







 文章介绍了如何在Django项目中使用Haystack框架集成Elasticsearch7,并自定义分词器为ik_max_word和ik_smart。通过修改settings.py和创建自定义后端文件,实现了索引重建以及查询时的分词处理。同时,文章提及Kibana的使用,但表示其复杂,推荐直接通过代码来查看和管理索引。
文章介绍了如何在Django项目中使用Haystack框架集成Elasticsearch7,并自定义分词器为ik_max_word和ik_smart。通过修改settings.py和创建自定义后端文件,实现了索引重建以及查询时的分词处理。同时,文章提及Kibana的使用,但表示其复杂,推荐直接通过代码来查看和管理索引。
代码部分
非常简单,只要直接换成对应的引擎就行。
setting.py
HAYSTACK_CONNECTIONS = {
'default': {
# 指定引擎,需要对应版本,注意前后都有加一个7
'ENGINE': 'haystack.backends.elasticsearch7_backend.Elasticsearch7SearchEngine',
# 此处为elasticsearch运行的服务器ip地址,端口号默认为9200
'URL': 'http://192.168.119.128:9200/',
# 指定elasticsearch建立的索引库的名称 不加会报错
'INDEX_NAME': 'mr_doc',
}
}
重建索引,输出如下:
(venv) root@fjcbircubuntu:/home/cbirc/MrDoc# python3 manage.py rebuild_index
WARNING: This will irreparably remove EVERYTHING from your search index in connection 'default'.
Your choices after this are to restore from backups or rebuild via the `rebuild_index` command.
Are you sure you wish to continue? [y/N] y
Removing all documents from your index because you said so.
/home/cbirc/MrDoc/venv/lib/python3.10/site-packages/elasticsearch/connection/base.py:200: ElasticsearchWarning: Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html to enable security.
warnings.warn(message, category=ElasticsearchWarning)
