






1、DiG: Scalable and Efficient Diffusion Models with Gated Linear Attention
中文标题:DiG:具有门控线性注意力的可扩展且高效的扩散模型
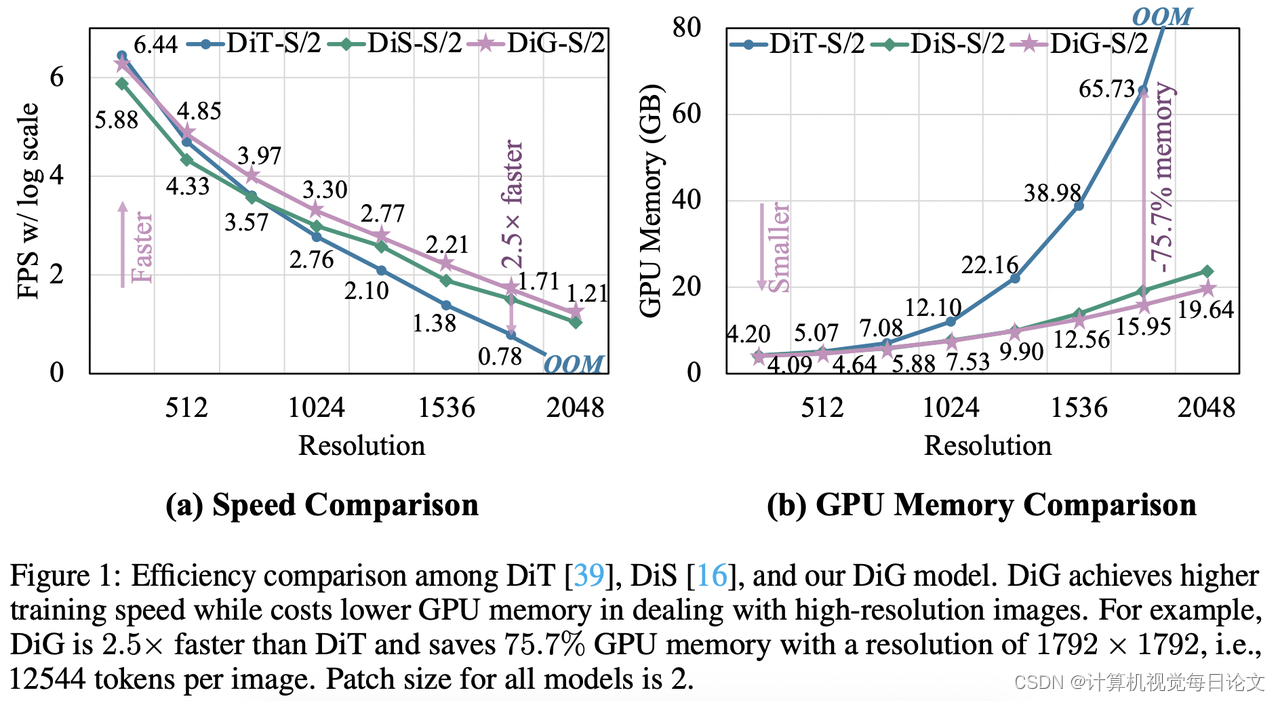

简介:大规模预训练的扩散模型在视觉内容生成领域取得了显著成功,其中Diffusion Transformers (DiT)模型尤为突出。然而,DiT模型在可扩展性和计算效率方面面临挑战。
本文提出了Diffusion Gated Linear Attention Transformers (DiG),旨在利用门控线性注意力(GLA)变压器的长序列建模能力,将其应用于扩散模型。DiG 是一种简单、可采用的解决方案,参数开销最小,遵循 DiT 设计,但提供了更高的效率和有效性。
与 DiT 相比,DiG-S/2 的训练速度快2.5倍,在1792×1792分辨率时,GPU内存使用降低了75.7%。此外,我们分析了 DiG 在各种计算复杂度下的可扩展性,结果表明通过增加深度/宽度或输入标记,DiG 模型的 FID 性能始终有所提升。
进一步的比较实验表明,在相同模型大小下,DiG-XL/2 在1024分辨率下比最近基于 Mamba 的扩散模型快4.2倍,在2048分辨率下比 CUDA 优化的 FlashAttention-2下的 DiT 快1.8倍。这些结果都证明了 DiG 在最新扩散模型中具有优越的效率。
项目代码已发布在 https://github.com/hustvl/DiG 。
2、GFlow: Recovering 4D World from Monocular Video
中文标题:GFlow:从单目视频恢复 4D 世界


