







 本文探讨了Write-Ahead Logging(WAL)在数据库系统中的作用,包括如何在事务提交前记录日志,以及如何利用日志进行事务回滚和数据库恢复。文章详细解释了物理日志、逻辑日志的概念,并介绍了redo、undo操作,以及如何通过检查点优化恢复过程。
本文探讨了Write-Ahead Logging(WAL)在数据库系统中的作用,包括如何在事务提交前记录日志,以及如何利用日志进行事务回滚和数据库恢复。文章详细解释了物理日志、逻辑日志的概念,并介绍了redo、undo操作,以及如何通过检查点优化恢复过程。
WAL
在BUFFER FLUSH 到disk中的database之前,必须先将相应的log写到disk的log storage中
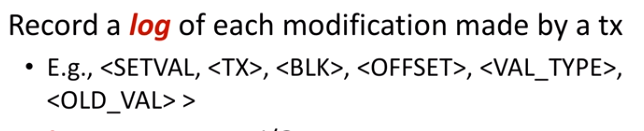

ROLLBACK之后也写一个 log记录rollback
physical logging
log 那些发生在disk的op

log records tx27

log file(多个Log 异步存入) 
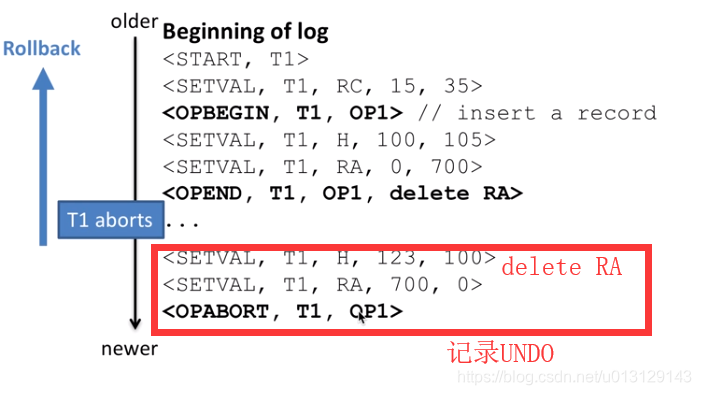
how to roll back

Recovery
恢复的是内存状态(所以恢复之后第一时间执行一次checkpoint)

how to identify incomplete tx
因为commit 和 ROLL BACK 平时都会有记录所以,找那些没有commit 和rollback的log
undo-only(没人会用了)
1,record that is a commit record then TX->list of committed
2.is rollback record tx-> list of rb
3.if record is update record and TX no in list then rollback(restore the old value to db)
(上面1.2. 在一个TX的行为记录肯定在log最后)

undo-redo

force: flush dirty block
steal:permit uncommit flush
why not just write logs.
不flush databuffer,只flush logbuffer


Make rollback faster
rollback 都No force,因为undo的时候会执行
(消耗了recovery的时间,加快了正常执行时间.,减少IO)
checkpoint(特殊的log record)
某一个时间点的dbms状态的记录,可以在recovery的时间不需要,全部log file都看完,只需要看到checkpoint
A checkpoint is like a consistent snapshot of the DBMS state
- 必须logging中所有tx 是completed之后再记录
- 然后将tx modification 都flush到disk
quiescent checkpointing
1.不允许新事务
2.等待执行中的事务完成 (会导致hang住)
3.flush all modified buffer
4.append checkpoint
5.开放新事务

但是执行checkpoint时候会hang住,可能还蛮长的
Non-quiescent checkpoint



logical logging
logical op
修改头文件,index之类的 meta-data加physical op


abort T1之后,单纯的根据physical logging 来undo的话,free space chain 会出错
所以在Logging要记录logical op

