









1.简介
事件抽取是把含有事件信息的非结构化文本以结构化的形式呈现出来,在自动文摘、自动问答、信息检索等领域有着广泛的应用。近些年来 ,事件抽取一直吸引着许多研究机构和研究者的注意力。MUC (Message Understanding Conference) 会议、ACE ( Automatic Content Extraction) 会议是典型的含有事件抽取任务的评测会议。在调研中发现,ACE 2005作为论文数据集占据了主流,ACE 2005的事件抽取数据集包括英文、中文和阿拉伯语。
事件是涉及参与者的特定发生,事件是发生的事情,事件可以经常被描述为状态的改变。
ACE定义中的事件由事件触发词(Event Trigger)和描述事件结构的元素(Argument)构成。事件触发词(trigger)是能够触动事件发生的词,是决定事件类型最重要的特征词,决定了事件类别/子类别。元素用于填充事件模版,两者完整的描述了事件本身
事件抽取任务可以由下面两个步骤主要组成:
- 事件检测(Event Detection):主要是根据上下文识别出触发词以及代表的事件类型和子类型,ACE2005定义了8种事件类别以及33种子类别,每种事件类别/子类别 对应唯一的事件模版。
- 事件元素识别(Argument Detection):事件元素是指事件的参与者。根据所属的事件模版,抽取相应的元素,并为其标上正确的元素标签。
2.事件抽取任务
我们主要关注自动上下文抽取(Automatic Context Extraction,ACE)评估的事件抽取任务。ACE将事件定义为某些事情发生或者导致状态改变。使用以下术语:
(1)事件描述:一个词或者语句描述事件发生,包含一个触发词和任意数量的元素。
(2)事件触发词:能够清晰表达事件发生的主要词
(3)事件元素:实体描述、时间表达式或者事件参与者或者事件描述中带有特定角色的属性
ACE标注了8中类型和33中子类型(如Attack,Die,Start-Position)针对事件描述。每个事件子类型有自己的事件角色集,这些角色由事件元素组成。举例,Die事件的角色包括Place、Victim和Time。所有事件子类型的角色总数是36.
给定一个英文文本文档,一个事件抽取系统需要识别出每个句子中的事件子类型的事件触发词和相应的角色元素。事件元素(如实体描述、时间表达式等)会预先提供给事件抽取系统。
3.模型
W = w 1 , w 2 , … , w n W=w_1,w_2,\dots,w_n W=w1,w2,…,wn表示句子序列, n n n表示序列长度, w i w_i wi是第 i i i个单词。 E = e 1 , e 2 , … , e k E=e_1,e_2,\dots,e_k E=e1,e2,…,ek表示序列中所有的实体, k k k是实体的数量。每个实体带有头部偏移量和事件类型。进一步假设 i 1 , i 2 , … , i k i_1,i_2,\ldots,i_k i1,i2,…,ik是 e 1 , e 2 , … , e k e_1,e_2,\dots,e_k e1,e2,…,ek的最后单词的索引。
在事件抽取中,序列中每个单词 w i w_i wi需要预测出一个事件子类型。如果 w i w_i wi是感兴趣事件的触发词,我们需要预测出事件中每个实体 e j e_j ej扮演的角色。
