







1.K-means算法的描述

假设需要聚成k个类
①算法先会随机从数据集中选取k个点,把他们当做k个聚类的中心点;
②依次计算数据集中的每一个点与各个中心点的距离,离哪个中心点近,就划分到那个中心点对应的聚类下
③计算分到同一类簇下,所有点的均值,更新中心点,重复②,直至达到迭代结束条件
2、代码
import numpy as np
import matplotlib.pyplot as plt
import random
def get_dis(vec1,vec2):
dist = np.sqrt(np.sum(np.square(vec1 - vec2)))
return dist
def rand_center(dataset,k):
index=[]
index=random.sample(range(1,len(dataset)),k)#range()左闭右开
return dataset[index]
#return dataset[[5, 11, 23]]
'''
dataset数据集
k聚类的个数
n迭代的次数
'''
def k_means(dataset,k,n):
centers = rand_center(dataset, k)
#distance矩阵存储,每个点到中心点的距离
distance_mat = np.ones((len(dataset), k))
time=0
flag = []
while time < n:
# 计算距离
for i in range(0, len(dataset)):
for j in range(0, k):
distance_mat[i][j] = get_dis(dataset[i], centers[j])
# 用distance_mat矩阵中的每一行最小值的下标,作为分类的标记。得到每个点的分类到的类簇,
flag = np.argmin(distance_mat, axis=1)
# 更新每个点的中心
i=0
for center in centers:
centers[center==centers]=np.mean(dataset[flag==i], axis=0)
i+=1
time += 1
return flag
def draw_result(dataset,flag):
#画出未分类前的数据
plt.subplot(121)
plt.plot(dataset[:, 0], dataset[:, 1], '*')
plt.title('Unclassified datasets')
plt.xlabel('density')
plt.ylabel('Sugar content')
#画出聚类后的数据
plt.subplot(122)
C=[]
for i in range(len(set(flag))):
C.append(dataset[(flag == i)])
for c in C :
plt.plot(c[:, 0], c[:, 1], 'o')
plt.title('Classified datasets')
plt.xlabel('density')
plt.ylabel('Sugar content')
plt.show()
###测试代码
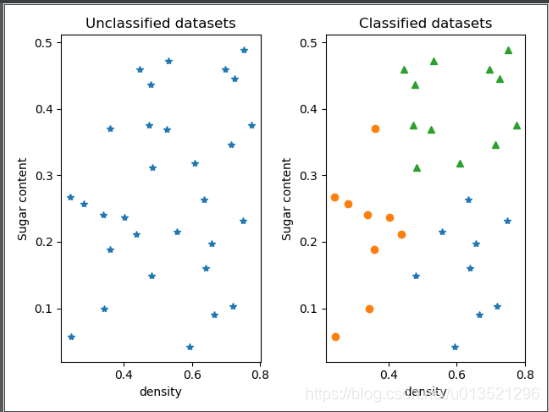
#使用西瓜书上的数据迭代4次的测试结果
dataset=np.loadtxt('data.txt')
result=k_means(dataset,3,4)
draw_result(dataset,result)
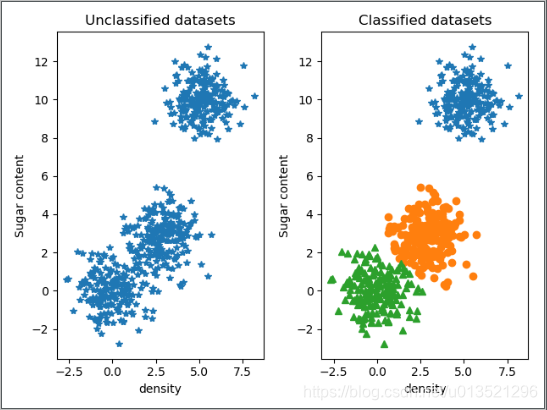
#使用自己生成的数据进行测试
s1=np.random.normal(0,1,(200,2))
s2=np.random.normal(0,1,(200,2))+np.array([3,3])
s3=np.random.normal(0,1,(200,2))+np.array([5,10])
dataset=np.vstack((s1,s2,s3))
result=k_means(dataset,3,30)
draw_result(dataset,result)
3、数据集
#西瓜书上的数据集4.0
0.697 0.46
0.774 0.376
0.634 0.264
0.608 0.318
0.556 0.215
0.403 0.237
0.481 0.149
0.437 0.211
0.666 0.091
0.243 0.267
0.245 0.057
0.343 0.099
0.639 0.161
0.657 0.198
0.36 0.37
0.593 0.042
0.719 0.103
0.359 0.188
0.339 0.241
0.282 0.257
0.748 0.232
0.714 0.346
0.483 0.312
0.478 0.437
0.525 0.369
0.751 0.489
0.532 0.472
0.473 0.376
0.725 0.445
0.446 0.459
4、参考
《机器学习》 周志华


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









