







 本文介绍了如何使用Python的pdfminer3k库来读取和转换PDF文件,特别是针对文本内容。首先,你需要安装这个库,然后导入相关模块。接着,定义一个读取PDF的函数,通过这个函数可以将PDF内容转化为字符串并去除多余的空格。最后,你可以调用这个函数,传入PDF文件路径进行测试。这是一个简单有效的Python PDF处理方法。
本文介绍了如何使用Python的pdfminer3k库来读取和转换PDF文件,特别是针对文本内容。首先,你需要安装这个库,然后导入相关模块。接着,定义一个读取PDF的函数,通过这个函数可以将PDF内容转化为字符串并去除多余的空格。最后,你可以调用这个函数,传入PDF文件路径进行测试。这是一个简单有效的Python PDF处理方法。
学习python,不用再为pdf无法转换而烦恼~~~
下面我们介绍python读取pdf文件(主要是针对文字部分)
1、打开环境
2、安装pdfminer3k包
可以使用jupyter notebook进行安装,如下图所示:
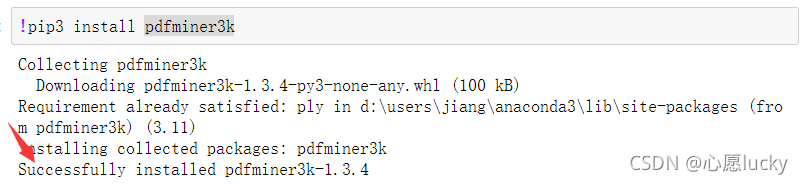
安装成功,大功告成第一步。
3、导入相关的包:
from io import StringIO
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
import re
如图:

4、定义一个读取pdf文档的函数:
def read_from_pdf(file_path):
"""
读取pdf文件
"""
with open(file_path,'rb') as file:
resource_manager = PDFResourceManager()
return_str = StringIO()
lap_params = LAParams()
device = TextConverter(resource_manager,return_str,laparams=lap_params)
process_pdf(resource_manager,device,file)
device.close()
content = return_str.getvalue()
return_str.close()
return re.sub('\s+','',content) 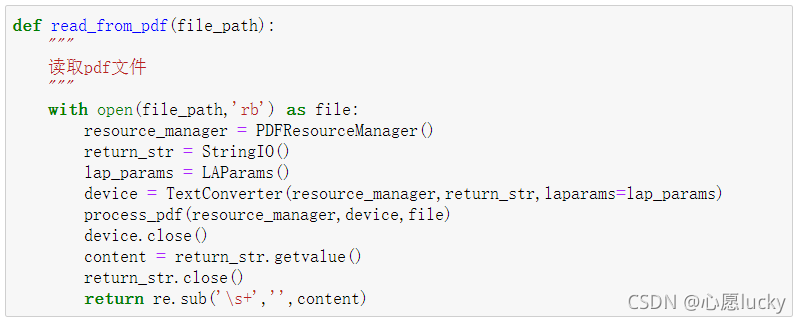
5、使用定义的函数进行测试实验:
read_from_pdf('葡萄酒数据挖掘.pdf')
根据你自己的pdf文件和具体情况进行实验,路径可以是绝对路径和相对路径,任意实验。
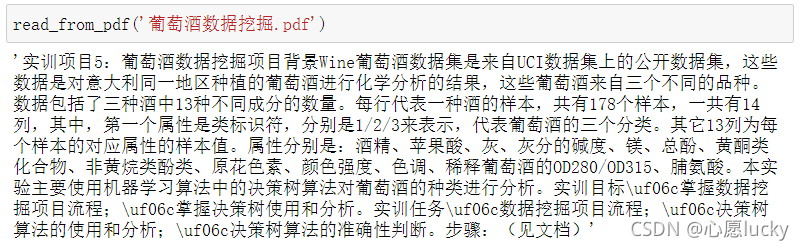
实验效果还不错,学习起来吧~~~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