本文中事件抽取的联合模型由两个阶段组成:
-
编码阶段:使用循环神经网络对输入序列进行表示
-
预测阶段:使用新的表示来同时进行事件触发词和元素角色的识别。
如图1所示:
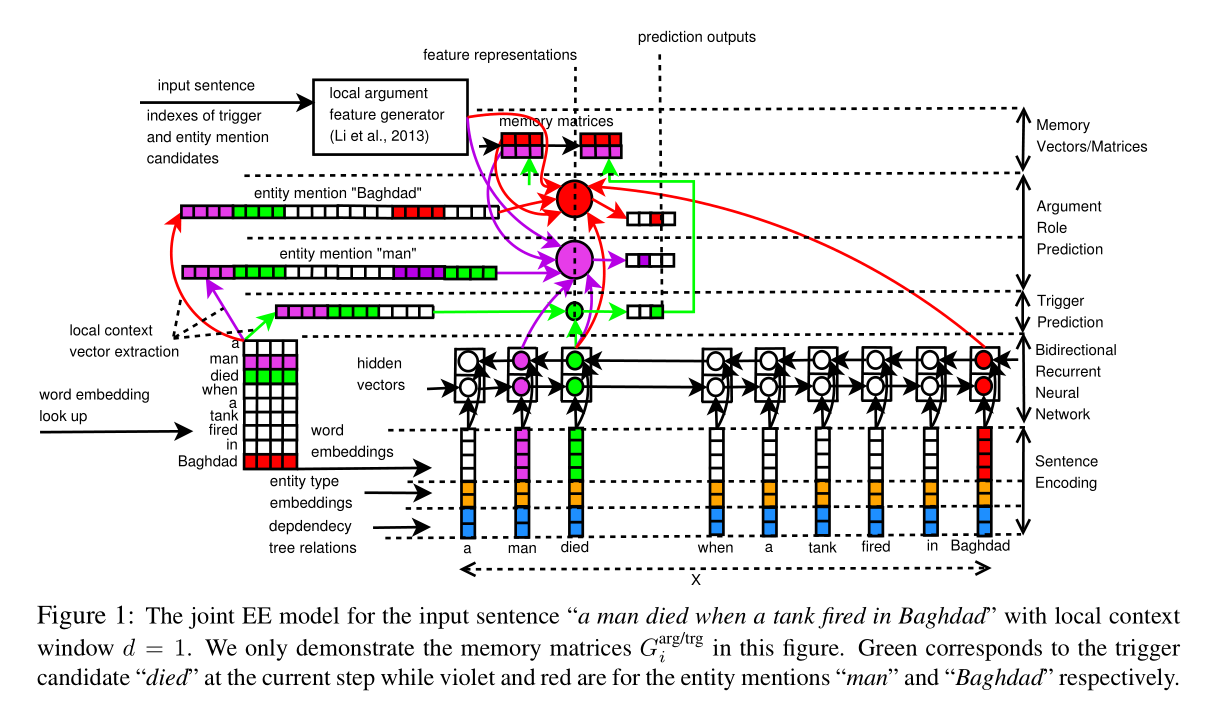
3.1 编码
3.1.1 句编码(sentence encoding)
在编码阶段,首先把每个单词 w i w_i wi转换成向量 x i x_i xi, x i x_i xi由下列三个向量拼接而成:
- w i w_i wi的词嵌入Embedding向量:使用预训练的词向量。
- w i w_i wi的事件类型的实值embedding向量。该向量参考之前的工作(Nguyen and Grishman, 2015b).通过查找实体类型embedding表获得。使用BIO标注方案为句子中每个单词赋予实体类型标签。
- 一种二进制向量,其维数对应于依赖树中单词之间可能的关系。只有在W的依赖树中存在与 w i w_i wi相对应的关系的一条边时,该向量在每维上的值才设为1。这个向量表示依赖特征,这在之前的研究中已经显示是有帮助的。
不同于之前的神经网络在EE上的研究(Nguyen and Grishman, 2015b; Chen et al.,
2015),这里不使用相对位置特征。理由是对于触发器和事件元素,我们联合预测整个句子,因此在句子中没有固定的位置用于anchoring。
从单词 w i w_i wi到 x i x_i xi的转换本质上就是把输入序列 W W W转换成实值向量序列 X = ( x 1 , x 2 , … , x n ) X=(x_1,x_2,\ldots,x_n) X=(x1,x2,…,xn),从而可以被循环神经网络利用来学习一个更有效的表示。
3.1.2 RNN(Recurrent Netural Networks)
考虑输入序列 X = ( x 1 , x 2 , … , x n ) X=(x_1,x_2,\ldots,x_n) X=(x1,x2,…,xn),在每个时间步 i i i,我们基于当前的输入向量 x i x_i xi和前一个隐藏向量向量 α i − 1 \alpha _{i-1} αi−1计算当前隐藏向量 α i \alpha _i αi,使用非线性转换函数计算: Φ : α i = Φ ( x i , α i − 1 ) \Phi : \alpha _i=\Phi(x_i,\alpha_{i-1}) Φ:αi=Φ(xi,αi−1).对整个 X X X进行该计算以产生隐藏向量序列 α 1 , α 2 , … , α n \alpha _1,\alpha _2,\ldots,\alpha _n α1,α2,…,αn,表示为$\overrightarrow {RNN}(x_1,x_2,\ldots,x_n)=(\alpha _1,\alpha_2,\ldots,\alpha_n) $
