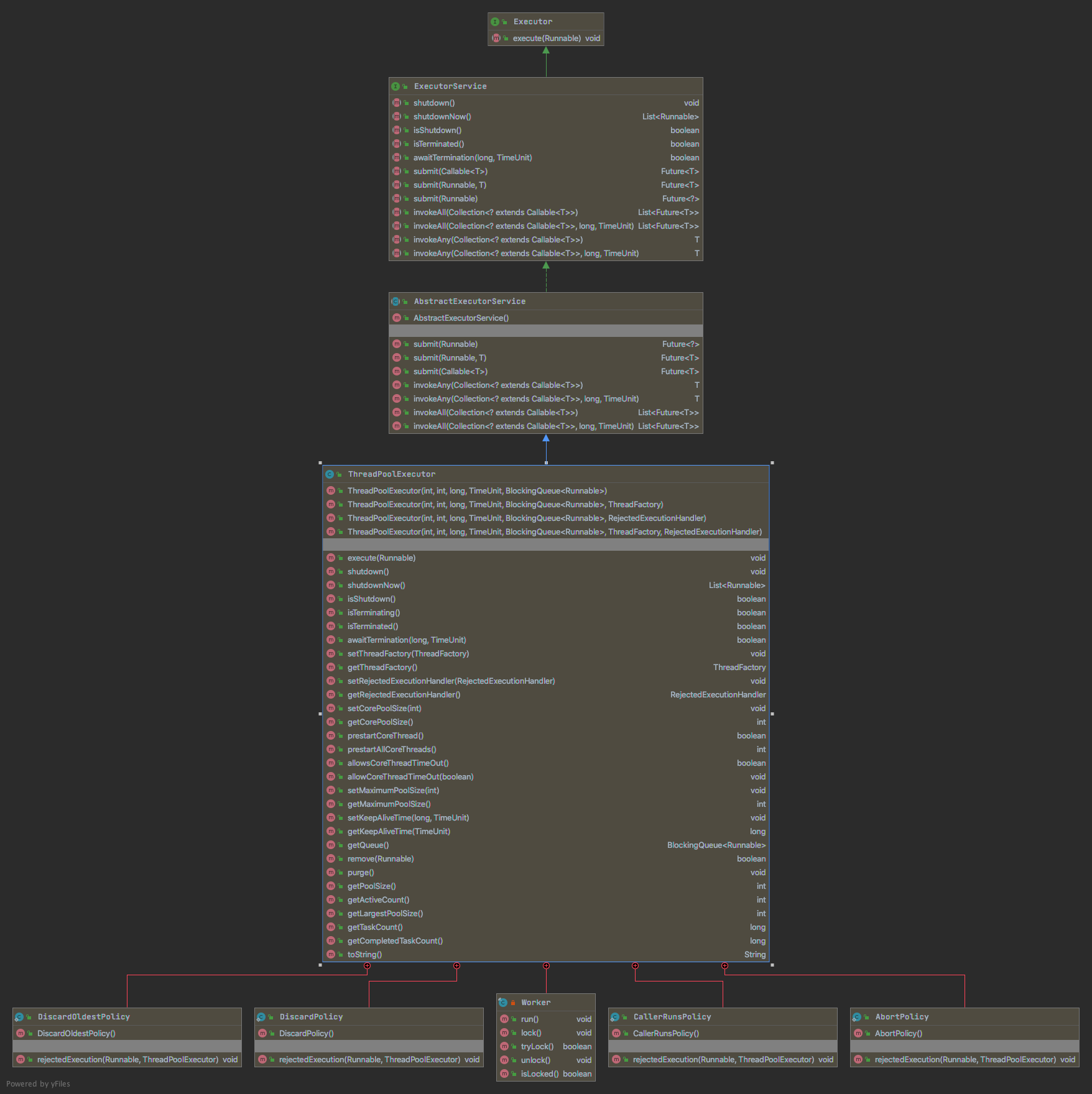
- Executor:顶层接口,将任务的提交和任务的执行解耦。用户只需要提交 Runnable 到 Executor,由 Executor 框架进行任务的调度与执行
- ExecutorService:支持异步任务的提交(submit);支持停止线程池(shutdown/shutdownNow)
- AbstractExecutorService:将任务执行流程串联起来(newTaskFor)
- ThreadPoolExecutor:实现了最复杂的任务运行。ThreadPoolExecutor 一方面需要维护自身生命周期、领域方面需要同时管理线程和任务。
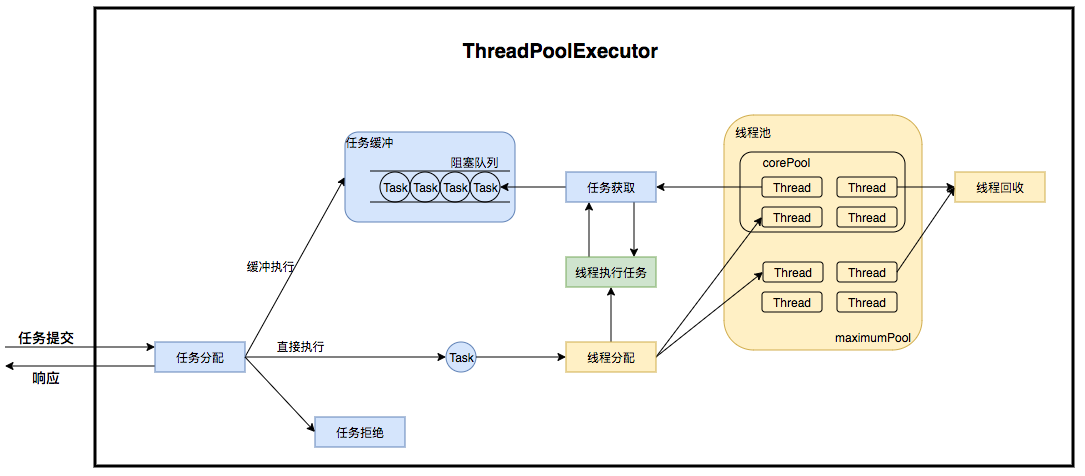
将任务提交和任务执行进行解耦
- 线程池内部构件了一个 生产者-消费者 模型,将线程和任务解耦,可以达到任务缓冲、复用线程的目的。
-
- 生产者:任务管理
- 消费者:线程管理
生命周期管理
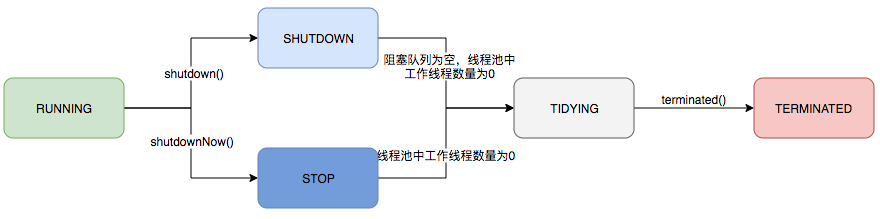
运行状态
ThreadPoolExecutor 共定义了五种运行状态
- 其中,shutdown/stop 可通过 shutdown() 和 shutdownNow() 触发

生命周期
如何维护(记录)运行状态
线程池内部维护了一个变量 ctl 用来记录线程池的运行状态和池内有效线程数量。其中,高3位用于记录线程池的状态(runState);低29位用于就池内有效线程数量(workerCount)。
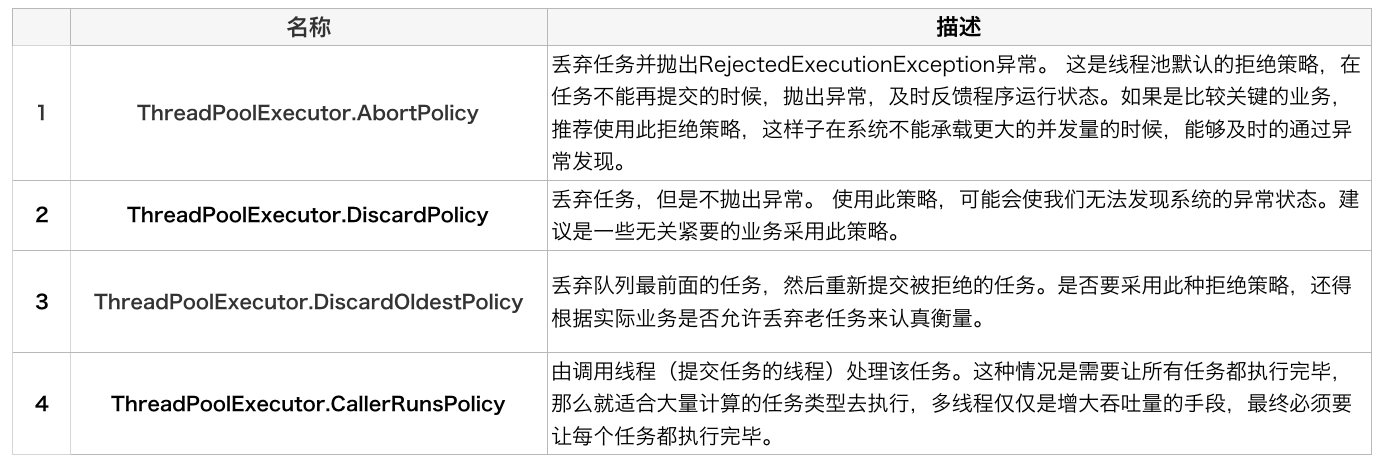
