




文章目录
1.redis数据结构
Redis 提供了丰富的数据结构,每种结构都有其特定的用途和优势。以下是 Redis 支持的主要数据结构:
1.1.字符串(String)
- 特点:最基本的数据类型,二进制安全,最大512MB
- 常用命令:
SET key value/GET keyINCR key/DECR key(原子计数器)APPEND key valueSTRLEN key
- 应用场景:
- 缓存简单数据
- 计数器
- 分布式锁
1.2. 哈希(Hash)
- 特点:键值对集合,适合存储对象
- 常用命令:
HSET key field valueHGET key fieldHGETALL keyHDEL key field
- 应用场景:
- 存储用户信息等对象数据
- 商品属性存储
1.3. 列表(List)
- 特点:有序、可重复的字符串集合,双向链表实现
- 常用命令:
LPUSH key value/RPUSH key valueLPOP key/RPOP keyLRANGE key start stopLLEN key
- 应用场景:
- 消息队列
- 最新消息排行
- 记录日志
1.4. 集合(Set)
- 特点:无序、唯一的字符串集合
- 常用命令:
SADD key memberSMEMBERS keySISMEMBER key memberSINTER key1 key2(交集)
- 应用场景:
- 标签系统
- 共同好友
- 去重操作
1.5. 有序集合(Sorted Set / ZSet)
- 特点:有序、唯一的字符串集合,每个元素关联一个分数(score)
- 常用命令:
ZADD key score memberZRANGE key start stop [WITHSCORES]ZREVRANGE key start stop(逆序)ZRANK key member(获取排名)
- 应用场景:
- 排行榜
- 带权重的消息队列
- 范围查询
1.6. 位图(Bitmap)
- 特点:通过字符串实现的位操作
- 常用命令:
SETBIT key offset valueGETBIT key offsetBITCOUNT keyBITOP operation destkey key [key ...]
- 应用场景:
- 用户签到
- 活跃用户统计
- 布隆过滤器实现
1.7. HyperLogLog
- 特点:用于基数统计的算法,误差率约0.81%
- 常用命令:
PFADD key element [element ...]PFCOUNT key [key ...]PFMERGE destkey sourcekey [sourcekey ...]
- 应用场景:
- UV统计
- 大规模去重计数
1.8. 地理空间(Geospatial)
- 特点:存储地理位置信息
- 常用命令:
GEOADD key longitude latitude memberGEODIST key member1 member2 [unit]GEORADIUS key longitude latitude radius unit
- 应用场景:
- 附近的人
- 地理位置计算
1.9. 流(Stream)
- 特点:Redis 5.0引入,类似日志的数据结构
- 常用命令:
XADD key ID field value [field value ...]XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]XGROUP CREATE key groupname ID
- 应用场景:
- 消息队列
- 事件溯源
选择数据结构的原则
- 根据数据特征选择:是否需要排序、去重等
- 考虑操作复杂度:不同数据结构操作的时间复杂度不同
- 内存效率:不同结构的内存使用效率不同
- 扩展性:未来可能的查询需求变化
Redis 的强大之处在于这些数据结构的高效实现和丰富的操作命令,合理选择数据结构可以极大提升系统性能和开发效率。
2.redis使用的场景有哪些?
redis 使用场景:
- 缓存(穿透、击穿、雪崩,双写一直,持久化,数据过期,淘汰策略)
- 分布式锁(setnx,redisson)
- 计数器(incr 命令实现)
- 保存token(string)
- 消息队列(list)
- 延迟队列(zset)
其它:
- 集群(主从、哨兵、集群)
- 事务
- redis 为什么这么快?
我看你做的项目中,都用到了redis,你在最近的项目中哪些场景使用了redis呢?
** 结合项目 **
- 一是验证你的项目场景的真实性,二是为了作为深入发问的切入点(根据自己简历上的业务进行回答)
- 缓存 (缓存三兄弟(穿透、击穿、雪崩)、双写一致、持久化、数据过期策略、数据淘汰策略)
- 分布式锁 (setnx、redisson)
- 消息队列、延迟队列 (何种数据类型)
标易行项目redis内存中放哪些数据
redis 内存中放哪些数据?
3.什么是缓存穿透?
例:
一个get请求:api/news/getById/1

