







 本文通过实验对比了SQL中UNION和UNION ALL对两个结果集连接的使用效果。UNION会对重复记录去重并按查询字段列默认升序排序,性能较低;UNION ALL则直接组合记录集,不进行去重和排序。还介绍了让查询记录集按要求排序的方法。
本文通过实验对比了SQL中UNION和UNION ALL对两个结果集连接的使用效果。UNION会对重复记录去重并按查询字段列默认升序排序,性能较低;UNION ALL则直接组合记录集,不进行去重和排序。还介绍了让查询记录集按要求排序的方法。
这篇文章说一个关于ORACLE中的UNION、UNION ALL、INTERSECT、MINUS的解释和用法:
先创建一张TABLE,用来做实验:
建表语句如下所示:
create table student
(
id int primary key,
name nvarchar2(50) not null,
score number not null
);
insert into student values(1,'zhangsan',78);
insert into student values(2,'lisi',76);
insert into student values(3,'wangwu',89);
insert into student values(4,'zhaoliu',90);
insert into student values(5,'xiaohua',73);
insert into student values(6,'xiaoming',61);
insert into student values(7,'xiaoli',99);
insert into student values(8,'wangmazi',56);
insert into student values(9,'huqingniu',93);
insert into student values(10,'zhangwuji',90);
commit;
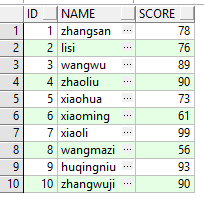
查看插入表中的所有数据:
SELECT * FROM STUDENT;
结果如下图所示:
(1)使用UNION对两个结果集进行连接,SQL如下所示,结果如下图所示
SELECT * FROM STUDENT T
WHERE T.ID<4
UNION
SELECT * FROM STUDENT T
WHERE T.ID>2 AND T.ID<6;
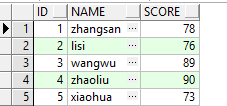
通过上图我们可以看出来,使用UNION返回了5条数据。
(2)使用UNION ALL对两个结果集连接,SQL如下所示,结果如下图所示:
SELECT * FROM STUDENT T
WHERE T.ID<4
UNION ALL
SELECT * FROM STUDENT T
WHERE T.ID>2 AND T.ID<6;
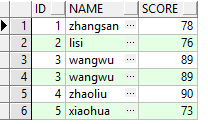
通过上图我们可以看出来,使用UNION ALL返回了6条数据,与(1)中的结果相比,多了一条ID为3的数据。
为什么会这样,我们看一下我们的SQL,我们的语句是由两部分查询结果集进行组合的,所以分别单独看一下每一部分的SQL:
第一部分:SELECT * FROM STUDENT T WHERE T.ID<4 这句SQL会返回ID小于4的记录,单独执行应该返回3条数据,ID为1,2,3的记录
第二部分:SELECT * FROM STUDENT T WHERE T.ID>2 AND T.ID<6这句SQL会返回ID大于2小于6的记录,也就是3条记录,ID为3,4,5的记录
当我们使用UNION的时候,返回的记录ID分别为1,2,3,4,5,并不是上面分析的两部分直接组合,而是将两部分中相同的记录进行了去重,只留下重复记录中的一条数据。
当我们使用UNION ALL的时候,返回的记录ID分别是1,2,3,3,4,5,是两部分的记录集直接组合,并没有对重复的记录进行去重。
所以通过上面这个例子,我们可以知道:UNION会对记录集中重复记录去重,UNION ALL不会对记录集中的重复记录去重,所以在写SQL文的时候,需要考虑到底是需要去重还是不去重,去重选择前者,不去重选择后者,当然如果选择前者的话,那么SQL性能会低于后者,因为后者只是对记录的展示,而前者需要对查询的记录集中的重复记录进行去重,多了一个步骤,所以会影响SQL的性能。