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));1. 工作线程Worker会不断接收新任务去执行,而当工作线程Worker接收不到任务的时候,就会开始被回收。任务拒绝(拒绝策略)我们可以自定义拒绝策略,或使用 JDK 提供的四种拒绝策略
- 自定义拒绝策略
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}- 默认拒绝策略(抛异常、丢弃任务、丢弃最老的、由提交线程自行处理任务)
任务缓冲(任务队列)
线程池中的生产者-消费者模式,是通过阻塞队列来实现的。
我们可以用不同的阻塞队列来实现不同的策略。

管理Worker工作线程
是什么
为了个更好的掌握线程的状态和维护线程的生命周期,线程池内部定义了工作线程Worker
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{
final Thread thread;//Worker持有的线程
Runnable firstTask;//初始化的任务,可以为null
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
}- 任务执行流程示意图
当 addWorker 成功后,主线程就会拉起 worker 线程执行任务
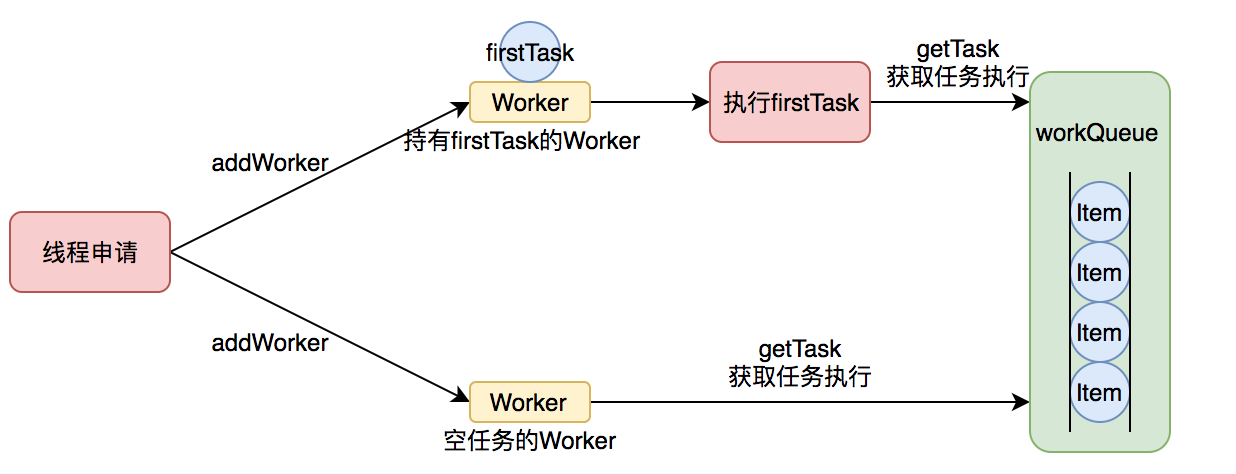
新增Worker(addWorker)
该方法会新增一个工作线程并使他运行。
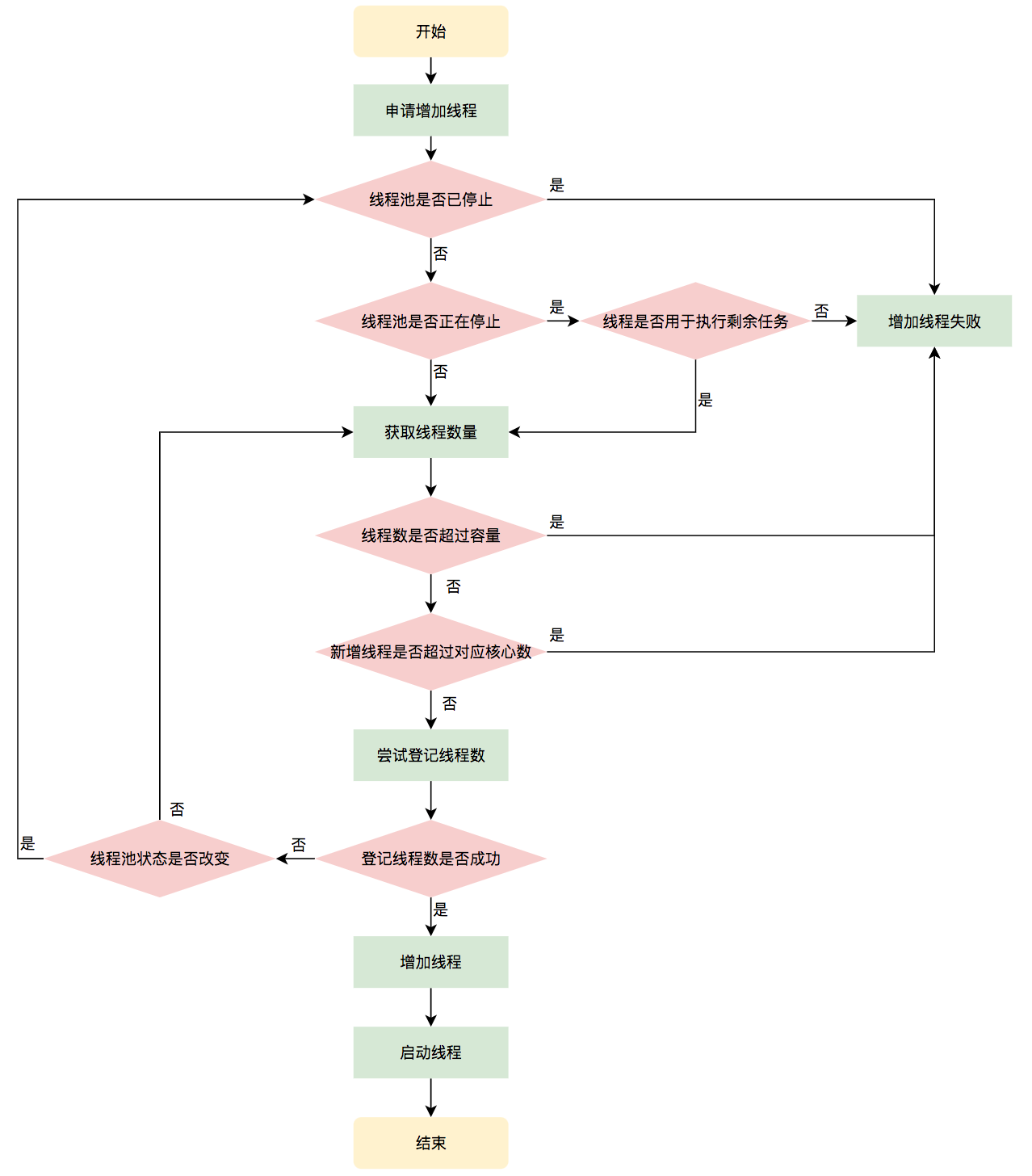
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (int c = ctl.get();;) {