**缓存穿透:**查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库(导致数据库并发并不高,请求到达一定量会击垮数据库)
**解决方案一:**缓存空数据,如果mysql查询的数据结果为空,仍把这个空结果进行缓存(如查询key为1的null 数据,则在redis中缓存{key:1, value:null})
**优点:**简单
**缺点:**消耗内存,可能会发生数据不一致的问题
为什么会发生数据不一致问题?
比如一开始数据库中没有key=1的数据,redis缓存空数据(key:1,value:null),后面往数据库中添加key=1的数据时,用户过来查询还是查到了redis 的空数据,由此产生redis和数据库数据不一致的问题。
例:
一个get请求:api/news/getById/1
注意:一些热点数据添加到缓存数据库同时(缓存预热),也要添加到布隆过滤器中

**解决方案二:**布隆过滤器
**优点:**没有多余key,所以内存占用较少
**缺点:**实现复杂,存在误判
布隆过滤器
**bitmap(位图):**相当于是一个以(bit)位为单位的数组,数组中每个单元只能存储二进制数0或1
**布隆过滤器作用:**布隆过滤器可以用于检索一个元素是否在一个集合中。
基本概念
1.bit(位,又名“比特”):bit的缩写是b,是计算机中的最小教据单位(属于二进制的范畴,其实就是0或者1)
2.Bvte(字节):Byte的缩写是B,是计算机文件大小的基本计算单位,比如一个字符就是 1Byte 如果是汉字,则是2 Byte,1B(字节)=8b(位)