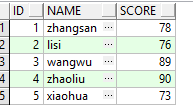
(3)对于(1)和(2)中的SQL连接顺序调整一下,原来是先筛选ID小于4的记录集连接筛选ID大于2小于6的记录集,现在我们颠倒一下,SQL如下图所示:
SELECT * FROM STUDENT T
WHERE T.ID>2 AND T.ID<6
UNION
SELECT * FROM STUDENT T
WHERE T.ID<4;
结果如图所示:
SELECT * FROM STUDENT T
WHERE T.ID>2 AND T.ID<6
UNION ALL
SELECT * FROM STUDENT T
WHERE T.ID<4;
结果如图所示:
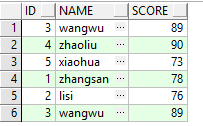
通过(3)中的第一段SQL和结果图片,可以看到返回了5条记录,但是细心点可以发现它返回的记录进行了排序,因为我们SQL写的是先筛选 ID大于2小于6的,但是结果却和我们预想的不一样;第2段SQL,返回了6条记录,按照我们预想的一样,记录集的ID是3,4,5,1,2,3,SQL是怎么写的,结果集就按照其进行输出。
通过(3),我们应该可以发现,UNION会对记录集进行排序,UNION ALL不会对记录集进行排序。
(4)从(3)中知道了使用UNION的话,会对结果集进行排序,我们从(3)中第一段SQL结果集发现是按照ID进行升序排序的,那么为什么会按照ID进行排序,我们试图修改一下SQL,再看是否还是按照ID排序:
修改后的SQL文:
SELECT T.SCORE,T.ID,T.NAME FROM STUDENT T
WHERE T.ID>2 AND T.ID<6
UNION
SELECT T.SCORE,T.ID,T.NAME FROM STUDENT T
WHERE T.ID<4;
对应的记录集如下图所示:
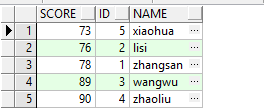
通过这个记录集,可以发现,这个查询记录是按照SCORE进行排序的,那么我们就可以认为,UNION的排序,是按照查询列的字段名字顺序排序的,比如
SELECT COLUMN1,COLUMN2,COLUMN3 FROM TABLENAME T
UNION
SELECT COLUMN1,COLUMN2,COLUMN3 FROM TABLENAME T
结果集就是按照ORDER BY COLUMN1,COLUMN2,COLUMN3进行排序的。
为了验证上面我们的说话,UNION会按照查询的列的字段名字升序排序,下面再看一个例子:
SELECT SCORE, ID, NAME
FROM STUDENT
WHERE ID > 2
UNION
SELECT SCORE, ID, NAME
FROM STUDENT
WHERE ID < 4
结果如图所示:
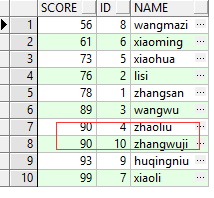
通过上图可以看出,的确是按照查询字段进行排序,当第一个排序字段值相同的时候,按照第二个字段的值进行排序,以此类推。
如果我们需要让查询记录集按照我们的要求进行排序,那么就需要在整段SQL的末尾写上ORDER BY COLUMNS,这样的话,记录集就是按照我们的要求进行排序的,测试如下:
SELECT SCORE, ID, NAME
FROM STUDENT
WHERE ID > 2
UNION
SELECT SCORE, ID, NAME
FROM STUDENT
WHERE ID < 4
ORDER BY ID DESC
运行结果如图所示:
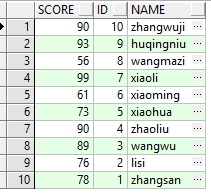
总结:
UNION会对记录集中的重复记录进行去重,并且会按照查询的字段列进行默认升序排序UNION ALL不会对记录集中的重复记录进行去重,只会将查询记录组合显示出来,也不会进行排序- 使用
UNION的记录集需要排序,可以在SQL的最末端,写ORDER BY COLUMNS,你需要排序的字段名称 Intersect对两个结果集进行交集操作,不包括重复行,同时进行默认规则的排序Minus对两个结果集进行差操作,不包括重复行,同时进行默认规则的排序




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