循环机制的一个重要特性是能够自适应地把位置1到 i i i的上下文信息累加到隐藏向量 α i \alpha _i αi,使得 α i \alpha _i αi具有丰富的表示。然而, α i \alpha _i αi不足以预测位置 i i i事件触发器和事件元素,因为预测还依赖于未来的上下文信息(如从位置 i i i到位置 n n n)。为了解决该问题,使用另一个RNN反向从 X n X_n Xn到 X 1 X_1 X1来生成第二个隐藏向量序列: R N N ← ( x n , x n − 1 , … , x 1 ) = ( α n ‘ , α n − 1 ‘ , … , α 1 ‘ ) \overleftarrow {RNN}(x_n,x_{n-1},\ldots,x_1)=(\alpha _n^ ‘,\alpha _{n-1}^ ‘,\ldots,\alpha _1^ ‘) RNN(xn,xn−1,…,x1)=(αn‘,αn−1‘,…,α1‘)其中, α i ‘ \alpha _i^ ‘ αi‘表示从位置 n n n到 i i i的上下文信息。最后,通过合并 ( α 1 , α 2 , … , α n ) (\alpha _1,\alpha_2,\ldots,\alpha_n) (α1,α2,…,αn)和 ( α n ‘ , α n − 1 ‘ , … , α 1 ‘ ) (\alpha _n^ ‘,\alpha _{n-1}^ ‘,\ldots,\alpha _1^ ‘) (αn‘,αn−1‘,…,α1‘)得到序列 X X X的表示向量, h i = [ α i , α i ‘ ] h_i=[\alpha _i,\alpha_i ^ ‘] hi=[αi,αi‘]。
关于非线性函数,最简单的就是使用前馈神经网络,但是会存在梯度消失问题,使得训练RNN很困难。可以使用LSTM来解决该问题。在这篇论文中,我们使用LSTM的变种GRU。GRU可以达到LSTM想应的性能。
3.2 预测
每个时间步,维护一个二进制记忆向量 G i t r g G_i ^{trg} Gitrg用于预测触发器,二进制记忆矩阵 G i a r g G_i ^{arg} Giarg和 G i a r g / t r g G_i ^{arg/trg} Giarg/trg用于预测事件元素,这些向量、矩阵被初始化为0。在训练过程中进行更新。
给定 h 1 , h 2 , … , h n h_1,h_2,\ldots,h_n h1,h2,…,hn,和初始化的记忆向量/矩阵,联合预测过程循环进行n词(每个句子n个token)。在每个时间步执行下面三个步骤:
(i) 预测 w i w_i wi的触发器(trigger)
(ii)预测所有实体的事件元素角色
(iii)使用上一步的记忆向量/矩阵来计算当前时间步的记忆向量/矩阵 G i t r g , G i a r g , G i a r g / t r g G_i ^{trg},G_i ^{arg},G_i^{arg/trg} Gitrg,Giarg,Giarg/trg,预测输出。
上述过程的结果是 w i w_i wi的触发器类型 t i t_i ti,预测的元素角色 α i 1 , α i 2 , … , α i k \alpha _{i1},\alpha _{i2},\ldots,\alpha _{ik} αi1,αi2,…,αik和当前时间步的记忆向量/矩阵 G i t r g , G i a r g , G i a r g / t r g G_i ^{trg},G_i ^{arg},G_i^{arg/trg} Gitrg,Giarg,Giarg/trg。 t i t_i ti是事件子类型或者"Other"。 a i j a_{ij} aij是相对一 w i w_i wi的实体 e j e_j ej的元素角色。
