







 本文介绍了使用LSTM-CNN结构、欧拉运动放大法及注意力机制进行表情放大和时空信息提取的技术。LSTM-CNN结合了时间序列分析与图像特征提取的优势;欧拉运动放大法增强视频中微妙表情变化;注意力机制提升关键帧识别效率。
本文介绍了使用LSTM-CNN结构、欧拉运动放大法及注意力机制进行表情放大和时空信息提取的技术。LSTM-CNN结合了时间序列分析与图像特征提取的优势;欧拉运动放大法增强视频中微妙表情变化;注意力机制提升关键帧识别效率。
创新点
1.使用LSTM-CNN 结构学习时间特征和动作信息
2.欧拉运动放大法作为面部表情的预处理
3.注意力机制用于在LSTM中选择关键帧
4.合并的loss
总结
表情放大:
《 Eulerian video magnification for revealing subtle changes in the world》提出了欧拉运动信息放大方法,用于揭示视频中不显眼的行为信息。上图:
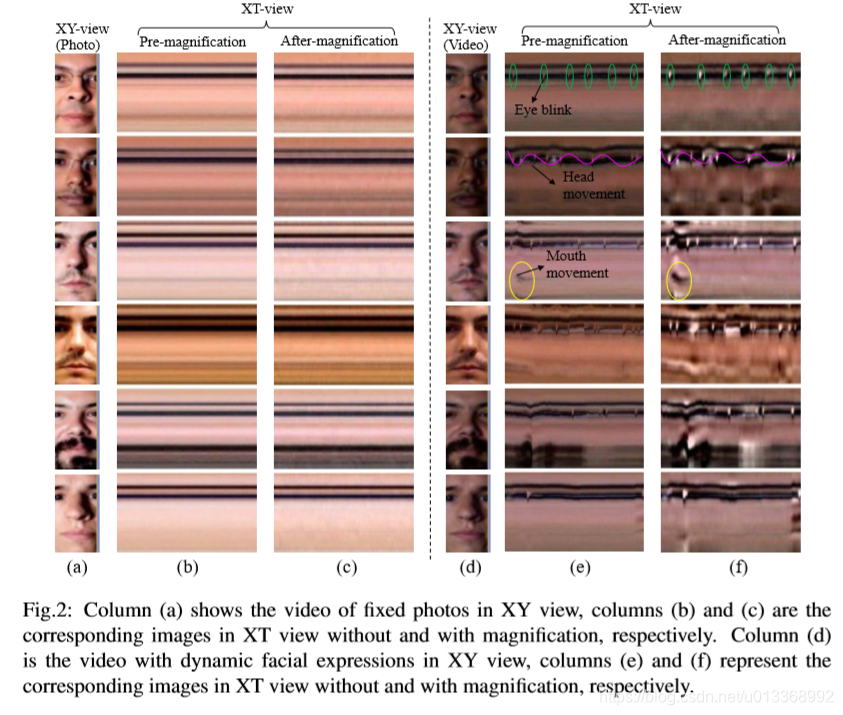
从图中可以看出,视频的表情经过处理之后变得显著。而照片中没有变化。
时空信息提取:
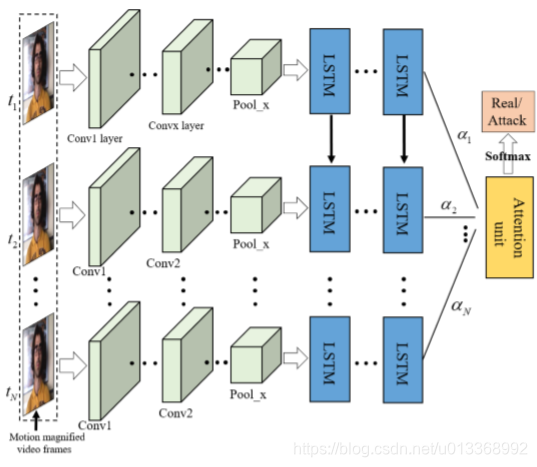
CNN+LSTM,很简单。
注意力机制:
用公式显性计算
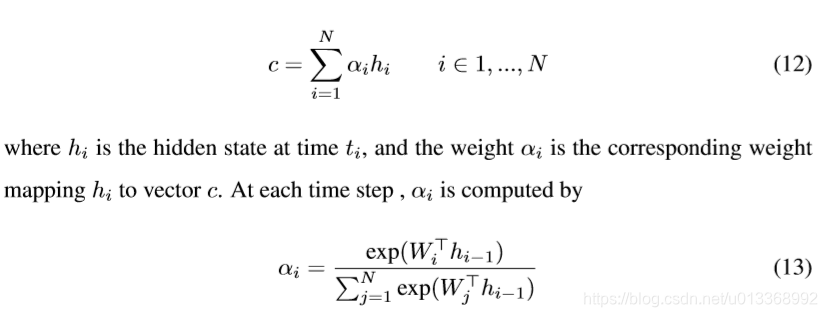
最后
欧拉行为信息放大还是蛮有趣的。
防伪以后一定是一个非常重要的方向。

















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