All documents removed.
Indexing 4 文档
/home/cbirc/MrDoc/venv/lib/python3.10/site-packages/elasticsearch/connection/base.py:200: ElasticsearchWarning: The [edgeNGram] tokenizer name is deprecated and will be removed in a future version. Please change the tokenizer name to [edge_ngram] instead.
warnings.warn(message, category=ElasticsearchWarning)
/home/cbirc/MrDoc/venv/lib/python3.10/site-packages/elasticsearch/connection/base.py:200: ElasticsearchWarning: The [nGram] tokenizer name is deprecated and will be removed in a future version. Please change the tokenizer name to [ngram] instead.
warnings.warn(message, category=ElasticsearchWarning)
/home/cbirc/MrDoc/venv/lib/python3.10/site-packages/elasticsearch/connection/base.py:200: ElasticsearchWarning: [types removal] Specifying types in bulk requests is deprecated.
warnings.warn(message, category=ElasticsearchWarning)
使用ik分词器进行分词
新建一个文件elasticsearch7_ik_backend.py
from haystack.backends.elasticsearch7_backend import Elasticsearch7SearchBackend, Elasticsearch7SearchEngine
"""
分析器主要有两种情况会被使用:
第一种是插入文档时,将text类型的字段做分词然后插入倒排索引,
第二种就是在查询时,先对要查询的text类型的输入做分词,再去倒排索引搜索
如果想要让 索引 和 查询 时使用不同的分词器,ElasticSearch也是能支持的,只需要在字段上加上search_analyzer参数
在索引时,只会去看字段有没有定义analyzer,有定义的话就用定义的,没定义就用ES预设的