//1. 判断当前线程池状态
if (runStateAtLeast(c, SHUTDOWN) && (runStateAtLeast(c, STOP) || firstTask != null || workQueue.isEmpty())){
return false;
}
//CAS + 1
for (;;) {
//2.1 判断是否超过 corePoolSize OR maximumPoolSize
if (workerCountOf(c)
>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
//2.2 线程状态改变,重新判断线程池状态,否则重新 CAS
if (runStateAtLeast(c, SHUTDOWN))
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
//3 增加Worker线程/启动线程/执行第一个任务
...
if (workerAdded) {
t.start();
workerStarted = true;
}
...
}
- 申请工作线程并执行过程
回收Worker
线程池中,工作线程的销毁依赖 JVM 的垃圾回收机制。
getTask() 上面已经说过,核心线程会阻塞等待,超过核心线程数的部分会超时等待,如果这里返回了 null,则会跳出循环。调出后会在 processWorkerExit 中,将自己的引用从 workers 中移除掉。
final void runWorker(Worker w) {
try {
while (task != null || (task = getTask()) != null) {
//执行任务
}
} finally {
//获取不到任务时,主动回收自己
processWorkerExit(w, completedAbruptly);
}
}Worker工作线程回收过程。
- 将线程引用移出线程池就已经结束了线程销毁的部分。但由于引起线程销毁的可能性有很多,线程池还要判断是什么引发了这次销毁,是否要改变线程池的现阶段状态,是否要根据新状态,重新分配线程。

使用Worker执行任务
当 addWorker 成功后,主线程就会拉起 worker 线程执行任务
final void runWorker(Worker w) {
try {
//1.0 循环获取任务(根据不同的 worker 类型,阻塞获取或超时阻塞)
while (task != null || (task = getTask()) != null) {
//1.1 申请到了任务,申请不可冲入锁
w.lock();
//1.2 如果线程池正在停止,但worker不是中断状态,则设置中断标志位
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()){
wt.interrupt();
}
//1.3 执行任务
task.run();
}finally {
//1.4 解锁,任务数 +1
task = null;
w.completedTasks++;
w.unlock();
}
} finally {
//2.0 获取不到任务时,主动回收自己
processWorkerExit(w, completedAbruptly);
}
}- 任务执行流程示意图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