简介:从单目视频中重建4D动态场景是一项关键但挑战重重的任务。传统方法通常依赖于多视角输入、已知相机参数或静态场景假设,这些在野外场景中往往缺失。
本文提出了 GFlow,这是一个新的框架,旨在在没有任何相机参数的情况下,从单目视频中恢复动态的4D世界和相机姿态。GFlow 利用2D先验(深度和光流)将视频(3D)提升到4D显式表示,包括通过空间和时间的高斯喷洒流。
首先,GFlow 将场景划分为静止和移动部分,然后应用顺序优化过程,基于2D先验和场景聚类优化相机姿态和3D高斯点的动态,确保邻近点之间的保真度和跨帧的平滑运动。由于动态场景引入了新内容,GFlow 提出了一种新的像素级稠密化策略来整合新的视觉内容。
除了4D重建,GFlow 还能够在不需要事先训练的情况下,对场景中的任何点进行跟踪,并以无监督的方式分割移动物体。此外,从 GFlow 中可以派生出每一帧的相机姿态,从而呈现视频场景的新视角。
GFlow 采用显式表示,因此可以根据需要轻松进行场景级或对象级编辑,展现了其多功能性和强大性。相关项目信息可访问 https://littlepure2333.github.io/GFlow 。
3、3DitScene: Editing Any Scene via Language-guided Disentangled Gaussian Splatting
中文标题:3DitScene:通过语言引导的解缠高斯泼溅编辑任何场景

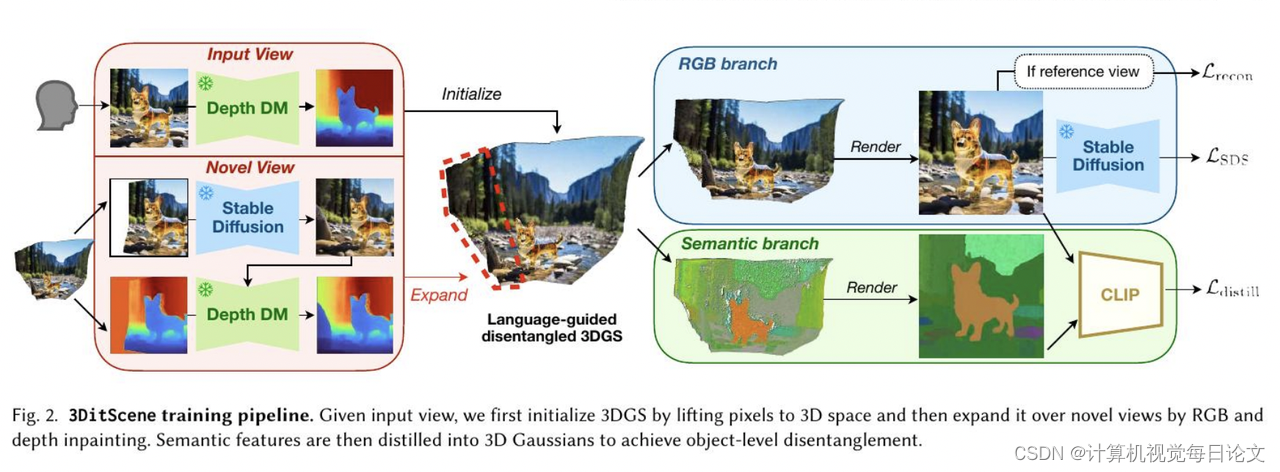
简介:场景图像编辑在娱乐、摄影和广告设计中扮演着关键角色。然而,现有方法仅专注于2D单个对象或3D全局场景编辑,缺乏一种统一的方法来有效地控制和操作具有不同粒度的3D场景。
本文提出了3DitScene,这是一个新颖的统一场景编辑框架。3DitScene 利用语言引导的分离高斯喷洒,实现了从2D到3D的无缝编辑,允许精确控制场景组合和单个对象。
首先,3DitScene 引入了通过生成先验和优化技术细化的3D高斯函数。然后,来自CLIP的语言特征将语义引入3D几何中,以进行对象分离。通过分离的高斯函数,3DitScene 允许在全局和单个级别上进行操作,彻底改变了创意表达方式,赋予了对场景和对象的控制能力。
实验结果证明了3DitScene在场景图像编辑中的有效性和通用性。相关代码和在线演示可在项目主页 https://zqh0253.github.io/3DitScene/ 上找到。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