在查询时,会先去看字段有没有定义search_analyzer,如果没有定义,就去看有没有analyzer,再没有定义,才会去使用ES预设的
"""
DEFAULT_FIELD_MAPPING = {
"type": "text",
"analyzer": "ik_max_word",
# "analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
class Elasticsearc7IkSearchBackend(Elasticsearch7SearchBackend):
def __init__(self, *args, **kwargs):
self.DEFAULT_SETTINGS['settings']['analysis']['analyzer']['ik_analyzer'] = {
"type": "custom",
# "tokenizer": "ik_max_word",
"tokenizer": "ik_smart",
}
super(Elasticsearc7IkSearchBackend, self).__init__(*args, **kwargs)
class Elasticsearch7IkSearchEngine(Elasticsearch7SearchEngine):
backend = Elasticsearc7IkSearchBackend
我把文件放在这个路径下面
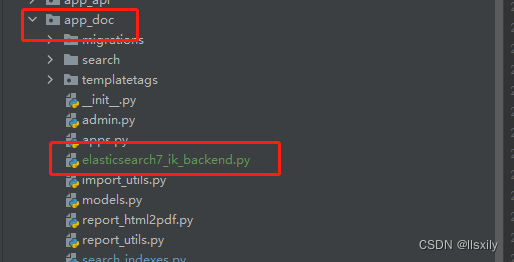
所以我的setting文件要对应改成:
# es 7.x配置
HAYSTACK_CONNECTIONS = {
'default': {
# 'ENGINE': 'haystack.backends.elasticsearch7_backend.Elasticsearch7SearchEngine',
'ENGINE': 'app_doc.elasticsearch7_ik_backend.Elasticsearch7IkSearchEngine',
'URL': 'http://127.0.0.1:9200/',
# elasticsearch建立的索引库的名称,一般使用项目名作为索引库
'INDEX_NAME': 'mr_doc',
},
}
PS:kibana太复杂了,不会用,就不太推荐了
用kibana查看索引
先设置索引库
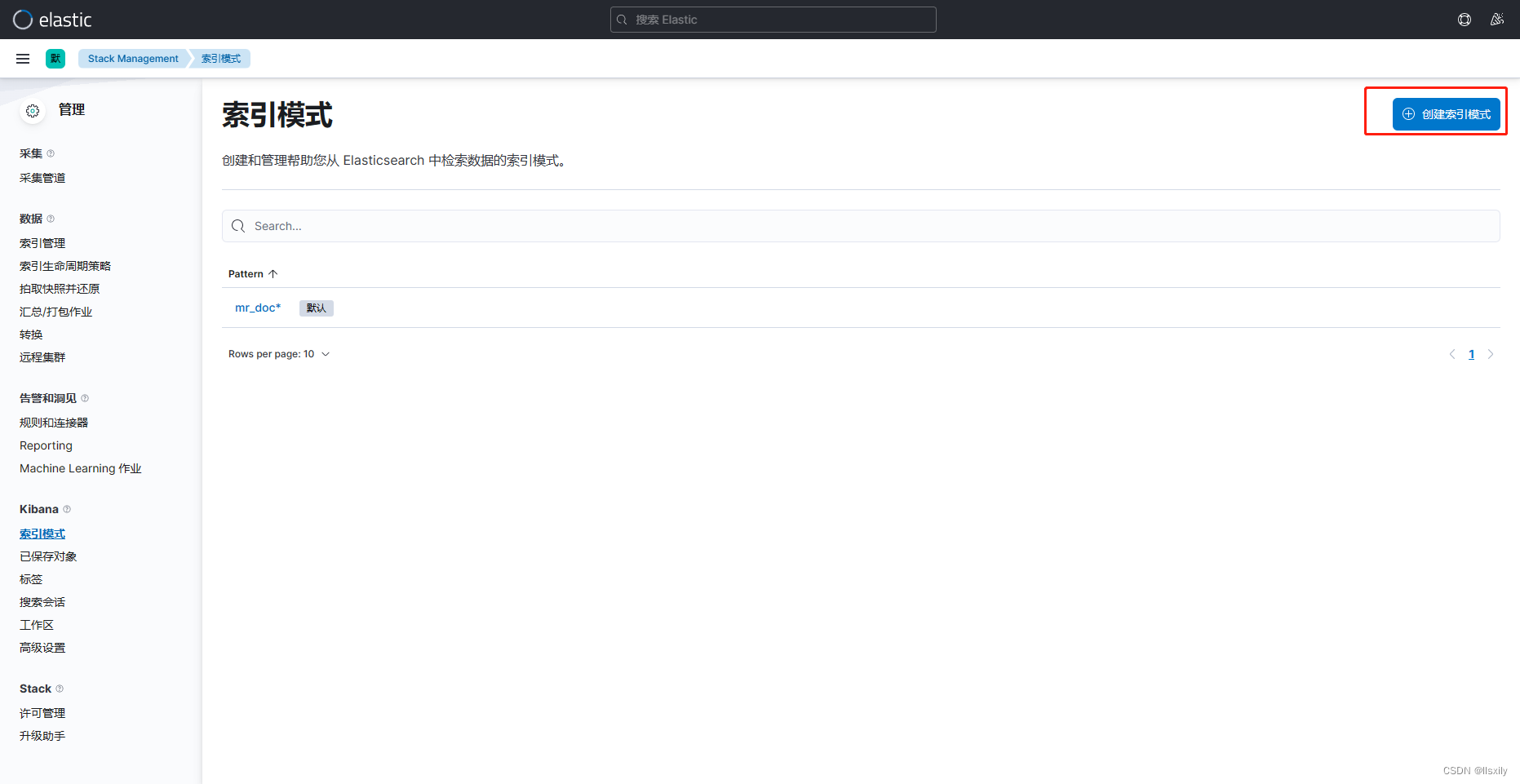
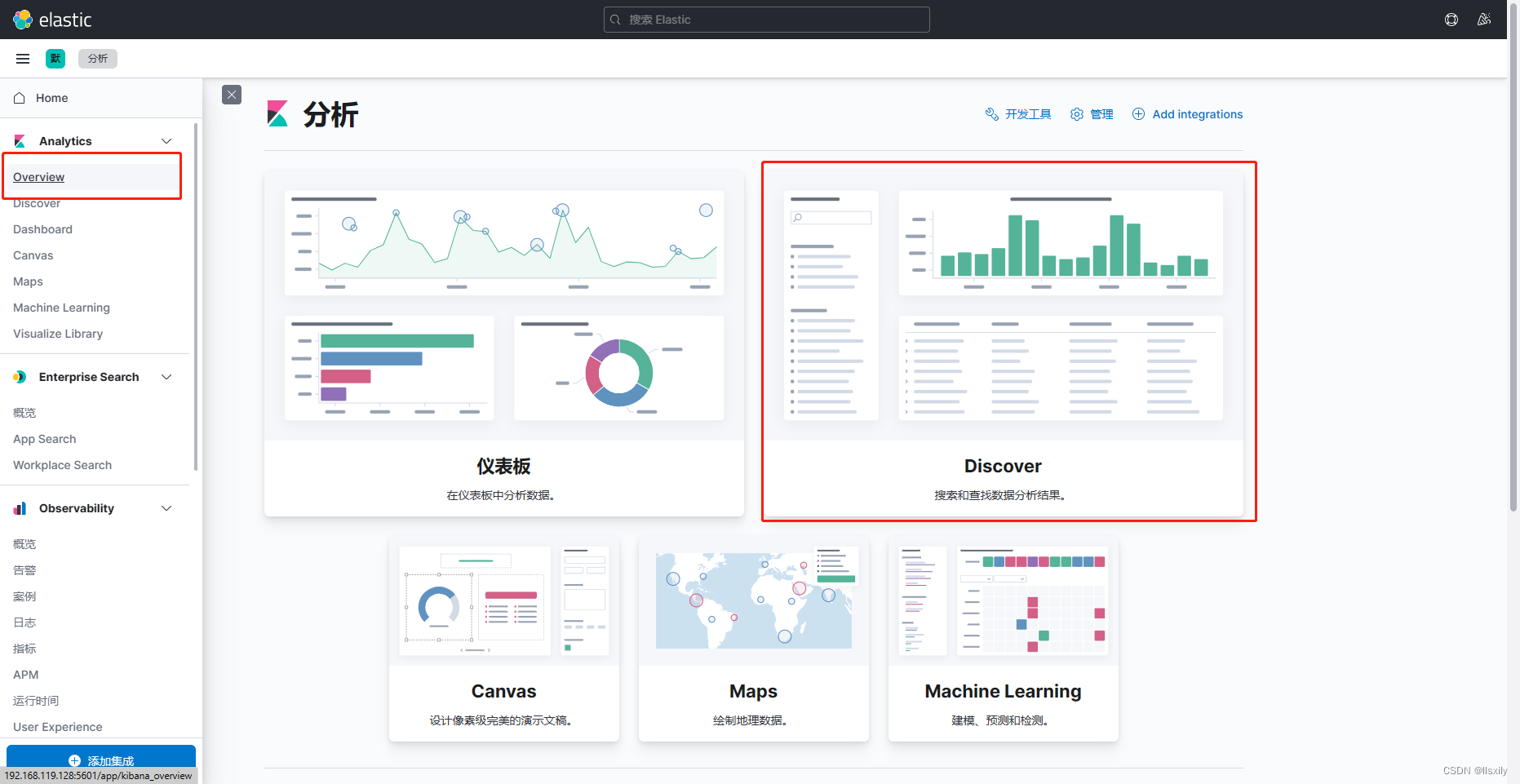
可以在搜索页搜索数据

如果没有的话可以看看时间设置。
确定查询无误就可以进到代码的部分


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









