







Training-Free Long-Context Scaling of Large Language Models
由于训练语料库的可获取性有限,以及长上下文微调的成本过高,不需要额外训练即可进行上下文扩展的方法变得尤为吸引人
最近的无训练方法,包括LM-infinite和StreamingLLM,已经展示了在有限上下文窗口训练的LLMs能够高效处理无限长度的文本。这些模型通过选择性保留关键的局部信息来处理扩展序列,有效地维持了低困惑度(Perplexity,PPL),但它们失去了长距离依赖性。为了保留全局信息,另一种观点是有效地推断出超出训练时遇到的序列长度。一些流行的技术,如基于Llama模型的位置插值(PI)和NTK-Aware RoPE,是对旋转位置编码(RoPE)的调整。这些扩展的位置编码相比原始RoPE需要更少的微调步骤,而且它们的训练成本可以通过YaRN和CLEX等方法进一步降低。然而,在无需训练的环境中,这些方法通常会导致PPL显著增加,尤其是在输入长度是训练长度两倍以上时。
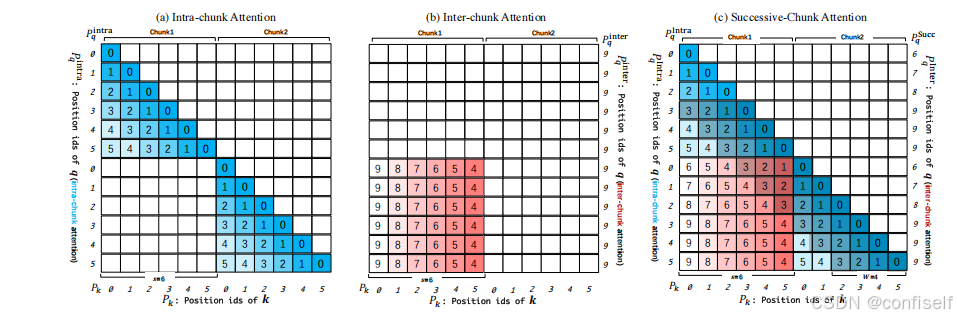
Pk、PqIntra、PqInter、PqSucc定义如下:


各位置M矩阵元素计算如下:

可视化相对位置信息如下:

代码部分:
# -*- coding:utf-8 -*-
import copy
from typing import List, Optional, Tuple, Union
from torch import nn
import math
from transformers.models.llama.modeling_llama import rotate_half, repeat_kv
from transformers.modeling_outputs import CausalLMOutputWithPast
from torch.nn import CrossEntropyLoss
import torch
import transformers
from transformers.cache_utils import Cache
# from flash_attn.flash_attn_interface import flash_attn_qkvpacked_func, flash_attn_func
class ChunkLlamaRotaryEmbedding(nn.Module):
def __init__(self, dim, max_position_embeddings=4096, base=10000, scaling_factor=1.0, device=None):
super().__init__()
self.max_seq_len = 16384
self.dim = dim
self.max_length = None
self.scaling_factor = scaling_factor
self.max_position_embeddings = max_position_embeddings
self.base = base
# Build here to make `torch.jit.trace` work.
self._set_cos_sin_cache(
seq_len=self.max_seq_len,
device=device, dtype=torch.float32
)
def _set_cos_sin_cache(self, seq_len, device, dtype):
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
# 分析:chunk_size:10, local_window 4, chunk_len 6
chunk_len = chunk_size - local_window
# 分析: q_t长度为6,[0,1,2,3,4,5]
q_t = torch.arange(chunk_len, device=device, dtype=self.inv_freq.dtype) / self.scaling_factor
# 分析: qc_t取值为6~10,长度为6, [6,7,8,9,10,10],和论文有点区别,不过不影响
qc_t &# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