3.2.1 Trigger预测
对于trigger的预测,首先计算 w i w_i wi特征表示向量 R i t r g R_i ^{trg} Ritrg,使用下面三个向量的合并结果:
-
h i h_i hi
-
L i t r g L_i ^{trg} Litrg: L i t r g = [ D [ w i − d ] , … , D [ w i ] , … , D [ w i + d ] ] L^{trg}_i = [D[w_{i-d}],…,D[w_{i}],…,D[w_{i+d}]] Litrg=[D[wi−d],…,D[wi],…,D[wi+d]]是 w i w_i wi 跟它上下文的 embedding,就是 Word2Vec 得到的那个拼到一起;
-
G i − 1 t r g G^{trg}_{i-1} Gi−1trg:前一步的记忆向量
R i t r g = [ h i , L i t r g , G i − 1 t r g ] R_i^{trg} = [h_i,L^{trg}_i,G^{trg}_{i-1}] Ritrg=[hi,Litrg,Gi−1trg]
得到特征向量 R i t r g R_i^{trg} Ritrg之后,再把一句话的 $n $个特征向量过一层全连接网络、过一层 softmax,就得到每个 token $w_i $是 t 这种类型的 trigger 的概率分布 P i ; t t r g P^{trg}_{i;t} Pi;ttrg,每个 type 都选概率最大的,就得到了 trigger 及 event type 的预测。训练过程是 event type t 作为标签,有监督训练。这篇文章用的是 mini-batch SGD。
3.2.2 事件元素角色预测
首先,对于 token w i w_i wi,如果它的 event type 是 others(不是 trigger),那么可以直接把 a i 1 , … , a i k a_{i1},…,a_{ik} ai1,…,aik 也全都设成 others。否则,就开始在句子里,遍历每个 entity$ e_1,…,e_k 。 对 于 每 个 实 体 。对于每个实体 。对于每个实体e_j$,使用下列步骤来预测元素角色:
首先,生成 e j e_j ej关于 w i w_i wi特征表示向量 R i j a r g = [ h i , h i j , L i j a r g , B i j , G i − 1 a r g [ j ] , G i − 1 a r g / t r g [ j ] ] R_{ij}^{arg} = [h_i,h_{ij},L_{ij}^{arg},B_{ij},G_{i-1}^{arg}[j],G_{i-1}^{arg/trg}[j]] Rijarg=[hi,hij,Lijarg,Bij,Gi−1arg[j],Gi−1arg/trg[j]]:
-
h i h_i hi是编码时得到的整句话关于$ w_i 的 编 码 , 的编码, 的编码,h_{ij}$是编码时得到的整句话关于 $e_j $的编码;
-
