







1.论文汇总
Yolov3论文名:《Yolov3: An Incremental Improvement》
Yolov3论文地址:https://arxiv.org/pdf/1804.02767.pdf
2.YoloV3核心基础内容
2.1 网络结构可视化
Yolov3是目标检测Yolo系列非常非常经典的算法,不过很多同学拿到Yolov3或者Yolov4的cfg文件时,并不知道如何直观的可视化查看网络结构。如果纯粹看cfg里面的内容,肯定会一脸懵逼。
其实可以很方便的用netron查看Yolov3的网络结构图,一目了然。
这里不多说,如果需要安装,可以移步大白的另一篇文章:《网络可视化工具netron详细安装流程》。
如果不想安装,也可以直接点击此链接,查看Yolov3可视化流程图。
2.2 网络结构图
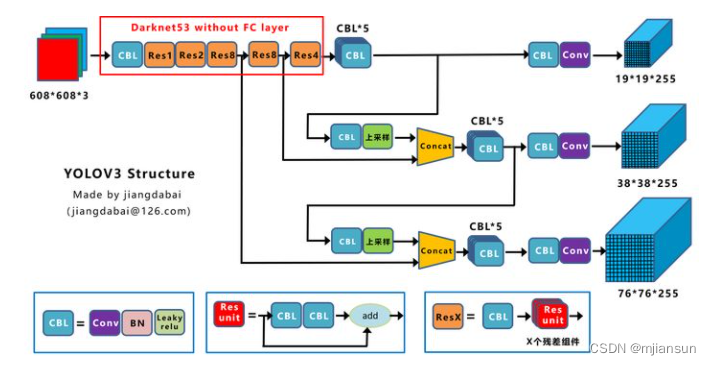
绘制网络结构图受到Yolov3另一位作者文章的启发,确实,从总体框架上先了解了Yolov3的流程。再针对去学习每一小块的知识点,会事半功倍。
上图三个蓝色方框内表示Yolov3的三个基本组件:
- CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
- Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
- ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
其他基础操作:
- Concat:张量拼接,会扩充两个张量的维度,例如26*26*256和26*26*512两个张量拼接,结果是26*26*768。Concat和cfg文件中的route功能一样。
- add:张量相加,张量直接相加,不会扩充维度,例如104*104*128和104*104*128相加,结果还是104*104*128。add和cfg文件中的shortcut功能一样。
Backbone中卷积层的数量:
每个ResX中包含1+2*X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,不过为了方便称呼,仍然把Yolov3的主干网络叫做Darknet53结构。
2.3 核心基础内容
Yolov3是2018年发明提出的,这成为了目标检测one-stage中非常经典的算法,主要相较于V2(V2中已经包含有anchorbox、kmeans聚框等)的创新点为:
(1)网络更深,使用了Darknet-53网络结构,为避免梯度消失使用的Resnet shortcut连接
(2)融合了FPN
(3)不在使用soft max损失函数而是使用sigmod+交叉熵函数,从而可以支持多标签的预测
这里大白也准备了Yolov3算法非常浅显易懂的基础视频课程,让小白也能简单清楚的了解Yolov3的整个过程及各个算法细节。
Yolov3及Yolov4深入浅出系列视频:点击查看。
在准备课程过程中,大白搜集查看了网络上几乎所有的Yolov3资料,在此整理几个非常不错的文章及视频,大家也可以点击查看,学习相关知识。
(1)视频:吴恩达目标检测Yolo入门讲解
https://www.bilibili.com/video/BV1N4411J7Y6?from=search&seid=18074481568368507115
(2)文章:Yolo系列之Yolov3【深度解析】
https://blog.youkuaiyun.com/leviopku/article/details/82660381
(3)文章:一文看懂Yolov3
https://blog.youkuaiyun.com/litt1e/article/details/88907542
相信大家看完,对于Yolov3的基础知识点会有一定的了解。
3.YoloV3相关代码
3.1 python代码
代码地址:https://github.com/ultralytics/Yolov3
3.2 C++代码
这里推荐Yolov4作者的darknetAB代码,代码和原始作者代码相比,进行了很多的优化,如需要运行Yolov3网络,加载cfg时,使用Yolov3.cfg即可
代码地址:https://github.com/AlexeyAB/darknet
3.3 python版本的Tensorrt代码
除了算法研究外,实际项目中还需要将算法落地部署到工程上使用,比如GPU服务器使用时还需要对模型进行tensorrt加速。
(1)Tensort中的加速案例
强烈推荐tensort软件中,自带的Yolov3加速案例,路径位于tensorrt解压文件夹的TensortX/samples/python/Yolov3_onnx中
针对案例中的代码,如果有不明白的,也可参照下方文章上的详细说明:
代码地址:https://www.cnblogs.com/shouhuxianjian/p/10550262.html
(2)Github上的tensorrt加速
除了tensorrt软件中的代码, github上也有其他作者的开源代码
代码地址:https://github.com/lewes6369/TensorRT-Yolov3
3.4 C++版本的Tensorrt代码
项目的工程部署上,如果使用C++版本进行Tensorrt加速,一方面可以参照Alexey的github代码,另一方面也可以参照下面其他作者的开源代码
代码地址:https://github.com/wang-xinyu/tensorrtx/tree/master/Yolov3

















 1977
1977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