因为undo logical的时候也可能发生故障,所以也需要记录一个Undo op
logical op 会导致physical op产生联系,
(logical lock early release,指针的连接)
所以之前的算法会出现错误
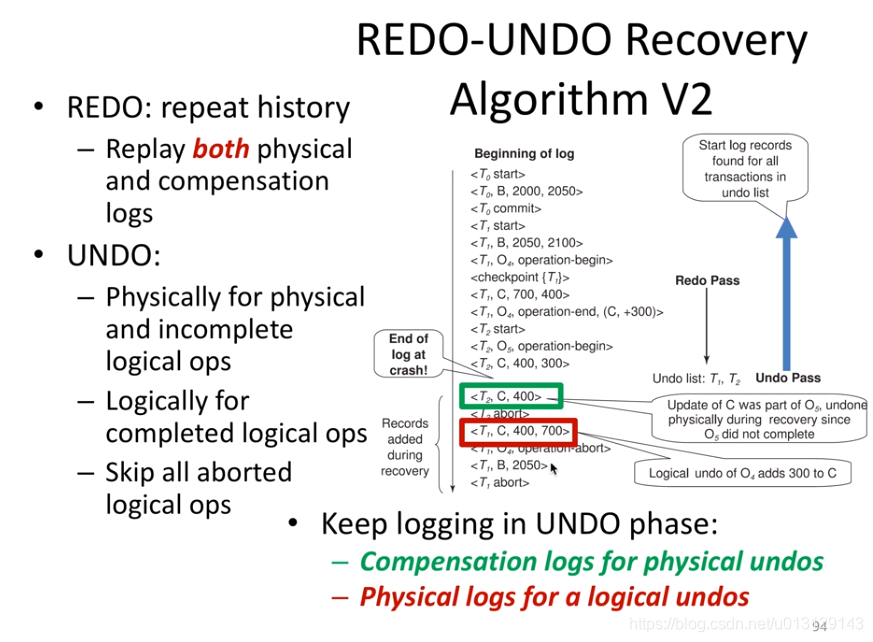
Repeating History
repeat everything .