L i j a r g = [ D [ w i − d ] , … , D [ w i ] , … , D [ w i + d ] , D [ w i j − d ] , … , D [ w i j ] , … , D [ w i j + d ] ] L_{ij}^{arg}= [D[w_{i-d}],…,D[w_{i}],…,D[w_{i+d}],D[w_{i_j-d}],…,D[w_{i_j}],…,D[w_{i_j+d}]] Lijarg=[D[wi−d],…,D[wi],…,D[wi+d],D[wij−d],…,D[wij],…,D[wij+d]]是 w i w_i wi跟它上下文的embedding,以及 e j e_j ej 跟它上下文的 embedding 全部拼一起;
-
B i j B_{ij} Bij是 V i j V_{ij} Vij过一层神经网络的结果(为了“further abstraction”,我理解就是降维、密集),这个 V i j V_{ij} Vij 是 [1] 中提出的,是一个长度为 8 的 binary 向量
-
G i − 1 a r g [ j ] G_{i-1}^{arg}[j] Gi−1arg[j]和 G i − 1 a r g / t r g [ j ] G_{i-1}^{arg/trg}[j] Gi−1arg/trg[j]是上一步的记忆矩阵 G i − 1 a r g [ j ] G_{i-1}^{arg}[j] Gi−1arg[j]和 G i − 1 a r g / t r g [ j ] G_{i-1}^{arg/trg}[j] Gi−1arg/trg[j]关于 e j e_j ej的那一行。
第二步,使用前馈神经网络和softmax把 R i j a r g R_{ij}^{arg} Rijarg转为概率分布 P i j ; a t r g P_{ij;a}^{trg} Pij;atrg,概率最大的就是元素的角色。
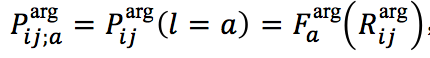
其中 a 为一种事件元素角色,最终获得对于 w i w_i wi和 e j e_j ej的事件元素角色预测结果 a i j = a r g m a x a ( p i j ; a a r g ) a_{ij}=argmax_a(p_{ij;a}^{arg}) aij=argmaxa(pij;aarg)。若 e j e_j ej并非我们关注的角色,则将 e j e_j ej赋值为"Other"。
3.2.3记忆向量/矩阵
事件抽取的一个重要特性是在同一个句子中事件触发器标签和事件元素角色之间存在依赖。本文提出使用记忆向量矩阵 G i t r g 、 G i a r g 、 G i a r g / t r g G_i^{trg}、G_i^{arg}、G_i^{arg/trg} Gitrg、Giarg、Giarg/trg来编码事件触发器和事件元素角色之间的依赖关系,并使用它们来预测事件触发词和角色。
-
记忆向量 G i t r g G_i ^{trg} Gitrg:编码事件触发词子类型之间的依赖
G i t r g ∈ { 0 , 1 } n T , i = 0 , 1 , … , n , n T G_i ^{trg } \in \{0,1\} ^{n_T},i=0,1,\ldots,n,n_T Gitrg∈{0,1}nT,i=0,1,…,n,nT是所有可能的触发词子类型的数目,该向量的更新策略为:
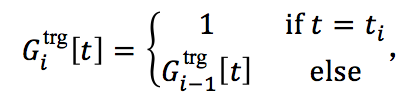
即若 w_i 的触发词子类型被预测为 $t_i $,则对应维度置为1,否则不做更改。这个记忆向量“记住”了到第 $i $步为止,有哪些触发词子类型被预测。
-
记忆矩阵 G i a r g G_i ^{arg} Giarg:编码事件元素角色之间的依赖
G i a r g ∈ { 0 , 1 } k × n A G_i ^{arg} \in \{0,1\}^{k \times n_A} Giarg∈{0,1}k×nA,其中 i=0,⋯, n 是本句中所有事件提及的数目, n A n_A nA 是所有可能的论元角色的数目,该矩阵的更新策略为
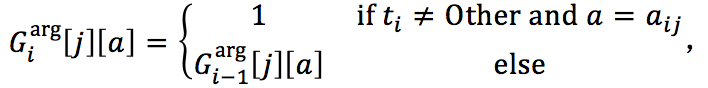
即若被 $w_i $预测为是事件触发词,且 $e_j 关 于 关于 关于 w_i 的 论 元 角 色 被 预 测 为 的论元角色被预测为 的论元角色被预测为a_{ij}$,则将矩阵中对应实体提及的 $e_j 行 和 论 元 角 色 行和论元角色 行和论元角色 a_ij $的列置为1,否则不做更改。这个记忆矩阵“记住”了到第 $i $步针对 w i w_i wi 和 e j e_j ej 的论元角色预测为止,有哪些实体提及已经被预测成了哪些论元角色。
-
记忆矩阵 G i a r g / t r g G_i ^{arg/trg} Giarg/trg:编码事件元素角色和事件触发词子类型之间的依赖
G i a r g / t r g ∈ { 0 , 1 } k × n T G_i^{arg/trg} \in \{0,1\} ^{k \times n_T} Giarg/trg∈{0,1}k×nT其中 i=0,⋯, n,更新策略为:
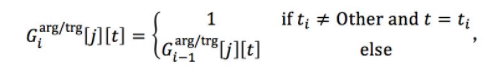
即若 $w_i $被预测为是事件触发词且其子类型为 $t_i , 则 将 矩 阵 对 应 实 体 提 及 ,则将矩阵对应实体提及 ,则将矩阵对应实体提及 e_j$ 的行和触发词子类型 $t-I $的列置为1,否则不做更改。这个记忆矩阵“记住”了到第 $i $步针对 $w_i $和 $e_j $的论元角色预测为止,有哪些论元角色和触发词子类型被预测。
3.3 训练
训练过程使用log似然函数作为损失函数,使用mini-batch和AdaDelta update rule的随机梯度下降算法优化模型,训练时也同时优化词嵌入表和实体类型嵌入表。
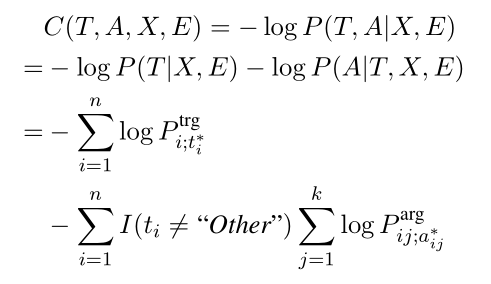
4.实验
4.1 资源、参数和数据集
- 实体类型嵌入向量维度:50
- 词向量维度:300
- RNN的隐藏神经元:300
- 上下文窗口大小:2
- 前馈神经网络中的隐藏神经元 F t r g 、 F a r g 、 F b i n a r y F^{trg}、F^{arg}、F^{binary} Ftrg、Farg、Fbinary:600、600、300
- mini-batch_size=50;Frobenius norms = 3
- 使用English Gigaword corpus预训练的词向量,其中上下文窗口大小为5,采样频率为 1 e − 05 1e-05 1e−05负采样数量为10