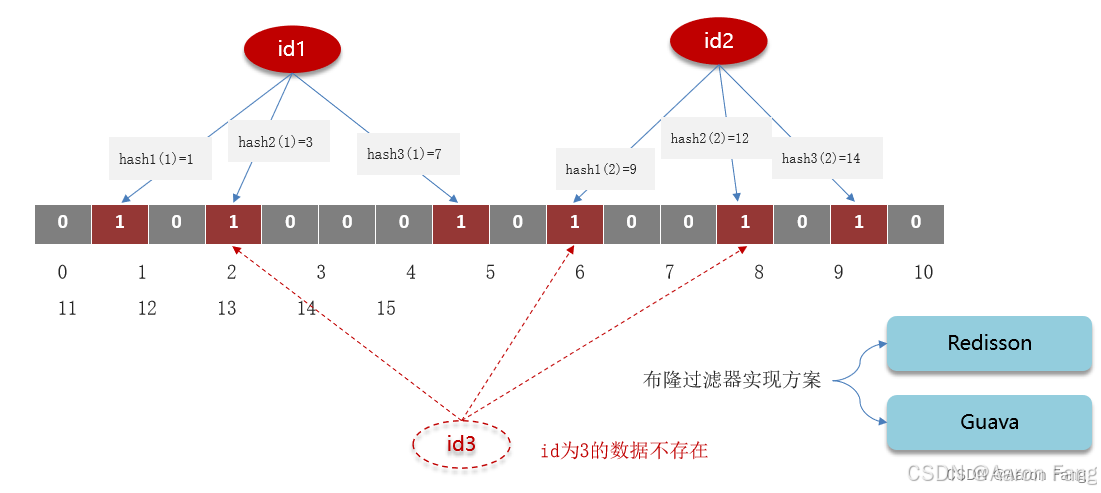
为什么存在误判?
假设id=1的数据,通过多个hash函数,获取多个hash值,假如这个值分别为1、3、7,需要把对应数组上由0改为1,假设id=2的数据按照上面方法也获取多个hash值,分别为9、12、14,也把对应的数组上的0改为1。现在查询id=3,通过多个hash函数计算,值为3、9、12,虽然数组中没有id=3的数据,但还是返回查询成功,这个就是误判**。降低误判需要增大数组,增大数组的长度会增大内存的消耗,一般项目内设置5%的误判率,不至于高并发压倒数据库。**
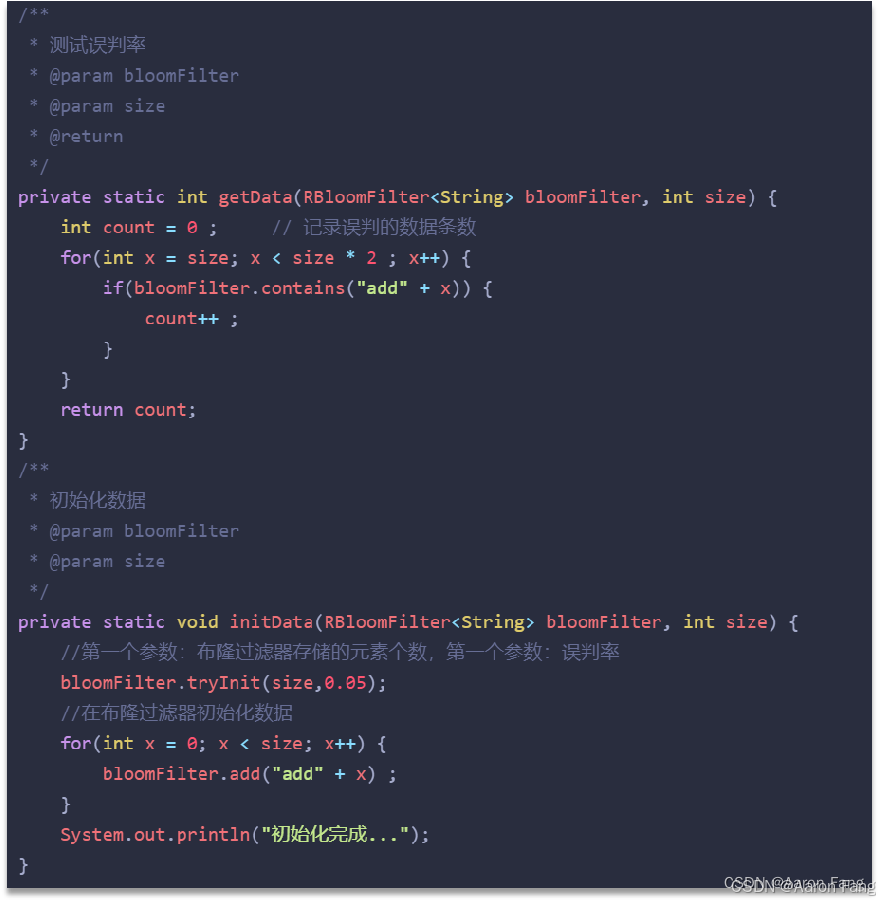
什么是缓存穿透,怎么解决
- 缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
- 解决方案一:缓存空数据
- 解决方案二:布隆过滤器
面试参考回答:
**缓存穿透:**查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
- 解决方案一:缓存空数据
- 优点:简单
- 缺点:消耗内存,可能会发生数据不一致的问题
- 解决方案二:布隆过滤器
- 优点:内存占用较少,没有多余key
- 缺点:实现复杂,存在误判
面试官:什么是缓存穿透 ? 怎么解决 ?
候选人:嗯~~,我想一下,缓存穿透是指查询一个一定不存在的数据,如果从存储层(如mysql)查不到数据则不写入缓存,这将导致这个不存在的数据请求每次都要到 DB 去查询,可能导致 DB 挂掉。这种情况大概率是遭到了攻击。解决方案的话,我们通常都会用布隆过滤器来解决它
面试官:好的,你能介绍一下布隆过滤器吗?
候选人:嗯,是这样~布隆过滤器主要是用于检索一个元素是否在一个集合中。我们当时使用的是redisson实现的布隆过滤器。
它的底层主要是先去初始化一个比较大数组,里面存放的二进制0或1。在一开始都是0,当一个key来了之后经过3次hash计算,模于数组长度找到数据的下标然后把数组中原来的0改为1,这样的话,三个数组的位置就能标明一个key的存在。查找的过程也是一样的。
当然是有缺点的,布隆过滤器有可能会产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%,其实这个误判是必然存在的,要不就得增加数组的长度,5%以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。
4.什么是缓存击穿?
缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好这时间点,这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
缓存重建:当key过期,redis查询不到,去查DB,DB查询到结果,写入redis。
如果缓存重建的过程中花费50毫秒,为什么需要花费50毫秒?
有的时候存入缓存中的数据需要涉及多张表,多张表需要先分别统计后汇总结果,这样花费时间会更久