从最后一个checkpoint scan 到 log tail
先redo(everything) 再undo(list)
已经abort的不用加入Undo list
undo的action 也要log,可以handle undo过程中发生crash
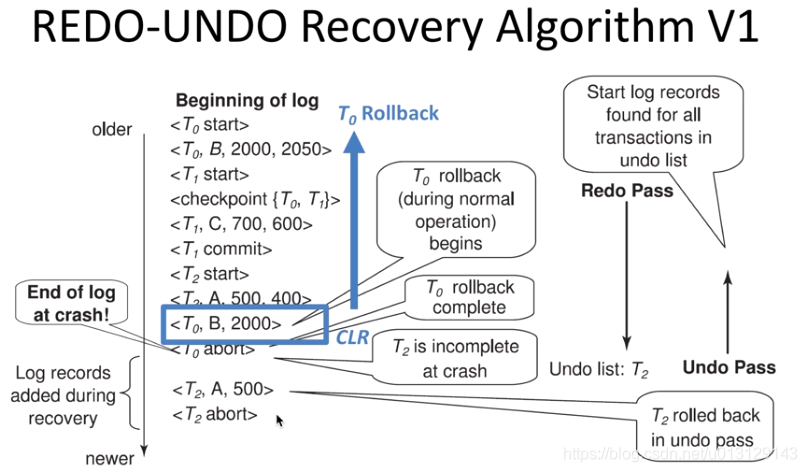
undo不做logical op(因为redo已经做了),只做logical op里的Physical op
faster checkpoint
不做FLUSH
记录两个LIST
Active tx list(就是正在做的Transaction):记录他最新的LSN
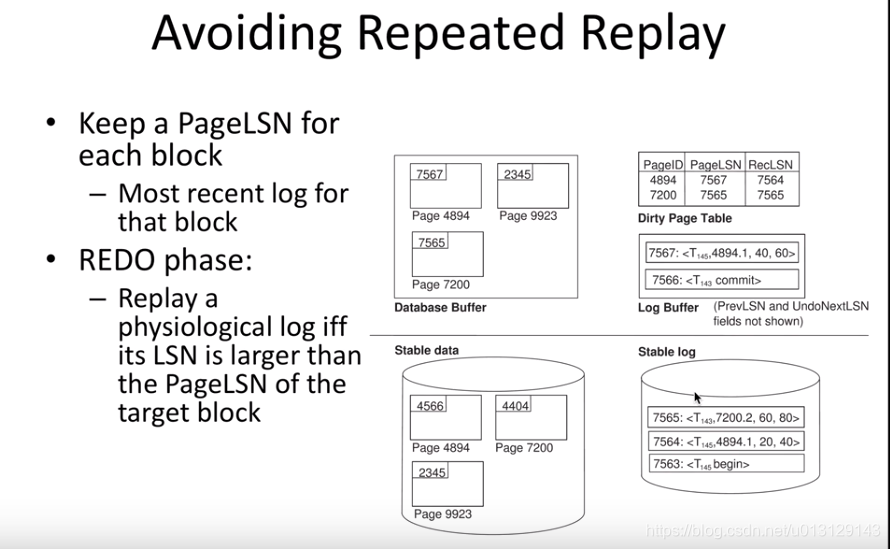
list of dirty pages(就是之前checkpoint算法需要flush的page): 记录Page id ,最新的LSN,改之前的LSN
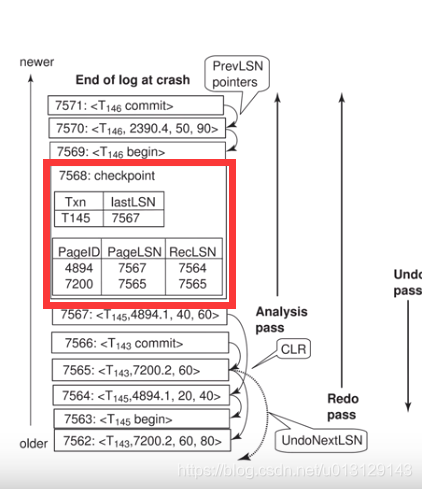
多一个Analysis phase分析redo /undo从哪里做
REDO:MIN RECLLSN
UNDO:MAX LASTLSN
faster rollback
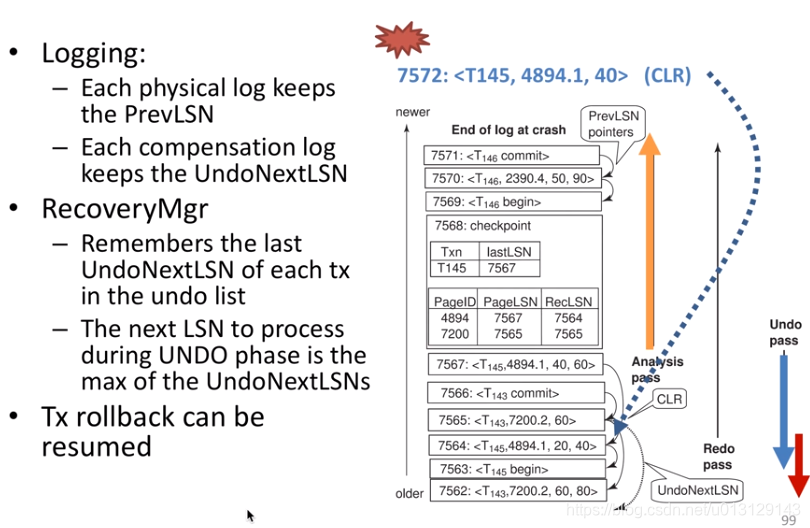
physiological logging


https://www.youtube.com/watch?v=2PEexnM83fc&list=PLlPcwHqLqJDkCOe-kJ7Zd7cXl1QoelHf-

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