- 训练语料:ACE2005
4.2 记忆向量和矩阵
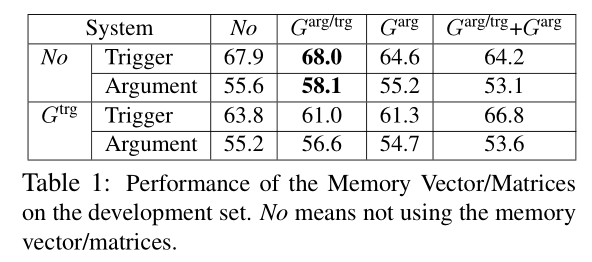
在使用C-CBOW模型预训练词嵌入表的情形下,针对三个记忆向量/矩阵 G t r g 、 G a r g 、 G a r g / t r g G^{trg}、G^{arg}、G^{arg/trg} Gtrg、Garg、Garg/trg对事件抽取的触发词预测和事件元素角色预测的效果进行了实验,有或没有每一个记忆向量/矩阵构成了总共8种情形,它们的实验结果如下表。结果显示,$G^{trg} 和 G^{arg} $的应用对结果没有提升、反而降低了,本文认为是触发词子类型间和事件元素角色间的依赖不够强,导致它们并未在此模型中起作用。而编码事件角色和触发词子类型之间依赖的 $G^{trg/arg} $的应用则显著提升了实验结果。因此在后续实验中,模型仅应用 G t r g / a r g G^{trg/arg} Gtrg/arg。
4.3 词嵌入评估
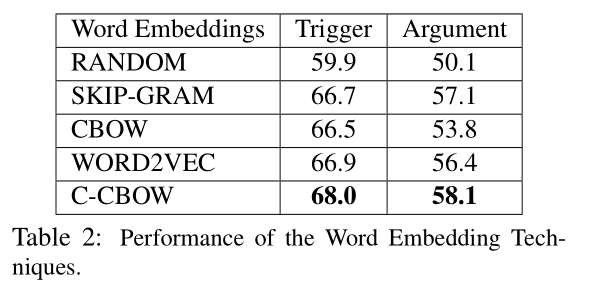
对使用不同词嵌入算法预训练词嵌入表的效果进行评估,结果如下表。其中RANDOM是随机初始化,WORD2VEC是前人工作中使用Skip-gram模型在Google News语料上训练的词嵌入表。结果显示,使用预训练词嵌入表的实验结果明显优于随机初始化,所以预训练词嵌入表对事件抽取任务有十分重大的意义。使用C-CBOW模型的效果优于其他模型,因此在后续实验中,预训练词嵌入表全部使用C-CBOW模型。
4.4 与其他SOAT模型的比较
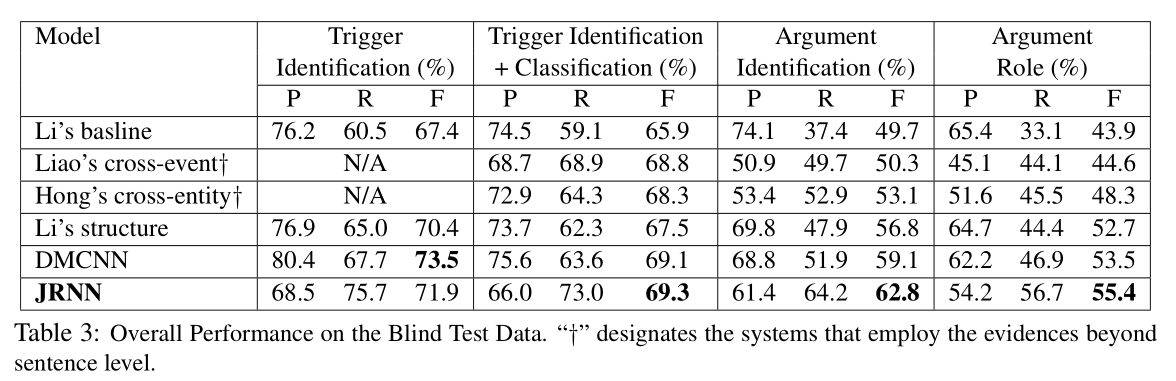
本文对比了Li’s baseline、Liao’scross-event、Hong’s cross-entity、Li’s structure、DMCNN,用JRNN指代本文所提出的模型,实验结果如下表。除了在触发词识别中略低于DMCNN模型,在其他任务中JRNN都取得了最好的效果,尤其是在事件元素检测和分类中,相比其他模型有较大的提升。实验结果证明了RNN和记忆特征在事件抽取任务中的特征表示的有效性。
4.5 一个句子包含多个事件
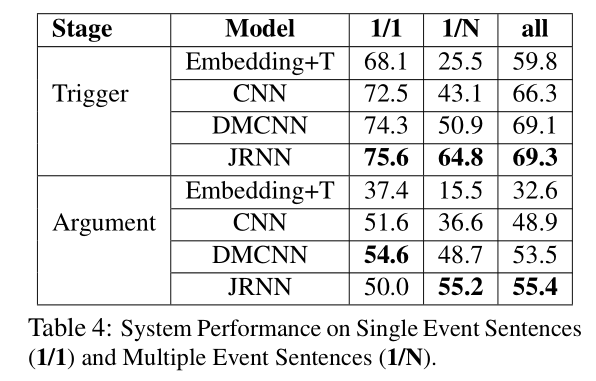
对一句话中包含多个事件的情况下的性能进行了实验验证,结果如下表所示,其中1/1代表一句中仅有一个事件,1/N代表一句中有多个事件。结果显示,在不管是一个事件还是多个事件的多数情形下,本文模型都取得了最好的性能。仅仅在事件元素预测任务中对于一个句子仅包含一个事件的情况下,性能低于DMCNN,本文认为这是因为DMCNN对于论元使用了位置嵌入特征,而本文的记忆矩阵 $G^{trg/arg} $在一个事件的情形下并未起作用。
参考
[1] 事件抽取及相关技术(1): 事件抽取及事件类型介绍 - 知乎 (zhihu.com)
[2](1条消息) 论文浅尝 | 使用循环神经网络的联合事件抽取_开放知识图谱-优快云博客


















 4113
4113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