解决方案一:互斥锁
解决方案二:逻辑过期
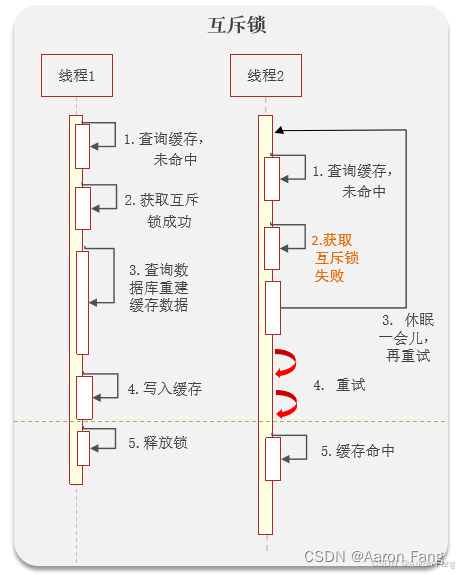
什么是互斥锁?
缺点:只能有一个线程获取锁,然后查询数据库重建缓存,其它线程只能等待,性能相对来说比较差
优点:强一致性(和钱相关的需要保持强一致)
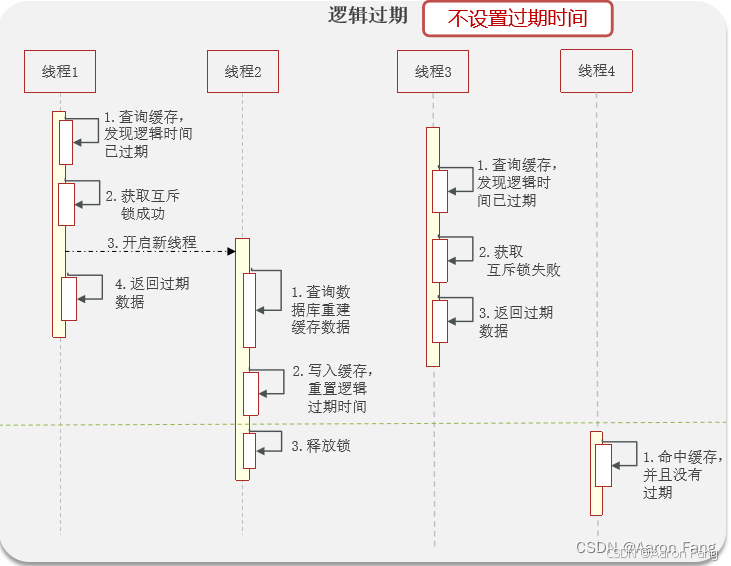
什么是逻辑过期?
热点key不在缓存中设置过期时间,如何判断当前数据是否过期?新增数据到缓存的时候,新增一个过期的时间字段
优点:高可用、性能优(注重用户体验,互联网一般选择高可用)
缺点:不能保证数据的绝对一致

缓存击穿
缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把 DB 压垮。
- 解决方案一:互斥锁,强一致,性能差
- 解决方案二:逻辑过期,高可用,性能优,不能保证数据绝对一致
面试官:什么是缓存击穿 ? 怎么解决 ?
候选人:嗯!!缓存击穿的意思是给某一个key设置了过期时间,当key在某个时间点过期的时候,恰好这时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把 DB 压垮。
解决方案有两种方式:
第一可以使用互斥锁:当缓存失效时,不立即去load db,先使用如 Redis 的 setnx 去设置一个互斥锁,当操作成功返回时再进行 load db的操作并回设缓存,否则重试get缓存(获取缓存)的方法
第二种方案可以设置当前key逻辑过期,大概是思路如下:
①:在设置key的时候,设置一个过期时间字段一块存入缓存中,不给当前key设置过期时间
②:当查询的时候,从redis取出数据后判断时间是否过期
③:如果过期则开通另外一个线程进行数据同步,当前线程正常返回数据,这个数据不是最新
当然两种方案各有利弊:
如果选择数据的强一致性,建议使用分布式锁的方案,性能上可能没那么高,锁需要等,也有可能产生死锁的问题
如果选择key的逻辑过期,则优先考虑的高可用性,性能比较高,但是数据同步这块做不到强一致。
5.什么是缓存雪崩?
缓存雪崩:是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。

解决方案:
- 给不同的Key的TTL(过期时间)添加随机值(在原有过期时间上添加随机值1-5
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3729
3729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









