







#博学谷IT学习技术支持#
Sink扩展: 三种消息语义
流式数据处理步骤
针对任何流式应用处理框架(Storm、SparkStreaming、StructuredStreaming和Flink等)处理数据时,都要考虑语义,任意流式系统处理流式数据三个步骤:
1、Receiving the data:接收数据源端的数据
采用接收器或其他方式从数据源接收数据(The data is received from sources using Receivers or otherwise)。
2、Transforming the data:转换数据,进行处理分析
针对StructuredStreaming来说就是Stream DataFrame(The received data is transformed using DStream and RDD transformations)。
3、Pushing out the data:将结果数据输出
最终分析结果数据推送到外部存储系统,比如文件系统HDFS、数据库等(The final transformed data is pushed out to external systems like file systems, databases, dashboards, etc)。
三种语义:
在处理数据时,往往需要保证数据处理一致性语义:从数据源端接收数据,经过数据处理分析,到最终数据输出仅被处理一次,是最理想最好的状态。在Streaming数据处理分析中,需要考虑数据是否被处理及被处理次数,称为消费语义,
1、At most once:最多一次,可能出现不消费,数据丢失;
2、At least once:至少一次,数据至少消费一次,可能出现多次消费数据;
3、Exactly once:精确一次,数据当且仅当消费一次,不多不少。
Structured Streaming的Extracly-Once
Structured Streaming的核心设计理念和目标之一:支持一次且仅一次Extracly-Once的语义。
为了实现这个目标,Structured Streaming设计source、sink和execution engine来追踪计算处理的进度,这样就可以在任何一个步骤出现失败时自动重试。
1、每个Streaming source都被设计成支持offset,进而可以让Spark来追踪读取的位置;
2、对于Operations,Spark基于checkpoint和wal来持久化保存每个trigger interval内处理的offset的范围;
3、Sink被设计成可以支持在多次计算处理时保持幂等性,就是说,用同样的一批数据,无论多少次去更新sink,都会保持一致和相同的状态。
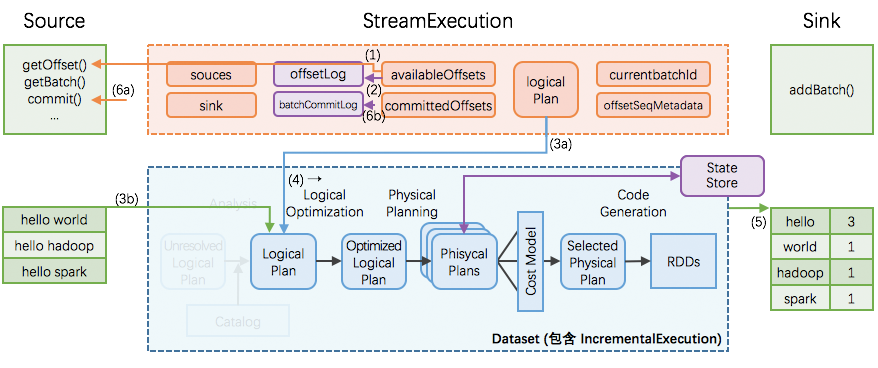
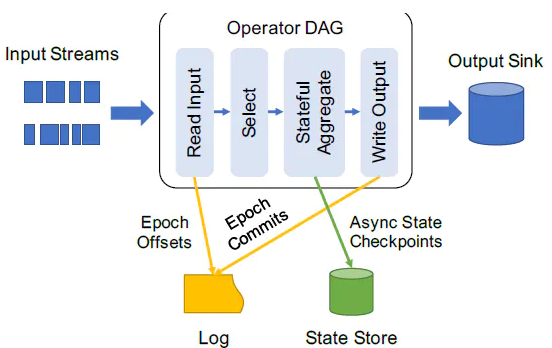
综合利用基于offset的source,基于checkpoint和wal的execution engine,以及基于幂等性的sink,可以支持完整的一次且仅一次的语义。
Source一致性语义支持:
Source |
Options |
Fault-tolerant |
Notes |
File source |
path: path to the input directory, and common to all file formats. maxFilesPerTrigger: maximum number of new files to be considered in every trigger (default: no max) latestFirst: whether to process the latest new files first, useful when there is a large backlog of files (default: false) fileNameOnly: whether to check new files based on only the filename instead of on the full path (default: false). With this set to `true`, the following files would be considered as the same file, because their filenames, "dataset.txt", are the same: "file:///dataset.txt" "s3://a/dataset.txt" "s3n://a/b/dataset.txt" "s3a://a/b/c/dataset.txt" maxFileAge: Maximum age of a file that can be found in this directory, before it is ignored. For the first batch all files will be considered valid. If latestFirst is set to `true` and maxFilesPerTrigger is set, then this parameter will be ignored, because old files that are valid, and should be processed, may be ignored. The max age is specified with respect to the timestamp of the latest file, and not the timestamp of the current system.(default: 1 week) cleanSource: option to clean up completed files after processing. Available options are "archive", "delete", "off". If the option is not provided, the default value is "off". When "archive" is provided, additional option sourceArchiveDir must be provided as well. The value of "sourceArchiveDir" must not match with source pattern in depth (the number of directories from the root directory), where the depth is minimum of depth on both paths. This will ensure archived files are never included as new source files. For example, suppose you provide '/hello?/spark/*' as source pattern, '/hello1/spark/archive/dir' cannot be used as the value of "sourceArchiveDir", as '/hello?/spark/*' and '/hello1/spark/archive' will be matched. '/hello1/spark' cannot be also used as the value of "sourceArchiveDir", as '/hello?/spark' and '/hello1/spark' will be matched. '/archived/here' would be OK as it doesn't match. Spark will move source files respecting their own path. For example, if the path of source file is /a/b/dataset.txt and the path of archive directory is /archived/here, file will be moved to /archived/here/a/b/dataset.txt. NOTE: Both archiving (via moving) or deleting completed files will introduce overhead (slow down, even if it's happening in separate thread) in each micro-batch, so you need to understand the cost for each operation in your file system before enabling this option. On the other hand, enabling this option will reduce the cost to list source files which can be an expensive operation. Number of threads used in completed file cleaner can be configured with spark.sql.streaming.fileSource.cleaner.numThreads (default: 1). NOTE 2: The source path should not be used from multiple sources or queries when enabling this option. Similarly, you must ensure the source path doesn't match to any files in output directory of file stream sink. NOTE 3: Both delete and move actions are best effort. Failing to delete or move files will not fail the streaming query. Spark may not clean up some source files in some circumstances - e.g. the application doesn't shut down gracefully, too many files are queued to clean up. For file-format-specific options, see the related methods in DataStreamReader (Scala/Java/Python/R). E.g. for "parquet" format options see DataStreamReader.parquet(). In addition, there are session configurations that affect certain file-formats. See the SQL Programming Guide for more details. E.g., for "parquet", see Parquet configuration section. |
Yes |
Supports glob paths, but does not support multiple comma-separated paths/globs. |
Socket Source |
host: host to connect to, must be specified port: port to connect to, must be specified |
No |
|
Rate Source |
rowsPerSecond (e.g. 100, default: 1): How many rows should be generated per second. rampUpTime (e.g. 5s, default: 0s): How long to ramp up before the generating speed becomes rowsPerSecond. Using finer granularities than seconds will be truncated to integer seconds. numPartitions (e.g. 10, default: Spark's default parallelism): The partition number for the generated rows. The source will try its best to reach rowsPerSecond, but the query may be resource constrained, and numPartitions can be tweaked to help reach the desired speed. |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









